
링크
문제
모양은 같으나, 무게가 모두 다른 N개의 구슬이 있다. N은 홀수이며, 구슬에는 번호가 1,2,...,N으로 붙어 있다. 이 구슬 중에서 무게가 전체의 중간인 (무게 순서로 (N+1)/2번째) 구슬을 찾기 위해서 아래와 같은 일을 하려 한다.
우리에게 주어진 것은 양팔 저울이다. 한 쌍의 구슬을 골라서 양팔 저울의 양쪽에 하나씩 올려 보면 어느 쪽이 무거운가를 알 수 있다. 이렇게 M개의 쌍을 골라서 각각 양팔 저울에 올려서 어느 것이 무거운가를 모두 알아냈다. 이 결과를 이용하여 무게가 중간이 될 가능성이 전혀 없는 구슬들은 먼저 제외한다.
예를 들어, N=5이고, M=4 쌍의 구슬에 대해서 어느 쪽이 무거운가를 알아낸 결과가 아래에 있다.
- 구슬 2번이 구슬 1번보다 무겁다.
- 구슬 4번이 구슬 3번보다 무겁다.
- 구슬 5번이 구슬 1번보다 무겁다.
- 구슬 4번이 구슬 2번보다 무겁다.
위와 같이 네 개의 결과만을 알고 있으면, 무게가 중간인 구슬을 정확하게 찾을 수는 없지만, 1번 구슬과 4번 구슬은 무게가 중간인 구슬이 절대 될 수 없다는 것은 확실히 알 수 있다. 1번 구슬보다 무거운 것이 2, 4, 5번 구슬이고, 4번 보다 가벼운 것이 1, 2, 3번이다. 따라서 답은 2개이다.
M 개의 쌍에 대한 결과를 보고 무게가 중간인 구슬이 될 수 없는 구슬의 개수를 구하는 프로그램을 작성하시오.
입력
첫 줄은 구슬의 개수를 나타내는 정수 N(1 ≤ N ≤ 99)과 저울에 올려 본 쌍의 개수 M(1 ≤ M ≤ N(N-1)/2)이 주어진다.
그 다음 M 개의 줄은 각 줄마다 두 개의 구슬 번호가 주어지는데, 앞 번호의 구슬이 뒤 번호의 구슬보다 무겁다는 것을 뜻한다.
출력
첫 줄에 무게가 중간이 절대로 될 수 없는 구슬의 수를 출력 한다.
풀이
-
일단 특정 구슬 보다 무거운 구술 혹은 가벼운 구슬의 개수를 찾는 로직을 짜야 한다.
- 처음에는 무거운 구슬이 무엇인지 가벼운 구술이 무엇인지 번호를 찾으려 했으나 우리가 답으로 찾는 건 갯수이므로 개수만 찾아도 된다고 판단.
-
그 후 특정 구슬의 개수가 중앙값 보다 같거나 큰지 확인한다.
- 어떤 구슬이 그 구슬보다 무거운 구슬을 중앙값(ex: 3)만큼 가지고 있다면 그 구슬은 절대 중앙값이 될 수 없다.
- 이미 구슬은 중앙값보다 최소 1칸 이상은 떨어져 있기 때문이다. (구슬의 개수가 5개이고, 중앙값이 3일 때를 떠올려보면 금방 이해가 된다.)
-
그럼 더 무거운 혹은 가벼운 구슬의 개수는 어떻게 찾을 수 있을까?
-
구슬들을 그래프 관계로 떠올려보고 DFS를 이용한다.
-
딕셔너리를 활용해
키: 구슬번호 / 값: 그 구슬보다 더 작은 구슬번호의 방향이 있는 인접그래프를 만들었다.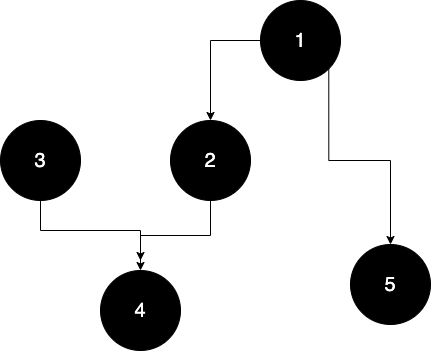
-
그림을 보면 특정 구슬(1)보다 무거운 구슬(2)은 한개가 아니라 여러 개인 것을 알 수 있다.(2보다 3이 더 크면 1< 3이기 때문.)
-
저 관계를 활용해 DFS를 타고 들어가면 1보다 큰 건, (2,4,5)라는 걸 알 수 있다.(재귀로 타고 내려갈 때마다 +1을 해준다.)
-
방향이 있는 그래프이기 때문에 한번 재귀로 타고 내려가서 더 이상 갈 수 있는 지점이 없으면 멈추게 되어있다.
- 단, 한번 들렀던 지점은 방문 체크를 해줘야 한다. 그렇지 않으면 계속 들릴 수 있기 때문에 시간이 많이 걸리게 돼 시간초과가 난다.
-
따라서 반복문을 5번 돌려서 모든 지점을 출발 지점으로 만드는 탐색 방법을 써야한다.
-
특정 구슬보다 무거운 구슬 개수가 나올 때마다 중앙값과 비교한다. 중앙값보다 같거나 크면 개수(answer)를 +1 해준다.
-
특정 구슬보다 가벼운 구슬은 그래프를 반대로 뒤집으면 풀 수 있다.
-
코드
import sys
from collections import defaultdict
N,M = map(int,sys.stdin.readline().split())
tmp_lst = [list(map(int,sys.stdin.readline().split())) for _ in range(M)]
lighter_node_graph = defaultdict(list)
heavier_node_graph = defaultdict(list)
for i, j in tmp_lst:
lighter_node_graph[i].append(j)
lighter_node_graph[j]
heavier_node_graph[j].append(i)
heavier_node_graph[i]
median = (N+1)//2
def bfs(vertex,graph):
global count
visited_node[vertex] = 1 # 방문 체크 해줘야 함.
for item in sorted(graph[vertex]):
if visited_node[item] == 0:
# visited_node[item] = count
count += 1
bfs(item,graph)
return count
heavy_cnt=0
light_cnt=0
for marble in range(1,N+1):
visited_node = [0 for _ in range(N + 1)]
count = 0 # dfs 탐색하는 개수를 무거운거 찾을 때, 가벼운거 찾을 때 각각 초기화
if bfs(marble,heavier_node_graph) >= median:
heavy_cnt+=1
count = 0
if bfs(marble,lighter_node_graph) >= median:
light_cnt+=1
print(heavy_cnt+light_cnt)