마케터를 위한 SQL
1.✨마케터를 위한 SQL : 데이터의 이해

SQL이라는 언어는 마케터와 데이터분석가에게 있어서 데이터를 추출하거나 분석을 하기 위한 좋은 수단입니다. 하지만 좋은 수단이 있더라도 목적이 명확하지 않거나, 목적을 위해 참조해야할 데이터를 올바르게 이해하지 못하면 기대했던 결과를 얻지 못하기도 합니다.
2.마케터를 위한 SQL : SQL 요소
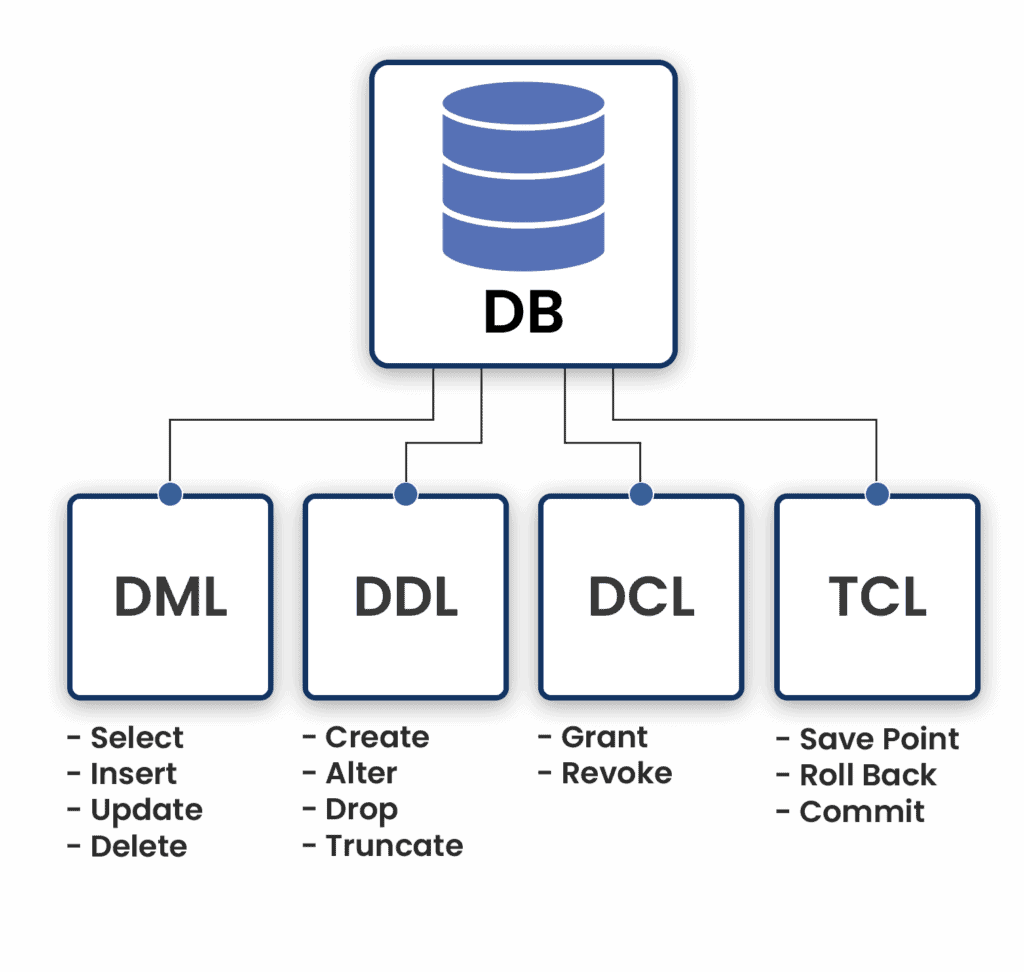
SQL은 Structured Query Language 의 약자로 직역하면 구조화된 질의어라고 할 수 있습니다. SQL은 데이터베이스(Database)에 저장된 데이터를 조건에 맞추어 원하는 형태로 추출(Retrieve)하는데 사용되는 언어입니다.
3.마케터를 위한 SQL : 연습용 데이터베이스 구축 (CREATE, INSERT)

본 블로그 시리즈는 데이터베이스 모델링이 위주가 아니다보니 향후 실습을 위해 필요한 최소의 배경과 상황 설명을 위한 모델링 내용을 담았습니다. 이번 글은 향후 진행될 SQL 연습에서 활용될 데이터베이스를 구축하는 과정입니다.
4.마케터를 위한 SQL : SELECT, FROM 구문
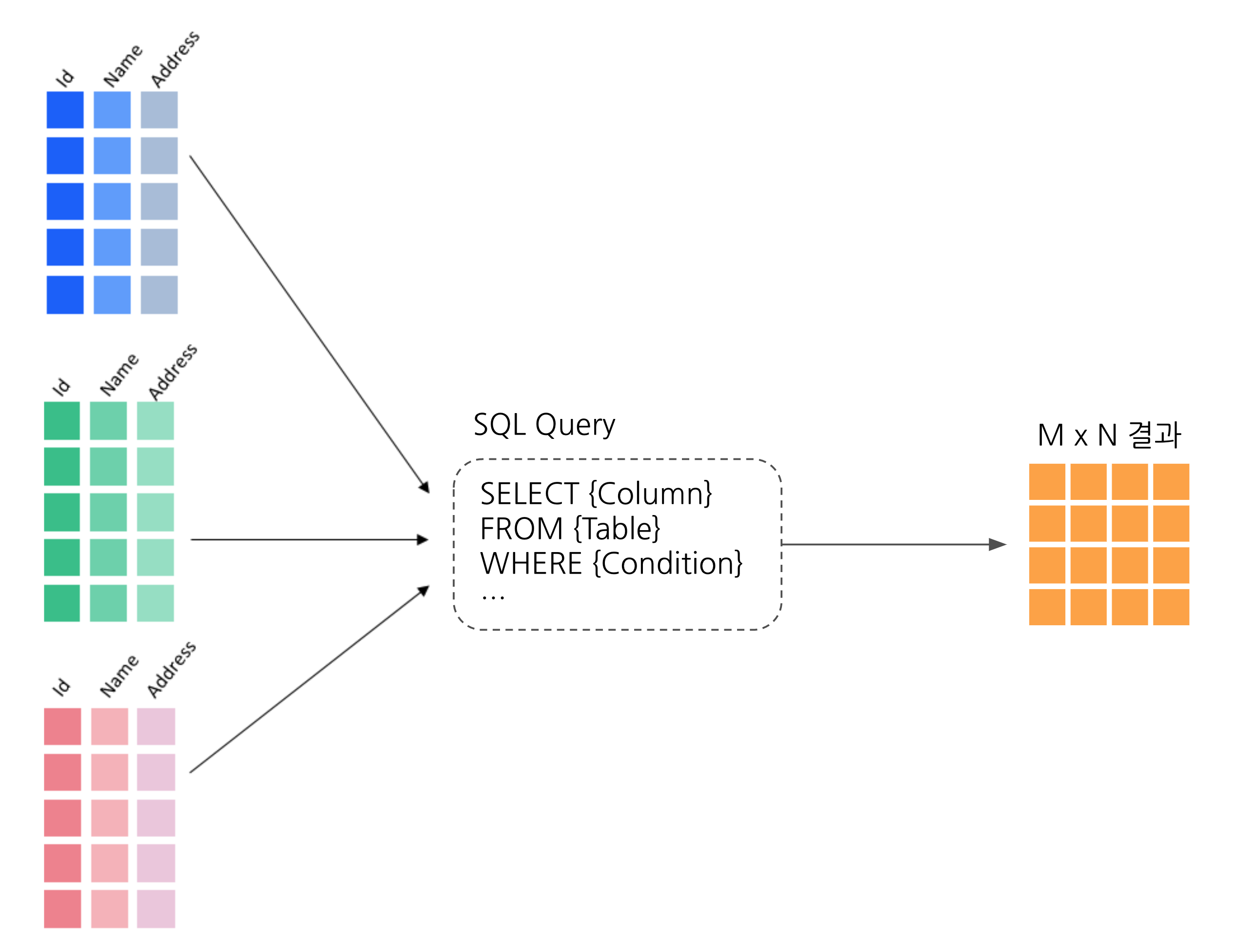
데이터베이스 안에는 여러개의 테이블이 있고, 각 테이블에는 데이터가 담겨져 있습니다. SQL의 SELECT 구문을 통해 데이터베이스의 어느 테이블에, 무슨 컬럼들을 몇개 가져와서 어떻게 값들을 처리하고 그 결과를 n x m 테이블로 표현할 수 있습니다.
5.마케터를 위한 SQL : WHERE 절을 통한 조건부 쿼리 (연산자)
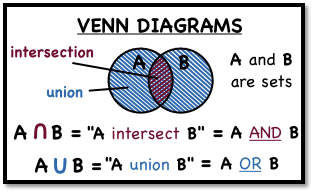
필터(Filter)가 적용된 데이터 즉, 조건에 맞는 일부의 레코드만 선택하는 WHERE절을 추가하는 방법을 알아보도록 하겠습니다.
6.마케터를 위한 SQL : 중간 정리 (SELECT, FROM, WHERE)

SQL을 함수처럼 생각하고 이해하는 방식도 재미있습니다. 함수의 입력값은 데이터베이스에 저장된 단일 혹은 복수의 테이블이며, 함수의 출력값은 M*N 사이즈를 갖는 단일 테이블입니다. 입력을 받아서 어떻게 출력을 할 것인지는 SQL 구문이 정의하게 됩니다.
7.마케터를 위한 SQL : 데이터 가공 - 함수 (Function), Group by, Order by (작성중)
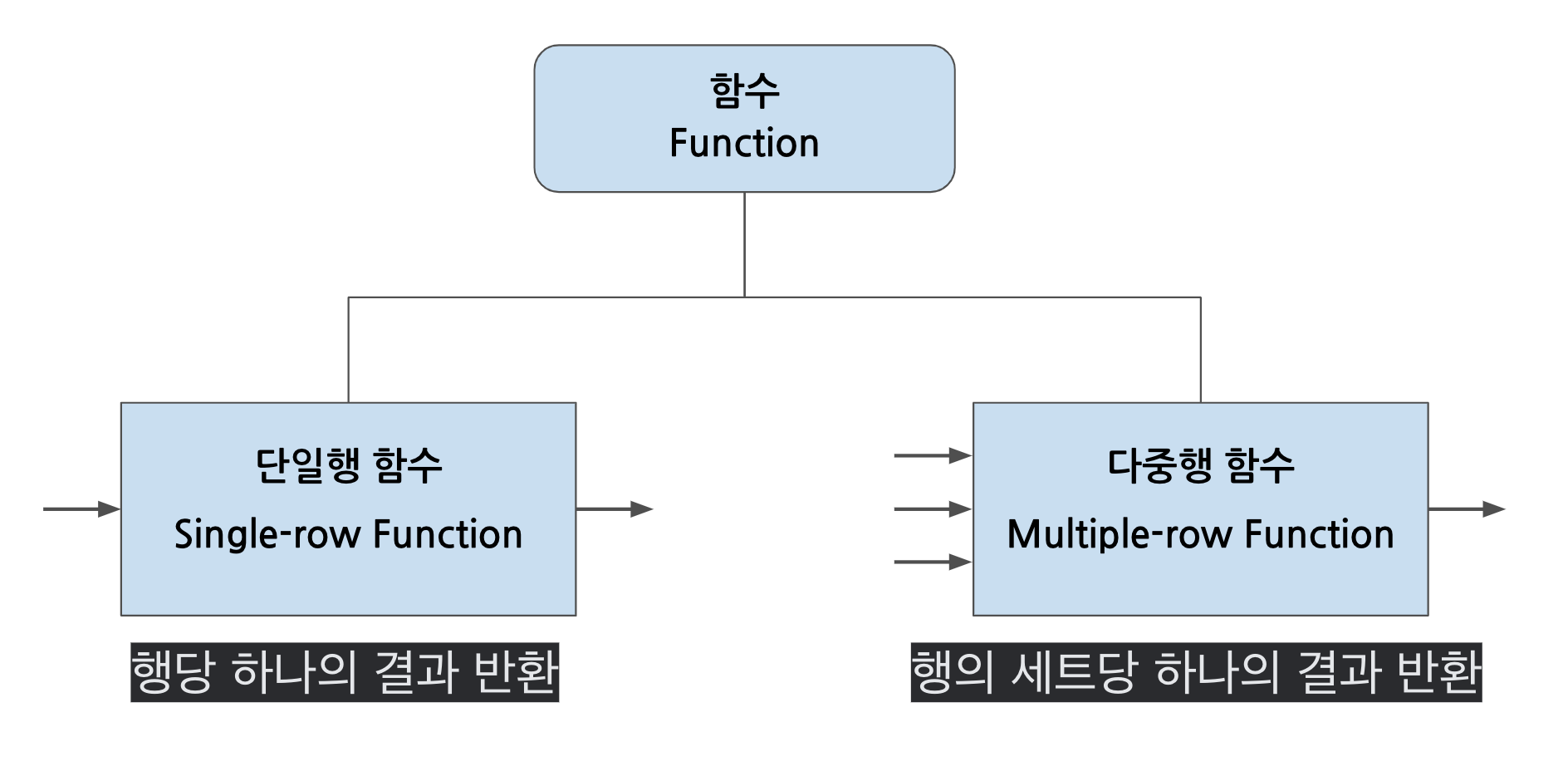
이전 블로그, 마케터를 위한 SQL: 중간 정리 (SELECT, FROM, WHERE) 에서 MN 사이즈를 갖는 단일 테이블을 조회하는 기초적인 SQL 구문들을 정리했습니다. 이번편에서는 MN 테이블 내에서 데이터를 가공하는 다양한 방법을 소개합니다.함수는 크게 단일행