
이번 글에서는 데이터베이스 인덱스에 대해 자세히 알아보려고 한다.
인덱스의 정의와 사용 이유, 작동 원리, 주의사항, 인덱싱 읽기 방식 등에 대해 정리해보려고 한다.
인덱스란
인덱스는 데이터베이스에서 데이터 검색 속도를 높이기 위한 데이터 구조이다. 인덱스를 생성하면 데이터베이스는 인덱스 테이블을 가지는데, 키-값 쌍으로 이루어진 테이블 형태라고 볼 수 있다. 값에는 실제 데이터를 가리키는 포인터(혹은 물리 주소)를 포함한다.
왜 사용할까?
보통 데이터베이스 인덱스는 책의 목차/색인에 비유하는데 목차의 존재 이유를 떠올리면 이해가 쉬울 것이다.
책에 목차가 있다면 찾고자 하는 내용을 더 빠르게 찾을 수 있다.
예를 들어, 요리 책을 읽고 있다고 가정해보자.
요리 책은 한식, 중식, 일식, 양식 등의 내용이 있는데 목차를 보니 중식 관련 내용은 100~200페이지에 존재한다고 알게 되었다. 이처럼 우리는 책에서 어떠한 내용에 대해 찾고 싶을 때 목차를 통해 대략 ‘i~j 페이지 안에 있겠구나’라고 생각하고 내용을 빠르게 찾을 수 있게 된다.
중식 중에서도 ‘깐쇼새우’에 대해 찾고싶다고 해보자. 목차를 보니 ‘깐쇼새우’는 167페이지에 있다. 이처럼 특정 주제를 찾고 싶을 때 목차를 통해 정확히 i 페이지에 있다라는 것도 빠르게 알 수 있다.
만약에 책에 목차가 없다면, 찾고자하는 주제를 정확히 찾기 힘드므로 책의 1페이지부터 찾아야 할 것이다. 최악의 경우에는 그 주제가 책의 마지막 페이지에 있어서 책의 모든 페이지를 뒤져야만 내가 원하는 내용을 찾을 수 있게 된다.
이처럼 인덱스를 활용하면 데이터베이스 내에서 데이터를 효율적으로 탐색할 수 있게 된다. 특히 데이터의 양이 많아질 수록 그 효과는 매우 증대한다.
어떤 경우에 주로 쓰는걸까?
인덱스는 주로 데이터베이스의 성능과 관련된 다양한 문제를 해결하기 위해 사용된다. 관계형 데이터베이스를 사용하다보면 아래와 같은 성능 이슈들이 발생할 수 있는데, 인덱스를 사용하면 성능 이슈를 많이 완화할 수 있다.
1. 데이터가 많아지면 검색 속도가 느려진다.
- 테이블의 데이터 양이 많아질수록, 특정 데이터를 찾기 위한 조회 속도가 느려질 수 밖에 없다. 데이터베이스는 데이터를 찾기 위해 full table scan을 하는데, 거의 모든 데이터를 훑어야하면 그만큼 레이턴시가 늘어난다. 이럴 때 인덱스를 사용하여 조회 성능을 향상시킬 수 있다.
Full Table Scan : 데이터베이스에서 쿼리를 수행할 때, 특정 조건에 맞는 데이터를 찾기 위해 테이블의 모든 행을 처음부터 끝까지 순차적으로 검사하는 과정.
2. 비효율적인 조인 연산
-
여러 테이블을 조인할 때, 조인 조건에 맞는 행을 찾기 위해 시간이 많이 소요될 수 있는데, 특히 복잡한 쿼리에서 성능 저하의 주요 원인이 된다. 이 때 조인을 수행하는 테이블 컬럼에 인덱스를 생성하면, 조인 조건을 만족하는 조인 연산의 속도를 크게 향상시킬 수 있다.
-
예를 들어 아래와 같이 Departments, Employees 테이블이 있다고 생각해보자.
Departments테이블:DepartmentID DepartmentName 1 HR 2 Engineering 3 Marketing Employees테이블:EmployeeID Name DepartmentID 101 Alice 2 102 Bob 2 103 Charlie 1 104 Dana 3 그리고 우리는
Employees테이블과Departments테이블을 조인하여 각 직원의 부서 이름을 가져오고 싶다.인덱스를 사용하지 않는 경우,
-
Employees테이블의 첫 번째 행(Alice, DepartmentID=2)을 읽는다. -
그 다음,
Departments테이블을 Full table scan하여DepartmentID가 2인 행을 찾는다. -
이 과정을
Employees테이블의 모든 행에 대해 반복한다.이렇게 되면
Departments테이블을 여러 번 Full table scan 해야 하므로, 데이터가 많을수록 매우 비효율적이다.
반면에
DepartmentID컬럼 인덱스를 사용하여 조인을 수행한다면,- 동일하게
Employees테이블의 첫 번째 행(Alice, DepartmentID=2)을 읽습니다. DepartmentID인덱스를 활용해서,Departments테이블을 전체 스캔할 필요 없이DepartmentID가 2인 행을 빠르게 찾을 수 있다.- 이 과정을
Employees테이블의 모든 행에 대해서 반복한다.
-
Full table scan을 할 필요가 없기 때문에 훨씬 효율적이다.
3. 비효율적인 데이터 정렬 및 집계
- 대량의 데이터를 정렬하거나 집계 함수(ex. AVG 등)를 사용하는 작업은 처리 시간이 많이 소요될 수 있다. 이 때 인덱스를 사용하면 정렬된 데이터에 빠르게 접근할 수 있으므로, 데이터 정렬 및 집계 작업의 성능을 개선할 수 있다.
4. 외래 키 데이터 무결성 유지
- 데이터베이스에서 외래 키를 사용한다면, 외래 키에 대한 참조 무결성 제약 조건을 보장해야 한다. 이 때 외래 키에 대한 인덱스를 사용하면 외래 키 참조 무결성 제약 조건 검사를 효율적으로 할 수 있다.
- 위의
Employees,Departments테이블 예시를 다시 보자. 인덱스를 사용하지 않으면,
Employees 테이블에 새로운 행을 삽입할 때, 무결성 체크를 위해 데이터베이스는 Departments 테이블에서 해당 DepartmentID가 존재하는지 검사해야 한다. 만약 DepartmentID인덱스가 없다면, 이 검사를 위해 데이터베이스는 Departments 테이블의 모든 행을 순차적으로 스캔해야 한다.
외래키를 사용할거면 외래키 인덱스를 설정해주는게 웬만하면 좋은 것 같다. 물론 실무에서 외래 키 설정을 안 하는 경우가 있는데 그래도 외래 키에 대응하는 키에 인덱스를 세팅해주는게 좋다고 한다.
작동 원리
그렇다면 인덱스는 어떻게 생성되고, 동작하는지도 궁금해진다.
대표적인 인덱스 자료 구조로는 B-트리, 해시 테이블, R-트리 등이 있는데, 이 글에서는 B-Tree 인덱스 위주로 동작 원리를 알아 보려고 한다.
B-트리 인덱스의 기본 구조
먼저 B-트리부터 간략하게 알아보자. B-트리는 노드가 2개의 자식만을 가지는 이진 트리를 확장하여 N개의 자식을 가질 수 있도록 만들어진 자료 구조이다.
최상위에 루트 노드가 있고, 가장 하위 노드를 리프 노드, 루트와 리프 사이에 있는 노드들을 내부 노드라고 한다.
인덱스 동작 원리를 알기 위해서는 먼저 페이지에 대해 알아야 한다.
페이지란 디스크 혹은 메모리(버퍼 풀)에 데이터를 읽고 쓰는 최소 작업 단위이다.
데이터베이스의 데이터는 페이지 단위로 관리된다.
인덱스(논클러스터 인덱스), PK(클러스터 인덱스), 테이블 또한 모두 페이지 단위로 관리된다.
만약 1개의 레코드를 조회하는 쿼리를 수행하면 내부적으로는 하나의 페이지를 읽는다.
그래서 페이지에 저장되는 개별 레코드의 크기를 최대한 작게 만들어서, 페이지 당 많은 데이터들을 저장해야 한다.
페이지에 저장되는 레코드 크기가 커지게 되면, 디스크 I/O가 많아지고, 버퍼풀(메모리)에 캐싱하는 페이지의 수가 줄어들 수 있다.
레코드의 크기가 커서 레코드를 찾기 위해 2개의 페이지를 읽어야 한다면, 디스크에서 추가 페이지를 읽어야 하므로 1개 페이지 읽는 것 보다 성능이 떨어지게 된다.
버퍼풀은 디스크에서 페이지를 읽어오면 캐싱 역할을 하는 메모리인데, 페이지의 크기가 크면 메모리에 캐싱해둘 수 있는 페이지 수가 자연스레 줄어든다. 캐싱 페이지가 적으면 그만큼 디스크에서 읽어와야하므로 성능이 떨어진다.
인덱스를 생성하기 위해
먼저 인덱스 키를 추출해서 트리를 만든다. 인덱스는 페이지 단위로 저장되며, 인덱스 키(내가 설정한 컬럼)를 바탕으로 항상 내림차순이든 오름차순이든 정렬된 상태를 유지한다.
B-Tree의 리프 노드에는 (인덱스 키, PK) 쌍으로 저장되어 있다. 이 PK는 실제 레코드에 접근하기 위해 저장한다.
B-트리의 각 레벨(루트, 내부, 리프 노드)는 하나 이상의 페이지로 구성될 수 있다.

Image by Ninad Shah
(이 그림에서는 CTID로 나와있지만, PK라고 봐도 무방하다.)
예를 들어 다음과 같이 설계된 테이블이 있다고 하자.
CREATE TABLE employee (
emp_no INT NOT NULL AUTO_INCREMENT,
name VARCHAR(64),
PRIMARY KEY(emp_no),
INDEX name_idx (name)
) ENGINE=InnoDB;이 테이블의 인덱스 구조도를 그림으로 표현하면 다음과 같다.
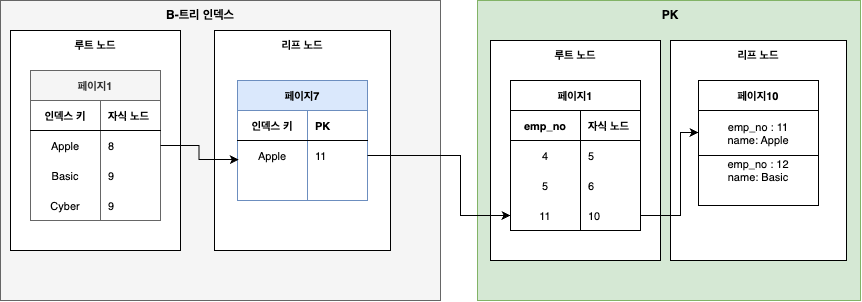
왼쪽의 B-Tree 인덱스 영역과 오른쪽의 PK(클러스터 인덱스) 영역으로 나눠진다.
페이지는 키 값을 기준으로 정렬되어 있다.
name_idx 인덱스의 경우, name 값을 기준으로 정렬되어 있다.
트리의 리프노드에 도달하면 인덱스 키와 레코드의 PK 값이 저장되어 있다.
인덱스 트리는 레코드가 저장된 테이블과 독립적인 영역이므로 인덱스를 통해 데이터를 조회하기 위해 먼저 PK를 찾아야 한다.
이 때(인덱스 영역에서 테이블 영역으로 넘어가는 경우) PK는 테이블 영역에서 어느 페이지에 저장되어 있는지 알 수 없으므로 랜덤 탐색이 발생한다.
PK를 찾으면 루트 노드를 따라서 리프 노드에서 실제 레코드를 읽어온다.
참고로 연속된 데이터를 조회하는 경우에는 순차 탐색이 발생한다. B-트리는 연속된 데이터를 저장하기 때문에 다음 장소에서 데이터를 가져오므로 랜덤 탐색보다 더 효율적이다.
사실은 실제로 쿼리 실행 계획을 결정하는 옵티마이저 입장에서는 인덱스 조회 방식(인덱스 → PK → 레코드)대로 읽어오는게, 비용 효율적이진 않다. 옵티마이저는 인덱스를 통해 레코드를 읽는 것이 테이블을 통해 직접 읽는 것보다 4~5배 정도 비용이 더 많이 든다고 예측한다.
그러나 Full table scan을 하는 것보다는 인덱스를 통해 레코드를 가져오는게 디스크 읽기 속도가 훨씬 빠르기 때문에 인덱스를 사용한다.
그런데 무조건 좋은 기술은 없다. 위에서 언급한 것처럼 인덱스를 통해 읽는 것이 비용이 더 비싸기 때문에 읽어야할 레코드의 건수가 20%~25%를 넘어서면 인덱스 대신 Full scan을 이용하는 것이 더 효율적이라고 한다.
인덱스 생성 시 참고사항
PK
PK는 레코드의 물리적인 저장 위치를 결정하는 요소이기 때문에(MySQL 기준), 인덱스는 PK에 의존한다.(인덱스 → PK → 레코드 탐색)
만약에 (인덱스 키, PK)가 아니라 (인덱스 키, 실제 레코드의 물리 주소)를 저장해놓으면 어떨까?
그렇게 구축할 수도 있지만, 그러면 PK가 변경될 때 레코드의 주소가 변경되기 때문에, 모든 인덱스에 저장된 레코드 주소를 변경해야 한다. 변경 오버헤드가 발생하기 때문에 인덱스는 레코드의 주소가 아닌 PK를 가지고 있는 것이다.
그리고 PK 값도 클수록 효율이 떨어진다. PK 값이 크면 한 페이지에 담을 수 있는 인덱스 정보가 줄어들기 때문에 메모리도 더 사용해야하고, 인덱스 트리의 깊이도 더 깊어지기 때문에 성능이 더 악화되기 때문이다.
참고 :
Does the MySQL primary key affect the efficiency of a SELECT query?
SQL server - worth indexing large string keys?
다중 컬럼 인덱스
보통 인덱스를 설정할 때는 단일 컬럼 인덱스(ex. name)로 설정을 한다. 인덱스는 여러 개의 컬럼으로도 구성될 수 있는데, 이를 다중 컬럼 인덱스(Multi column Index)라고 부른다.
다중 컬럼 인덱스 설정 시 주의해야 할게 항상 다음 컬럼이 이전 컬럼에 의존하여 정렬된다는 것이다.
예를 들어 다음과 같은 dept_emp 테이블이 있다고 하자.
CREATE TABLE `dept_emp` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`dept_no` varchar(100) NOT NULL,
`emp_no` varchar(100) NOT NULL,
INDEX idx_dept_emp (`dept_no`, `emp_no`),
PRIMARY KEY (`id`)
);dept_no 와 emp_no 로 구성된 다중 컬럼 인덱스의 경우, 두 번째 컬럼(emp_no)은 첫 번째 컬럼(dept_no)에 의존해서 정렬된다.
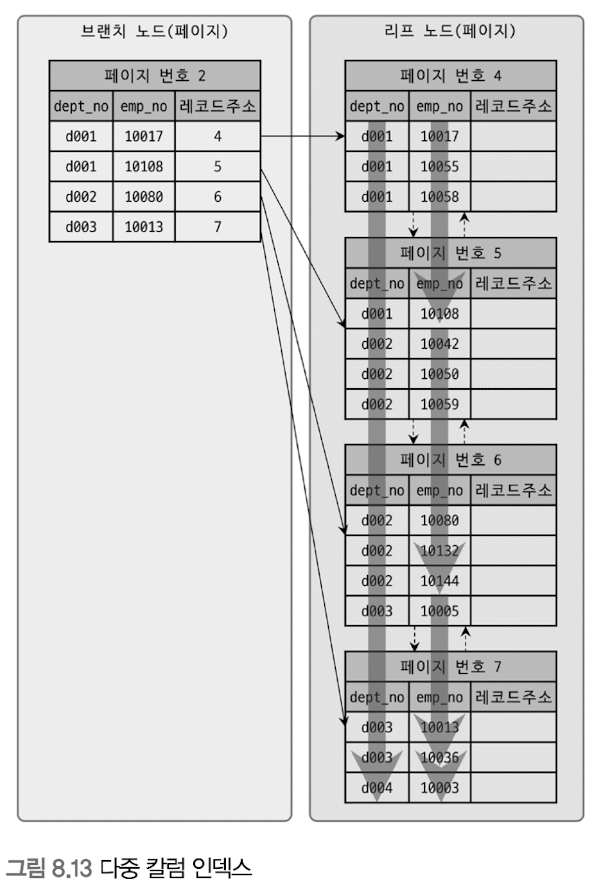
그렇기 때문에 아래처럼 두 번째 컬럼 만으로 조건을 걸어서 쿼리하는 경우 인덱스가 제대로 적용되지 않는다.
select * from student
where dept_emp.emp_no = 4;선행하는 컬럼에 대한 조건이 없는 경우 작업의 범위를 결정할 '작업 범위 결정 조건'을 정하지 못해 인덱스를 사용하지 못하게 되는 것이다.
그래서 다중 컬럼 인덱스를 구성할 때는 컬럼의 순서는 상당히 중요하다.
- 비교 조건 쿼리 같이 개수가 상대적으로 적은 데이터를 조회하는 경우가 많은 컬럼을 다중 컬럼 인덱스 앞 쪽에 설정하고,
- 범위 조건 쿼리 같이 개수가 상대적으로 많은 데이터를 조회하는 경우가 많은 컬럼을 다중 컬럼 인덱스 뒤 쪽에 설정해야 한다.
- 이전 컬럼 정렬 의존성 때문에 더 비효율적으로 Insert/Update/Delete를 수행하므로 가급적 업데이트가 안 되는 값을 선정해서 사용하는 것이 좋다.
언제 사용하면 좋을까?
- 데이터를 조회할 때 단일 인덱스를 여러 개를 사용해야 하는 경우가 많다면 다중 컬럼 인덱스를 고려해 보자.
카디널리티
카디널리티란 특정 컬럼 데이터의 고유성을 의미한다. 따라서 카디널리티가 높을수록 데이터의 중복도가 낮아지며, 고유한 값이 많다는 걸 의미한다.
다음과 같은 dept_emp 테이블이 있고, 레코드가 10,000건이 있다고 가정해보자.
CREATE TABLE `dept_emp` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`dept_no` varchar(100) NOT NULL,
`emp_no` varchar(100) NOT NULL,
INDEX idx_dept (`dept_no`),
PRIMARY KEY (`id`)
);- 케이스 1
dept_no컬럼의 유니크한 값이 10개(ex. 1,2,3,4,5,6,7,8,9,10,11,11,12,12,13)라면
1개의dept_no에 평균 1000개(10000 / 10)의emp_no가 저장된다.
- 케이스 2
- dept_no 컬럼의 유니크한 값이 1000개(ex. 1,2,3,…,1000, 1001,1001,1002,1002)라면
1개의dept_no에 평균 10개(10000 / 1000)의emp_no가 저장된다.
- dept_no 컬럼의 유니크한 값이 1000개(ex. 1,2,3,…,1000, 1001,1001,1002,1002)라면
이제 아래 쿼리를 실행하면 어떻게 될까?
SELECT * FROM dept_emp WHERE dept_no = '002' AND emp_no = '120';결과로 얻는 레코드는 5개라면,
케이스 1의 경우 인덱스 당 평균 1000개의 레코드가 있으므로 1000개의 레코드를 읽지만, 실제로 리턴되는 레코드는 5개이므로 995개가 추가로 탐색 됐다.
케이스 2의 경우 5건만 추가로 탐색 됐으므로 상대적으로 더 효율적이다.
(MySQL의 인덱스의 통계 정보 중 고유한 값의 개수가 있다. 그래서 인덱스 별로 평균적으로 몇 건의 레코드가 있는지를 계산하여 이를 쿼리 실행 시에 활용한다.)
그러므로 일반적으로 인덱스는 카디널리티가 높을수록 효율적이다. 다만 카디널리티가 낮더라도 정렬이나 그룹핑에 사용될 수 있으므로, 높은 카디널리티를 가진 컬럼만 인덱스로 설정해야 하는건 아니다. 용도에 맞게 설계하자.
인덱스의 정렬 및 스캔 방향
인덱스는 내림차순 혹은 오름차순으로 정렬할 수 있다.
처음에 오름차순으로 정렬 설정을 했다하더라도, 인덱스를 오름차순대로만 읽을 수 있는 것은 아니다.
인덱스를 읽는 방향은 옵티마이저가 실시간으로 만들어내는 실행 계획에 따라 결정된다.
인덱스를 설정한 순서대로 읽는 것을 인덱스 정순 스캔(Index Forward Scan), 반대 방향으로 읽는 것을 인덱스 역순 스캔(Index Backward Scan)이라고 한다.

인덱스 역순 스캔은 인덱스 정순 스캔보다 느리다. 그 이유는 동기화를 할 때 사용하는 페이지 잠금이 인덱스 정순 스캔에 적합한 구조이기 때문이다. 역순도 페이지 잠금이 가능하지만 정순에 비해 어렵다고 한다.
페이지 내부에서는 인덱스를 4~8개 정도씩 묶어서 그룹을 만들고 대표키를 선정해 페이지 디렉토리 라는 리스트로 관리하는데, 이 페이지 디렉토리가 단방향 연결만 가능하고, 역방향은 가능하지 않다고 한다.
인덱스 역순 스캔도 단방향 접근이 필요하므로 역순 스캔이 정수 스캔보다 느린 것이다.
자세한 이유는 아래 글에 잘 나와 있다.
인덱스 읽기 방식
인덱스를 읽는 방식은 크게 4가지 정도가 있다.
- Index Range Scan
- Index Full Scan
- Index Unique Scan
- Index Skip Scan
Index Unique Scan
인덱스 유니크 스캔은 지정된 값에 일치한 인덱스만 읽는 방식이다.
예를 들어 아래의 쿼리를 실행했다고 하자.
SELECT * FROM employee WHERE name = 'Melon';인덱스 유니크 스캔을 통해 아래와 같이 레코드를 찾는다.
- 해당 name이 존재하는 리프 노드의 페이지만 찾는다.(수직 탐색)
- 동등 조건에 부합하는 인덱스만 읽는다.
- 읽어들인 인덱스와 PK를 이용해 최종 레코드를 읽어온다.
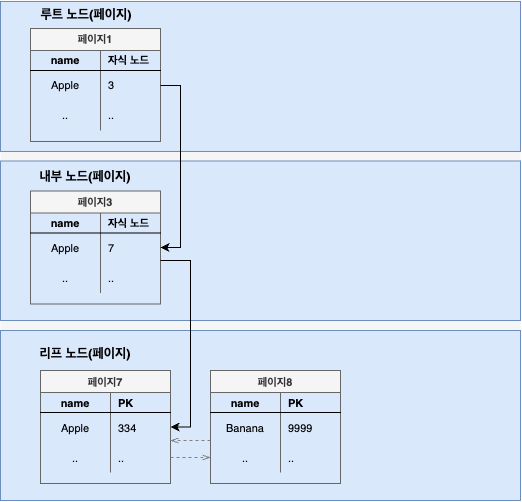
Index Unique Scan을 하기 위해서는 Unique Index(유일한 값으로 구성된 컬럼 인덱스)여야 하며 동등('=') 조건으로 검색하는 경우 작동한다.
Unique Index라도 범위 조건 탐색(between, 부등호, like)을 할 경우에는 Index Range Scan으로 처리된다.
다중 컬럼 인덱스일 경우에는 지정한 컬럼을 모두 동등 조건으로 검색해야 한다. 일부만 검색할 경우 Index Range Scan으로 처리된다.
Index Range Scan
인덱스 레인지 스캔은 범위가 결정된 인덱스를 읽는 방식이다.
예를 들어 아래의 쿼리를 실행했다고 하자.
SELECT * FROM employee WHERE name BETWEEN 'Kiwi' AND 'Potato';정해진 범위만 접근하는 방식이므로 이 방식은 (Unique scan보다는 느리지만) 다른 방식들보다 빠르다.
쿼리의 실행 순서를 정리하면 다음과 같다.
- 인덱스의 조건을 만족하는 값이 저장된 위치를 찾는다.(탐색)
- 시작 위치부터 지정한 범위 만큼 인덱스를 순서대로 읽는다.(스캔)
- 읽어들인 인덱스와 PK를 이용해 최종 레코드를 읽어온다.
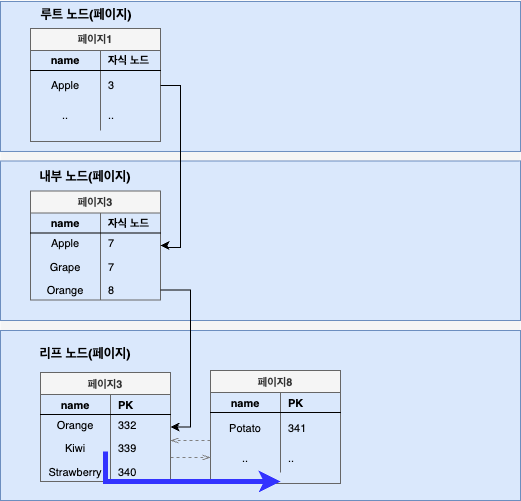
인덱스가 저장된 리프 노드 페이지로 이동한 뒤, 시작점(Kiwi)을 찾고, 순서대로 범위의 마지막 인덱스(Potato)까지 스캔한다. 만약 스캔을 하다가 페이지의 끝에 도달하면 페이지 간의 링크를 이용해 다음 페이지(9)로 넘어간다. 마지막 인덱스를 찾으면 지금까지 읽은 레코드를 반환하고 쿼리를 종료한다. (Range scan이 가능한 이유는 인덱스가 정렬되어 있기 때문이다.)
Index Full Scan
인덱스 풀 스캔은 처음부터 끝까지 모든 인덱스를 읽는 방식이다.
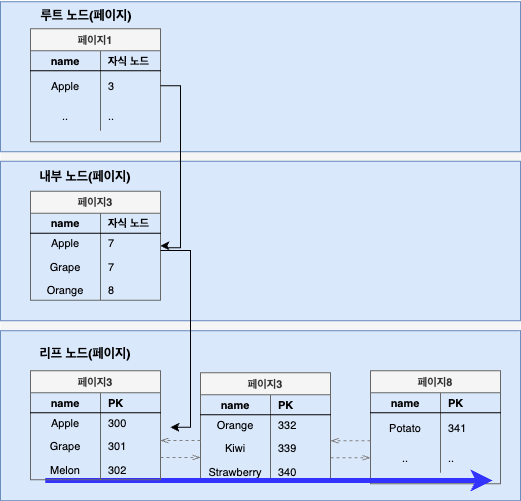
쿼리가 인덱스 혹은 PK만 필요하다면 이 방식이 주로 사용되고, 혹은 탐색을 위한 최적의 인덱스가 없을 때 차선으로 선택된다.(쿼리 조건절에 사용되는 컬럼이 인덱스의 첫번째 컬럼이 아닌 경우 등)
혹은 아래의 쿼리들
1. SELECT COUNT(*) FROM employee
2. SELECT MIN(department_id) from employee;
3. SELECT MAX(department_id) from employee;같이 테이블을 훑을 필요 없이 인덱스만 훑더라도 쿼리가 가능 한경우에 사용된다.
인덱스 풀 스캔이 사용되는 이유는 테이블 풀 스캔을 할 경우에는 다른 레코드들도 포함되어 있으니 비효율적이기 때문이다. 테이블 풀 스캔보다는 적은 디스크 탐색으로 쿼리를 처리할 수 있다.
그러나 아주 빠른 속도는 아니므로 인덱스 풀 스캔을 많이 쓰는지는 모르겠다.
Index Skip Scan
인덱스 스킵 스캔은 MySQL 8.0부터 추가된 기능으로, 인덱스의 뒷쪽 컬럼만으로 검색하는 경우에 옵티마이저가 자동으로 쿼리를 최적화하여 인덱스를 사용하도록 하는 방식이다.
예를 들어 아래와 같은 employee 테이블에 다중 컬럼 인덱스를 생성했다고 하자.
ALTER TABLE
employee
ADD INDEX
idx_gender_birthdate (gender, birth_date);이 다중 컬럼 인덱스를 사용하려면 WHERE 절에 gender에 대한 조건이 반드시 있어야 한다.
아래와 같이 birth_date 만으로 쿼리하는 경우는 인덱스 적용이 안되므로, 별도의 인덱스를 새롭게 만들어줘야 했다.
SELECT
gender, birth_date
FROM
employee
WHERE
birth_date >= '1993-01-01'하지만 인덱스 스킵 스캔을 사용하면 옵티마이저가 아래 쿼리를 최적화한다.
SELECT
gender, birth_date
FROM
employee
WHERE
birth_date >= '1993-01-01';gender 칼럼에서 유니크한 값을 모두 조회한 후 주어진 쿼리에 gender 칼럼의 조건을 추가해 쿼리를 다시 실행하는 형태로 처리합니다.
인덱스 스킵 스캔이 실행되기 위해서는, 아래의 조건이 필수로 있어야 한다.
- 조회되는 컬럼은 인덱스 혹은 PK 만으로 처리 가능해야 함(커버링 인덱스)
- 인덱스의 선행 컬럼은 WHERE 조건절에 없어야 함.
- 인덱스 선행 컬럼의 카디널리티가 낮아야 함(고유 값이 적어야 함.)
만약 카디널리티가 높으면, 인덱스의 스캔 시작 지점을 검색하는 작업이 많아져서 쿼리의 성능이 떨어지게 된다.
카디널리티가 이 어느 정도면 적은거고 어느 정도면 많은 건지는 상황에 따라 다르므로 실행 계획을 통해 확인할 수밖에 없다. 공식문서에도 언급이 없다고 한다.
커버링 인덱스
여러가지 스캔 방식을 통해 레코드를 읽어올 때 인덱스로 지정한 컬럼 혹은 PK가 아닌 다른 컬럼을 읽어온다면 (당연하겠지만) 테이블에서 레코드를 조회해야한다. 이 경우 PK를 이용해 테이블에서 랜덤 탐색으로 레코드들을 조회해온다.
그런데 만약 인덱스 지정 컬럼이나 PK만 조회해온다면 테이블에서 조회해올 필요 없이 인덱스로 모든 결과를 반환할 수 있다. 이를 커버링 인덱스라고 한다.
커버링 인덱스는 디스크 랜덤 탐색 작업을 줄일 수 있어서 성능이 훨씬 뛰어나다.
예시로 아래의 테이블이 있다고 가정해보자. PK는 id이다.
CREATE TABLE `test` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`first_name` varchar(100) NOT NULL,
`last_name` varchar(100) NOT NULL,
`email` varchar(100) NOT NULL,
PRIMARY KEY (`id`)
);아래의 쿼리를 실행하면 모든 컬럼을 조회해야하므로 테이블에서 레코드들을 조회해와야 한다.
select * from test where id = 333;그러나 아래의 쿼리는 PK만 조회하기 때문에, PK는 테이블에서 조회해올 필요가 없으므로 커버링 인덱스를 통해 조회하게 된다.
select id from test where id = 333;복합 인덱스의 경우에도 커버링 인덱스를 조회해올 수 있다.
예시를 보고싶은 경우 아래의 글을 참고해보자.
MySQL의 InnoDB는 클러스터 테이블이기 때문에 인덱스에 PK가 저장되므로 커버링 인덱스를 사용할 수 있다. 참고로 PostgreSQL도 커버링 인덱스를 지원한다.
인덱스 사용 시의 주의 사항
앞서 인덱스에 대한 여러가지 지식을 가지고 우리는 아래와 같은 결론을 낼 수 있다.
1. 인덱스를 통해 필요한 레코드만 조회하면 Full table scan보다 훨씬 효율적이다.
2. 인덱스는 정순으로 탐색하는 것이 효율적이다.
3. 인덱스를 무조건 많이 생성하는 건 좋지 않다. 저장 공간도 추가로 들어 인덱스도 비대해질 수 있고, 비용도 테이블 직접 읽기보다 비싸다.
그리고 인덱스는 SELECT 외에 UPDATE, DELETE 등에도 사용될 수 있다. Update나 Delete를 할 때도 작업할 레코드들을 탐색해야하고, 그 때 인덱스를 사용할 수 있다. 그리고 레코드가 업데이트 되면 인덱스도 업데이트 해줘야 한다. 즉, 인덱스는 쓰기(INSERT, UPDATE, DELETE)의 성능을 희생하고 데이터의 읽기 속도를 높이는 기능이다. (그래도 쓸 이유는 충분히 있다. 보통 읽기와 쓰기의 비율은 8:2 정도 되기 때문이다.)
그리고 인덱스는 값이 변형되는 경우에 사용될 수 없다. 키 값으로 정렬되는데 값이 변형된 케이스를 탐색할 때는 정렬된 효과를 누릴 수 없기 때문이다. 예를 들어, Like 같이 부분 문자열을 검색할 때 like '%AB’, like '%AB%’ 조건의 검색은 인덱스를 타지 않는다. 정렬 효과를 누릴 수 없기 때문이다.
위에서도 언급했듯이 경우에 따라 인덱스 스캔이 아니라 Full Table scan을 실행해야 하는 경우가 있다.
- WHERE 절이나 ON 절에 인덱스를 이용할 수 있는 적절한 조건이 없는 경우
- 레코드수가 너무 적어서 인덱스를 통해 읽는 것보다 Full Table scan을 하는 것이 더 빠른 경우
- 인덱스 범위 스캔을 사용하더라도 일치되는 레코드 건수가 너무 많은 경우
마치며
오늘 인덱스에 대한 여러가지 지식과 주제를 다뤄보았다. 처음에 인덱스를 공부했을 때 인덱스 적용하면 무조건 성능이 좋아지는줄로만 생각했었다. 그러나 더 공부를 하다보니 인덱스는 성능 향상을 하기 위해 고려해볼만한 옵션 정도로 봐야한다고 느꼈다.
정말 데이터가 많은 테이블은 인덱스로만 성능을 극단적으로 끌어올릴순 없다. 인덱스 자체가 큰 테이블에서 아주 적은 일부 데이터를 빨리 찾고자 할 때 주로 사용하기 때문이다.
대량 데이터를 조회해야 하는 경우라면 Full table scan이 효율적인 경우가 많다고 한다. 성능을 올리기 위해서는 쿼리 자체를 튜닝하거나 파티셔닝 같은 기법을 고려해야할 수 있다.
참고 :
Real MySQL 8.0 책
https://mangkyu.tistory.com/286
https://steady-coding.tistory.com/546