발표 영상 : https://www.youtube.com/watch?v=FUEZibcZEkg
Stateful 서버 구현
-
게임 특성상 클라 요청 및 상태 변화가 빈번하고, 매번 DB에서 유저 정보 가져오기에는 DB 부하가 크다.
- 상태를 서버 메모리에 가지고 있는 STATEFUL 구조가 이점이 많을것이라 판단.
-
Akka 클러스터 바탕으로 stateful 서버 구현
-
Akka : 동시성과 분산 프로그래밍을 위한 툴킷
- 액터 모델 구현하기 위해 사용
- 근데 왜 액터 모델인가?
- 동시성 처리를 위해 사용하는 모델.
- 메세지를 받고, 액터를 새로 만들고, 메세지를 보내고 등을 처리하는 시스템.
- 액터는 액터만의 private 상태를 가지고 있는데, 메세지로만 상태 변경이 가능하다.(캡슐화 되어있음.)
- 액터 모델은 모든 것이 actor라고 가정한다고 함.(OOP와 유사한 컨셉인듯.)
- 액터는 아래와 같은 걸 동시에 할 수 있다고 함.
- send a finite number of messages to other actors;
- create a finite number of new actors;
- designate the behavior to be used for the next message it receives.
- 액터는 mailing address라는걸 가질 수 있는데 주소를 가진 액터들만 서로 통신이 가능하다.
- 근데 왜 액터 모델인가?
- 액터 모델 구현하기 위해 사용
-
액터란 : 경량 스레드 + Queue
-
액터에게 메세지를 보냄 : 액터의 큐에 메세지를 넣는 것, 경량화 된 쓰레드가 자신의 큐에서 하나씩 메세지를 꺼내서 처리
-
Akka Cluster sharding: 액터를 클러스터 내의 여러 노드로 샤딩, 리밸런싱
-
액터 A에게 메시지를 보낸다라고만 프로그래밍 하면, 내부적인 과정들은 Akka Cluster Sharding이 자동으로 해주게 된다.

액터 A가 해당 게임 서버에 들어있지않으면 코디네이터(Akka cluster 내에 하나만 존재하는 컴포넌트, 액터가 어떤 노드에 존재하는지 관리)에게 액터a의 위치를 전달받는다.
해당 게임서버는 액터가 있는 게임서버1에게 전달해서 대신 처리해달라고 요청한다.
게임 서버 1은 처리하고 게임서버2에게 응답을 보내고, 받고나서 게임 서버 2는 최종적으로 클라이언트에게 응답을 보낸다.
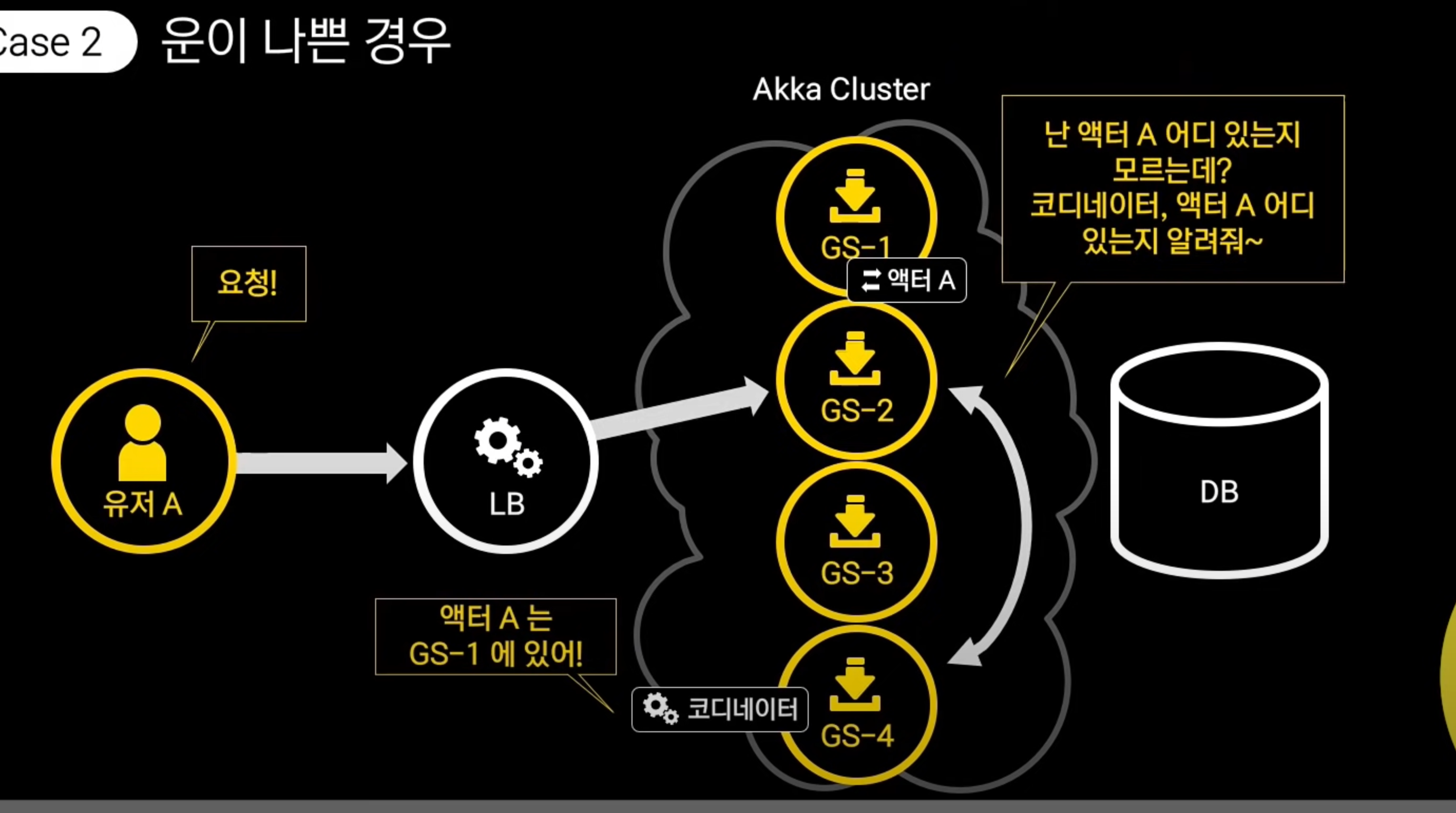
Akka 클러스터는 peer-to-peer 기반이라 안정성 측면에서 이점이 있음.
- 단순히 유저뿐만 아니라 길드 등과 같은 다양한 엔티티들을 액터로서 모델링하고 클러스내에 샤딩 가능.
- 단순히 노드 수를 늘리는 것으로 큰 규모의 부하를 처리할 수 있음.
- Stateless 서버 구조에 비해 동시성 컨트롤이 명확함.
- stateless 서버 같은 경우 서버들이 서로 독립적이라 동시성 컨트롤을 DB의 lock 메커니즘에 의존하는 경우가 많음. 특히 optimistic locking을 사용하는데, 이럴때 특정 리로스에 대한 contention이 심할 경우 성능이 악화될 수 있음. pessimistic locking을 stateless 구조에서 빠르고 안전하게 구현하기 까다로움.
- stateful 구조에는 특정 요청을 처리하는 액터가 하나로 특정되기 때문에 액터 레벨에서 동시성이 컨트롤 됨.(애플리케이션 레벨)
- DB Contention이 발생할 가능성도 줄어듬.
- 액터 모델에서는 큐에 메세지들이 쌓이고 하나씩 꺼내서 처리하는 구조라서 동시성을 DB에 의존하지 않고 액터 레벨에서 직접 관리한다.
단점 : 모든 것을 액터로 구현할 수는 없다.
- 게임의 모든 요소들을 억지로 액터로 끼워맞추려고 하면 구현이 까다롭거나 성능에 문제가 생길 수 있음.
- 예를 들어, 유저 닉네임 고유성 체크를 담당하는 액터를 만들게 되면,
- 천만명이 넘는 닉네임들을 메모리에 가지고 있어야 하고, 1초에 수십건 이상의 요청을 처리해야 한다.(담당 액터가 존재하는 노드가 병목 대상이 될 위험이 높음)
- 해결책으로서 닉네임의 첫 글자를 기준으로 액터를 여러개로 분리하는 방법도 있지만..
- 이런 경우 db의 unique constraints를 통해서 고유성 체크를 구현하는 것이 실용적이다.
- 즉, 액터로 구현할만한 요소들만 액터로 구현하자.
- 즉, 액터로 구현할만한 요소들만 액터로 구현하자.
단점 : Akka클러스터를 안정적으로 운영하고 배포하는 것이 생각보다 까다롭다.
- 여러개의 노드가 하나의 클러스토 묶여서 동작하기 때문에 각 노드가 독립적인 stateless에 비해서 안정성이 떨어질 수 밖에 없음.
- split brain, 액터 리벨런싱, 롤링 업데이트 등 유의해야할 점이 많음.
- 인프라 운영, 배포 측면에서는 stateless가 유리함.
단점 : 액터들이 여러 노드에 분산되어있어서 여러 액터들의 상태를 동시에 변경하는 것이 까다롭다.

고민점 : 액터 상태를 DB에 저장하기 위한 효율적인 방법은 무엇일까?
데이터 저장 기법 CRUD vs 이벤트 소싱
- 전통적인 방법에서는 DB 스키마 설계하고, DB에 CRUD 성격의 쿼리를 이용해 상태를 저장
- 즉, 서버 설계의 핵심 = 데이터 베이스 설계가 되는 경우가 많음.
CRUD 방식을 사용할 때의 고난들

객체 관계형 불일치 참고 링크 : 참고 링크 :
- http://sungsoo.github.io/2013/08/21/impedance-mismatch.html
- https://coco-log.tistory.com/155
- https://medium.com/@SlackBeck/sql은-왜-작성-하는가-58bec43408d9
저 불일치 문제 때문에 ORM 프레임워크가 등장했고, 널리 쓰인다고 함.
상태 저장에 대한 새로운 접근 : 이벤트 소싱
- DB에는 최종 상태가 아닌 발생한 이벤트들을 저장
- 최종 상태는 이벤트들을 리플레이함으로써 얻을 수 있음.

이벤트는 각 액터별로 분리되어 쌓이며 1부터 번호가 차례대로 붙여짐
4번 이벤트 돌리면 쿠키 상태에 데이터가 추가됨.
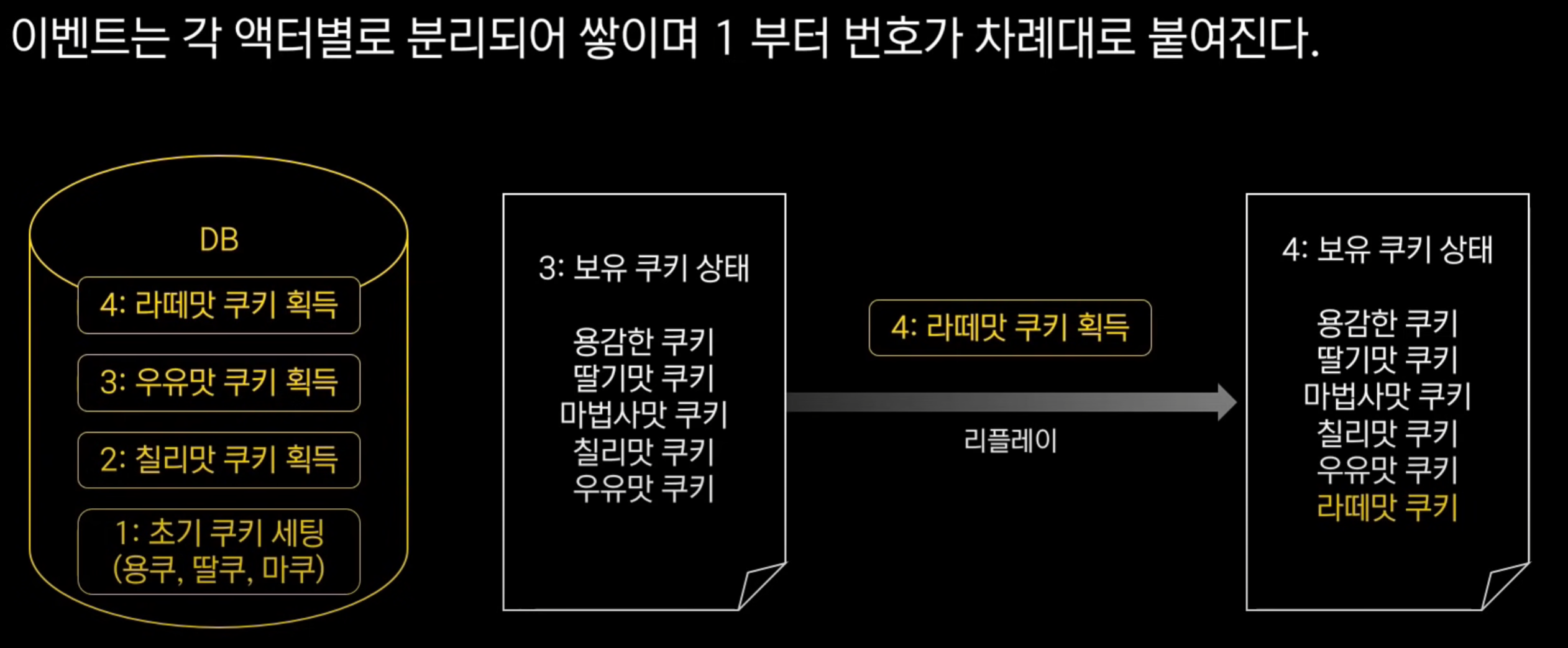
단, 이벤트가 많이 쌓이면 리플레이할 때 시간이 오래 걸릴 수 있다.(데이터를 다 가져오려면 이벤트를 처음부터 리플레이해야함)
- 그러면 성능 문제가?..
- 이벤트 소싱을 사용할 때는 반드시 스냅샷이라는 방법을 같이 사용해야 함.
- 특정 번호의 이벤트까지 리플레이를 미리 저장해두고, 다음부터는 처음부터 리플레이 하지않도록하는 최적화 방법(캐싱 원리네)

다음 이벤트인 4번 이벤트만 리플레이 수행하면 최신 데이터까지 모두 가져올 수 있음.
그러면 스냅샷을 얼마의 주기로 찍어야돼?
- 정답은 없다.
- 로드 테스트를 하거나 실제 서비스를 운영해보면서 조절해야 한다.
- 쿠키런 킹덤은 이벤트 300개마다 스냅샷을 찍는다고 함.
스냅샷이랑 이벤트는 db에 어떻게 저장해?
- 목적에 따라 다른데,
- 킹덤에서는 바이트 덩어리로 직렬화해서 db에 저장함.(저장공간 압축과 명시적인 스키마 관리가 중요했다고 함.) ⇒ protobuf로 직렬화해서 저장
- 가시성이 중요하면 JSON 형태로 저장하면 될듯.

이 스키마로 이벤트 소싱을 구현한다고 함.
- 이벤트와 스냅샷 하위호환성은 어떻게 유지해?
- Protobuf를 사용하면 하위호환성을 체계적으로 관리할 수 있다고 함.
- 물론 개개인의 설계 역량에 따라 큰 차이가 있다고 함.
스냅샷,이벤트는 언제까지 저장해?
- 이상적으로는 영구저장이 좋지만,
- 상태 리플레이에 필요없는 옛날 이벤트, 스냅샷은 실시간으로 삭제 한다고 함.
DB는 뭘로 정해?

=> 그래도 NoSQL이 좋을듯?
이벤트 소싱 장점
- db테이블이 단 2개라고 함. 2개로 모든 것을 할 수 있음.
- 이벤트 테이블, 스냅샷 테이블
- 스키마가 단순해서 DB 관리하는 팀과도 일하기 쉬움.
- DB걱정없이 비즈니스 로직에만 집중할 수 있음.
- DB에 대한 대응역량이 부족해질 순 있음..
- INSERT와 SELECT 쿼리문만 사용한다.
- 어떤 콘텐츠를 구현하던지 DB 사용패턴이 항상 똑같다. 신규 콘텐츠 구현시 DB 성능 문제 발생할 일이 거의 없다.
- DB 사용패턴이 항상 일정하므로 출시 전 부하 예측이 수월하다.
- 굵직한 콘텐츠만 테스트하면 될듯.
- 액터모델과 궁합이 잘 맞다.

- NoSQL에서 document 단위로 상태 저장하는 거랑은 어떻게 다르지?

=> document보다 이벤트가 더 작은 경향이 있긴하겠다..
유저 액터에 회원가입 이벤트들을 발생시키는 것과 DB unique constraint를 바탕으로 한 닉네임 체크를 하나의 트랜잭션으로 수행할 수 있다고 함.(유연성)
이벤트 소싱 단점
-
이벤트 소싱으로 구현하기 힘든 케이스들이 있음.
-
액터 모델, 이벤트 소싱 모두 DDD Aggregate라는 개념에 뿌리를 두고 있어서, Aggregate로 힘든 개체면 이벤트 소싱이 어렵다.
-
여기서 DDD Aggregate란?
- https://sgc109.github.io/2020/08/09/ddd-basic/
- https://sgc109.github.io/2020/08/09/ddd-aggregate/
- https://medium.com/@chanhyeonglee/ddd-aggregate-애그리거트-98d9c1313c23
- https://taeguk2.blogspot.com/2020/02/ddd-aggregate-pattern.html -
발생한 이벤트만 저장되어 있어서 최종 상태를 db에서 직접 조회할 수 없음.
-
상태를 직접 db에서 건드리는 것도 어렵다.
-
별도의 툴을 만들거나 항상 게임 서버를 거쳐야해서 불편함.
이벤트 소싱은 상태 저장을 위한 기법, 다른 목적으로 사용하려 하면 현실적으로 잘 맞지 않는다고 함.(이벤트 기반 아키텍쳐 설계, 데이터 분석 등)
- 킹덤 서버는 별도로 분석 로그 이벤트들을 정의하여 로깅을 구현
Stateful 서버에서 비즈니스 로직은 어떻게 구현해?
- 상태를 어떻게 잘 관리하느냐가 중요.
- 킹덤은 스칼라를 사용해서 함수형 프로그래밍으로 구현
- 사이드 이펙트 없는 콘텐츠 로직을 위한 DSL을 구현했다고 함.
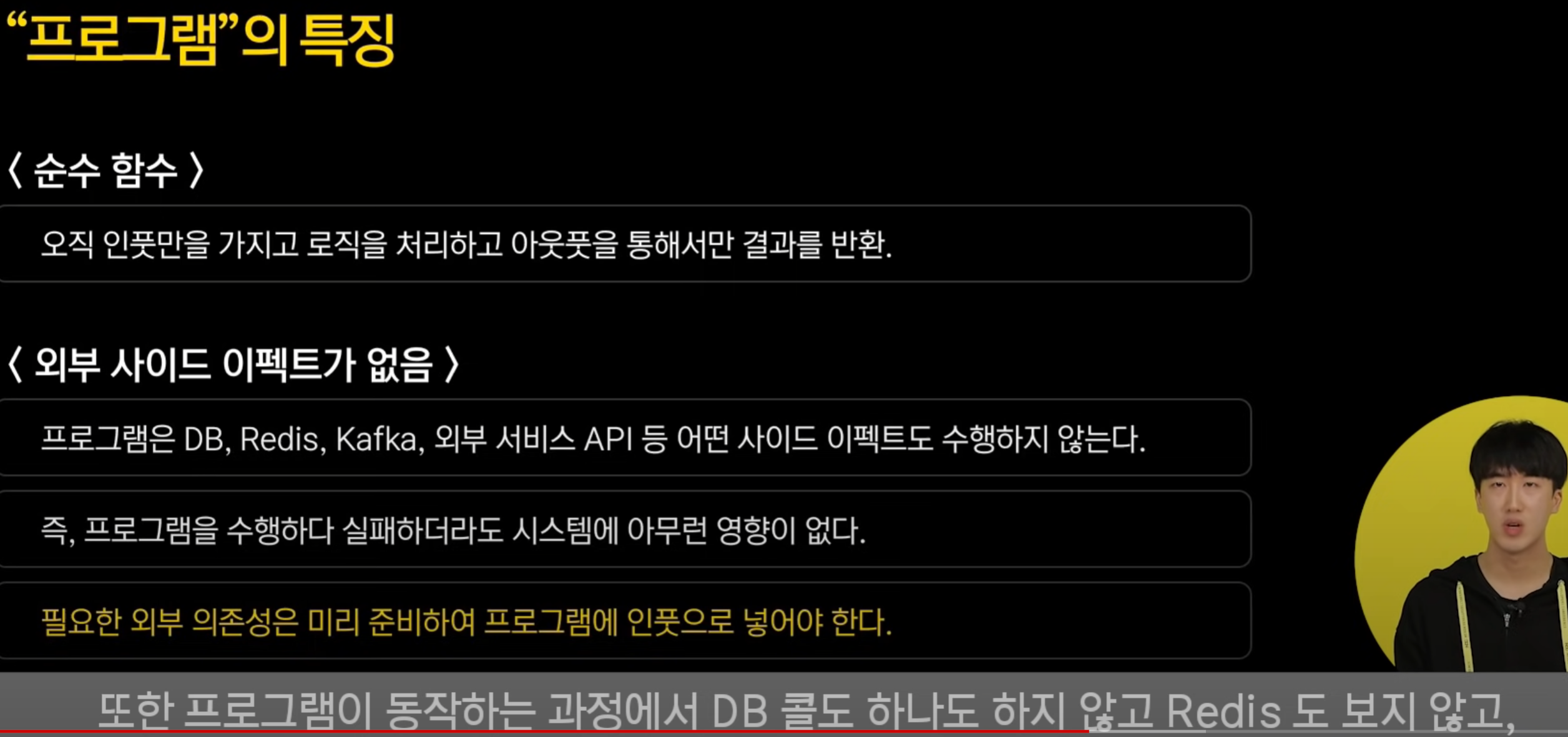
콘텐츠 로직은 함수로 되어있는데, 킹덤에서는 순수함수를 구상했다고 함.
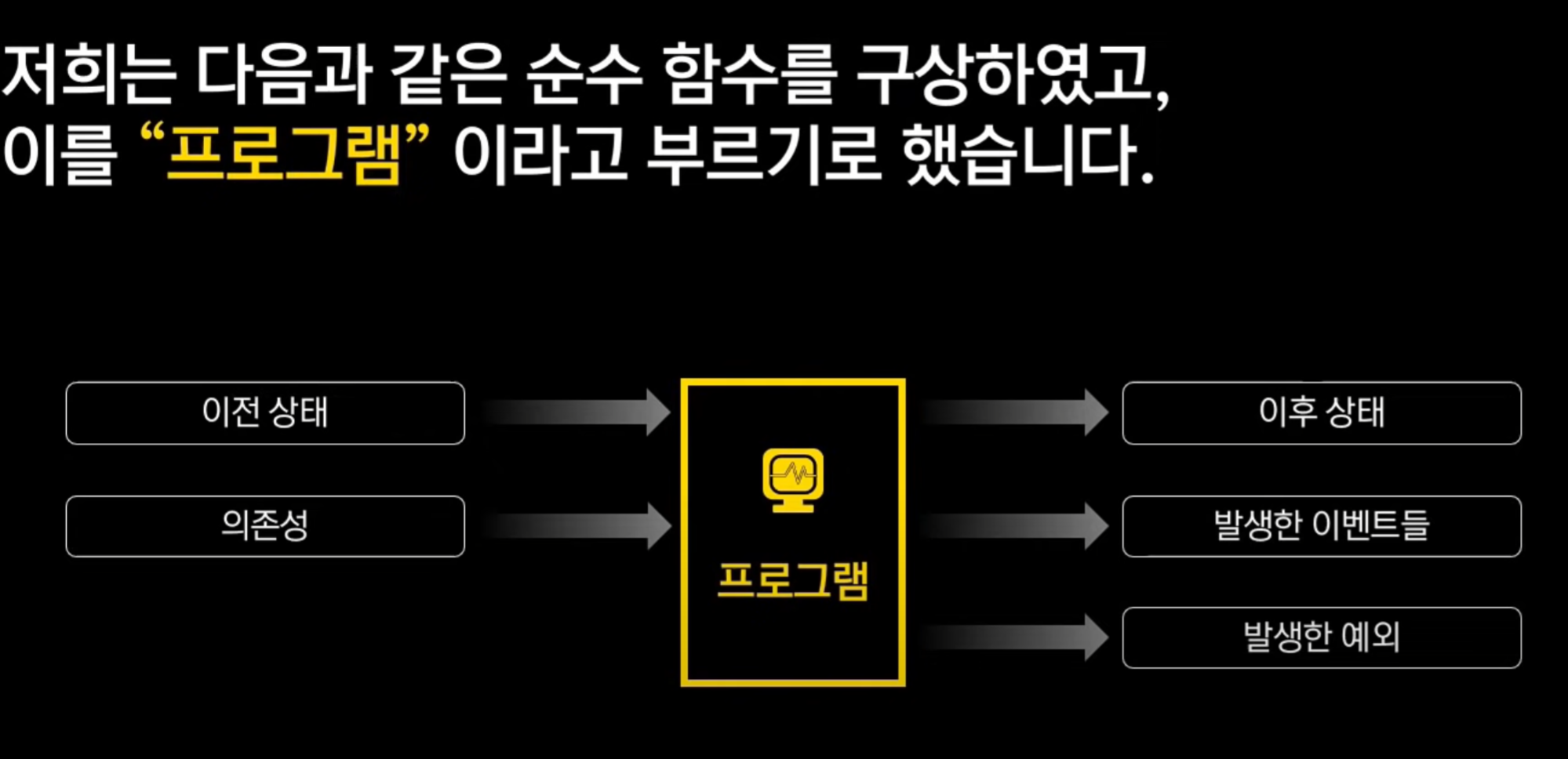
=> 인풋 → 프로그램 → 아웃풋 만 하는 로직
예시 : 쿠키 뽑기라는 프로그램 존재
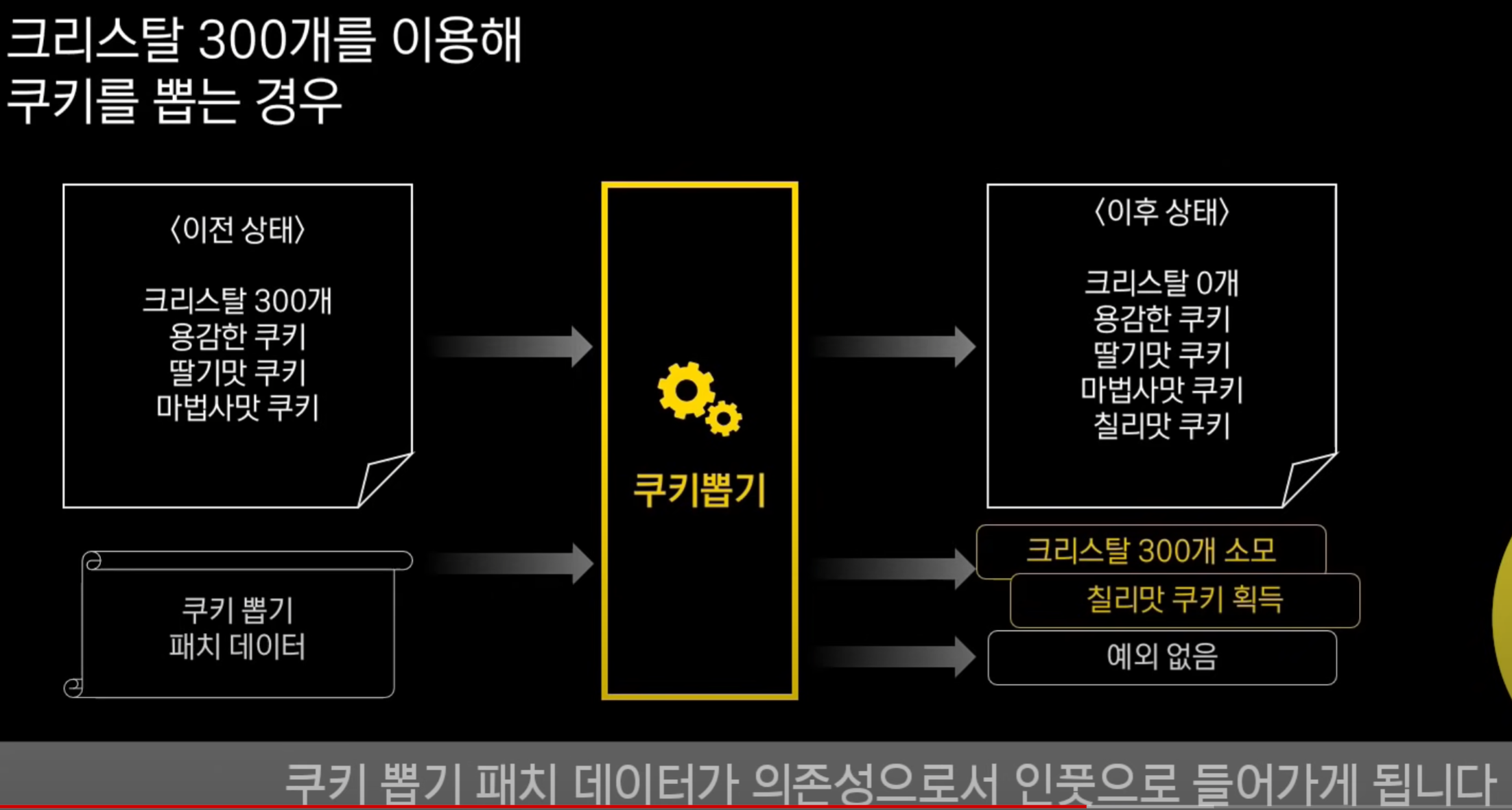
이전 상태, 쿠키 뽑기 패치 데이터를 인풋으로 넣어줘야 함.
아웃풋으로는 이벤트가 반환, 변경된 상태가 반환이 됨.

=> 각종 사이드 이펙트(사이드 이펙트는 부정적인 느낌이지만, 이 영상에서는 사이드 액션 느낌이라고 해석하면 될듯)를 비동기로 수행
콘텐츠 로직 & 사이드 이펙트 발생이 완벽하게 분리된다는 장점이 있음.
프로그램이 실패하면, 액터의 상태와 db에 아무런 변화가 없고 클라에 처리 실패를 응답으로 보내기만 한다.
순수 함수라서 I/O 처리 작업 같은걸 하지 않아도 된다는게 굉장히 인상깊다.
프로그램이 실패해도 시스템에 영향이 없다..!
다만, 프로그램이 수행되는데 필요한 의존성들을 미리 준비하여 넣어줘야 한다고 되긴함.(패치 데이터, 번역 데이터, 쿠폰 목록 등)
그럼 킹덤에서는 의존성을 어떻게 처리 하나?
캐싱 갱신은 모든 노드에게 Notify한다고 함.

순수함수 프로그램 작성을 잘 하기 위해 Domain Specific Language 설계했다고 함.

DSL 예시도 볼 수 있어서 좋았다.
이런 구조가 빠르게 변화하는 기획에 발빠르게 대응할 수 있었다고 함. 큰 장점인듯.
여러 유저가 상호작용하는 콘텐츠(여러 액터의 상태를 동시에 변경하는 케이스)는 어떻게 해?
- 상호작용 콘텐츠는 대표적으로 친구 시스템이나 pvp 시스템이 있다.
- 보통 생각해보는 친구 요청 기능 구현 방법

2번은 구현해놓은 액터 모델 바탕으로 유저 액터에 추가함으로써 구현
2번의 경우, 구현 시 이슈가 있음.
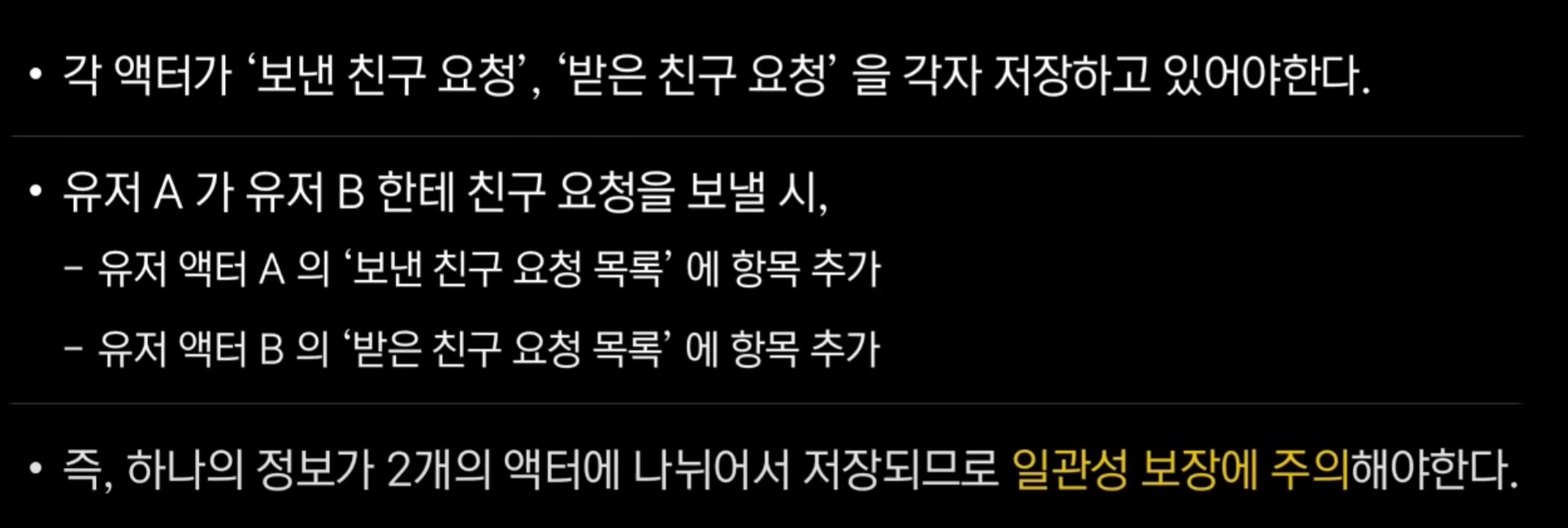
각각의 액터가 친구 요청을 각자 저장하고 있어야해서, 상태 갱신을 잘못하면 일관성이 깨질 수 있음. → 일관성 보장에 주의해야 함.
그렇지만 액터 모델로 구현하면, 친구 관련 정보를 액터 내에 같이 저장하므로 액터가 가지고 있는 다른 액터들에게 자유롭게 접근이 가능하다.
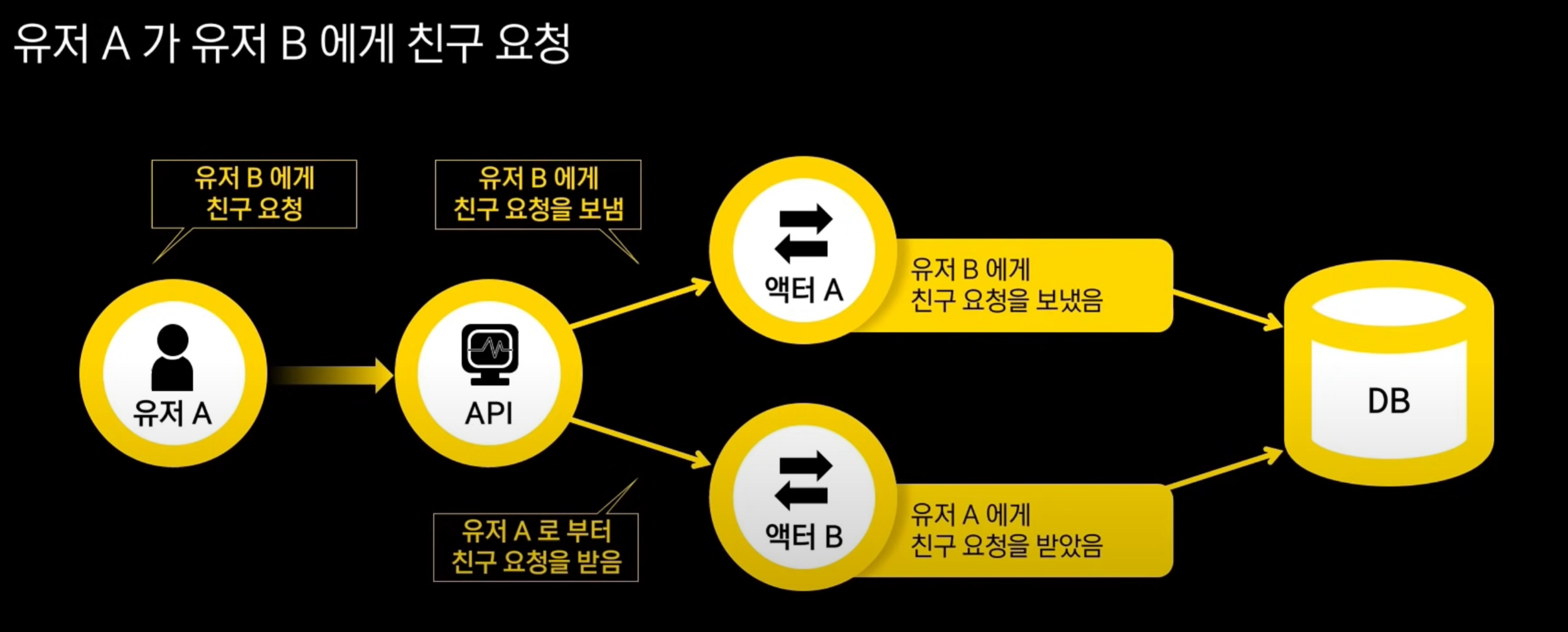
액터 A에서는 유저 B에게 친구 요청을 보냈다는 이벤트 발생, 액터 B도 유사한 이벤트 발생
발생한 이벤트들은 각각 DB에 저장됨.
근데 만약 액터 B로 가는 메세지 송신이 실패했을 경우, 일관성이 깨질 수 있음.
이 문제를 어떻게 해결할 것인가? 다양한 방법이 존재함.
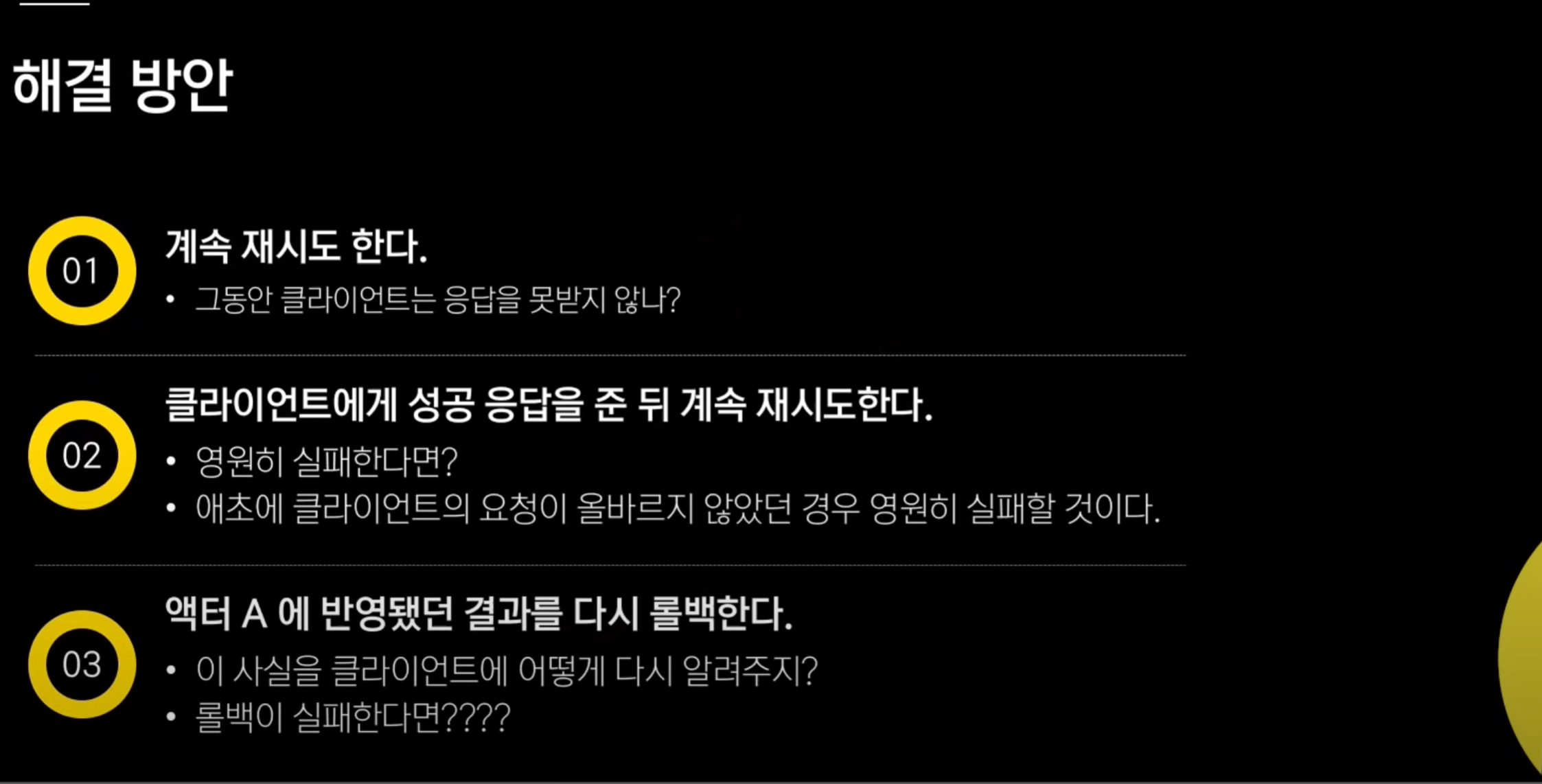
특히 3번은 롤백했다는 결과를 클라이언트에 다시 알려줘야 함.
저런 것들이 최적의 방법은 아닌 것 같다 라는 결론을 내렸다고 함.(저런 방법들을 SAGA 패턴이라고 함.)
- 근데 킹덤에서 SAGA 패턴을 계속 구현하는 것이 비생산적이었다고 함.
- SAGA 패턴이란? : (기본적으로 이벤트 소싱에 기초를 둔 패턴이라고 함)
잠깐 궁금증 : Dynamodb가 SAGA패턴을 지원하나? → 아닌 것 같다. 보통 서버리스와 궁합이 맞는듯.
- 구조적으로 동시에 여러 액터의 상태를 변경시키는게 더 생산적이라고 판단함.
- 그래서 강한 일관성 보장을 위해 2Phase commit을 구현함.
- 준비 단계 → 커밋 단계가 필요
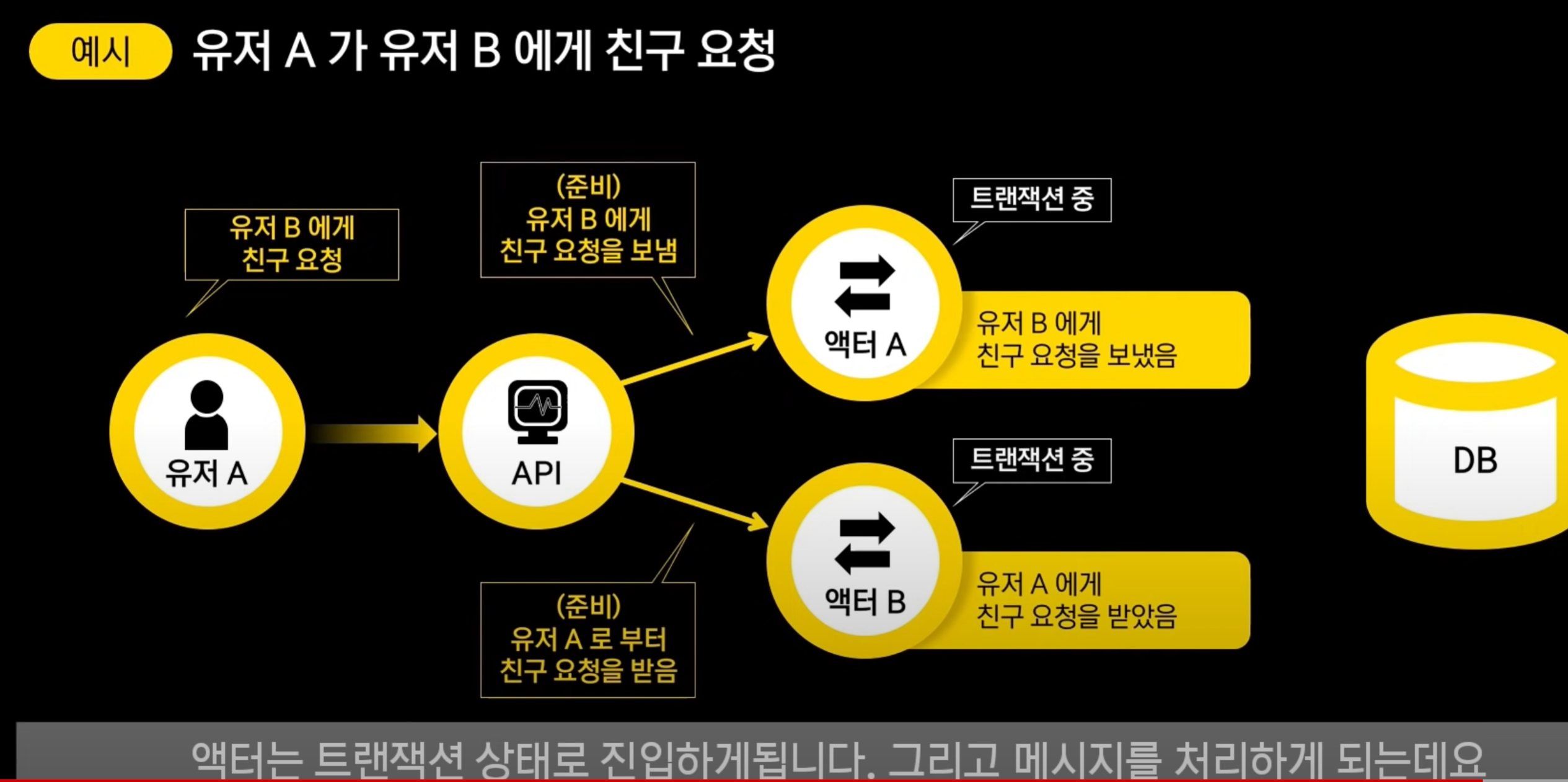
액터에게 준비 요청을 보내면, 액터는 트랜잭션 상태로 진입하게 됨. → 그리고 메세지 처리
여기서 발생한 이벤트들을 DB에 직접 저장하는게 아니라 API에 반환함.
API가 액터 A,B에게 발생한 이벤트들을 모아서 한번에 DB에 저장하는 방식이라고 함. 한번의 트랜잭션으로 DB에 저장하기 때문에 SAGA패턴과는 달리 강력한 일관성 보장이 가능해진다고 함.
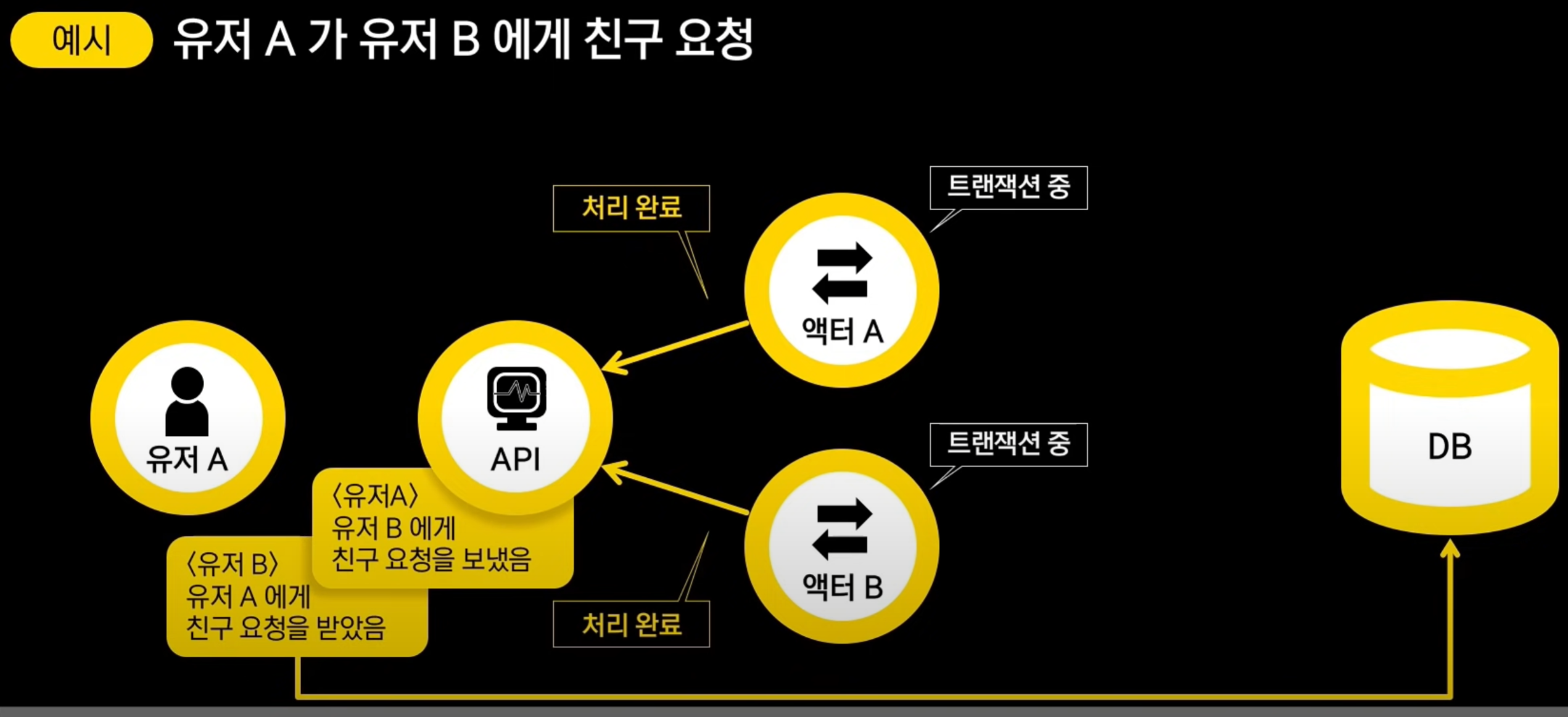
DB 저장 이후 API가 액터 A,B에게 커밋 메세지를 전달하게 되고 액터 A,B는 트랜잭션 상태를 종료하게 됨.
만약에 특정 액터에게 메세지 전송이 실패하면, 나머지 액터가 트랜잭션 대기를 하고있다가 타임아웃이 나게 될 것임. API도 타임아웃 날 수 있음.
타임아웃나면 실패했다고 하고, 이벤트 버리고 클라에 요청 처리 실패 응답함.
실제로는 데드락 같은 케이스를 추가적으로 고려해야 한다고 함.
구현 시 아래와 같은 단점도 있다고 함.

⇒ 필요에 맞는 db 솔루션을 사용하면 큰 문제는 안 될 것 같음.
위에서 얘기한 것으로 구현할 수 없는 것들은 어떻게 할까?

⇒ 이벤트 기반 아키텍쳐로 확장하게 되었다고 함.
킹덤서버는 액터 외에도 다양한 컴포넌트들이 존재하는데, 그 컴포넌트들의 중심에는 이벤트 버스(kafka)가 있다고 함.
예를 들어 조회 API 아키텍쳐를 살펴보자.
- Read 용도의 작업인데 액터에서 정보들을 가져오면 서버에 엑터를 계속 띄우고 있어야 해서 메모리 낭비가 있다고 함.
- 서버, db 부하도 있을 수 있으니 View DB에서 정보를 가져온다고 함.

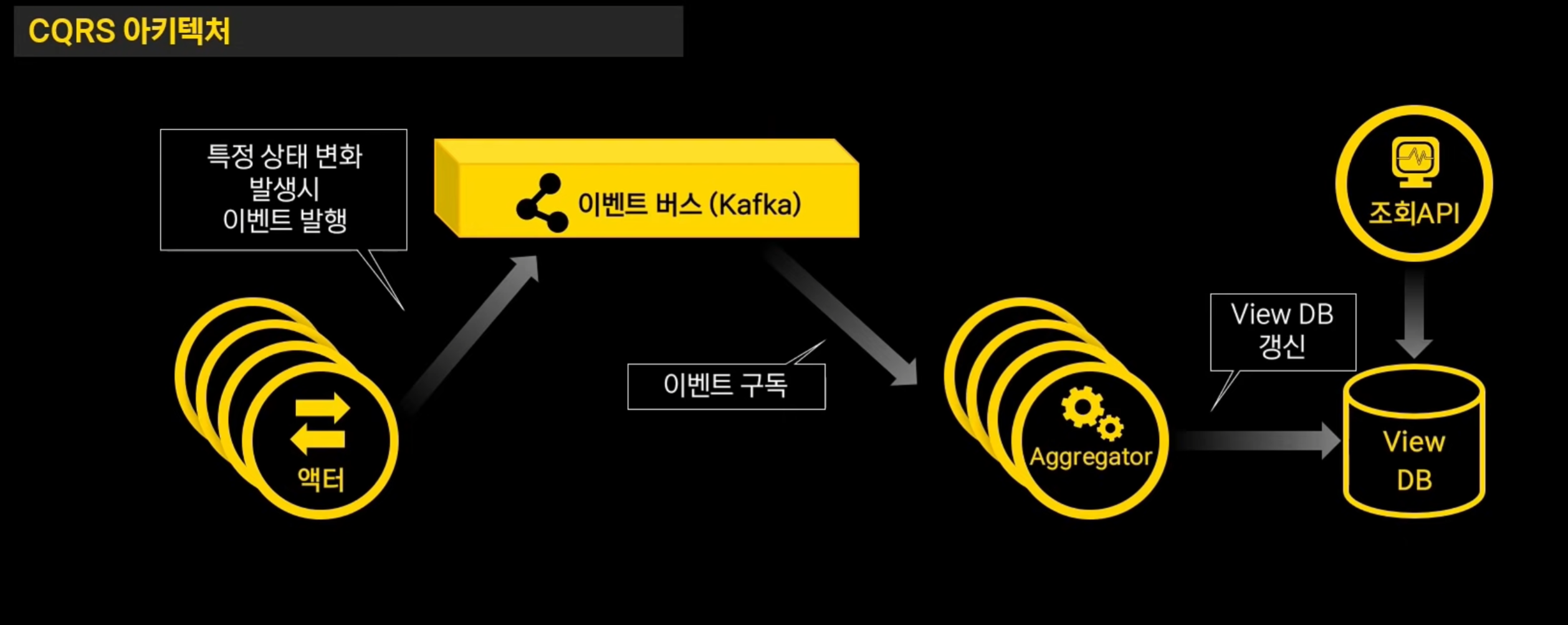
⇒ 여기서 사용한 것이 CQRS 패턴!
CQRS 패턴이란? :
- 명령 처리 책임과 조회 처리 책임을 분리하는 패턴
- https://justhackem.wordpress.com/2016/09/17/what-is-cqrs/
- https://docs.microsoft.com/ko-kr/azure/architecture/patterns/cqrs
- https://www.popit.kr/cqrs-eventsourcing/
- https://youngjaekim.wordpress.com/2016/09/12/최신-기술-cqrs-처음-도입하기/
킹덤의 CQRS 아키텍쳐
PVP 매치메이커
- 일반적인 액터모델로 구현하기 힘들어 별도의 모델로 구현했다고 함.
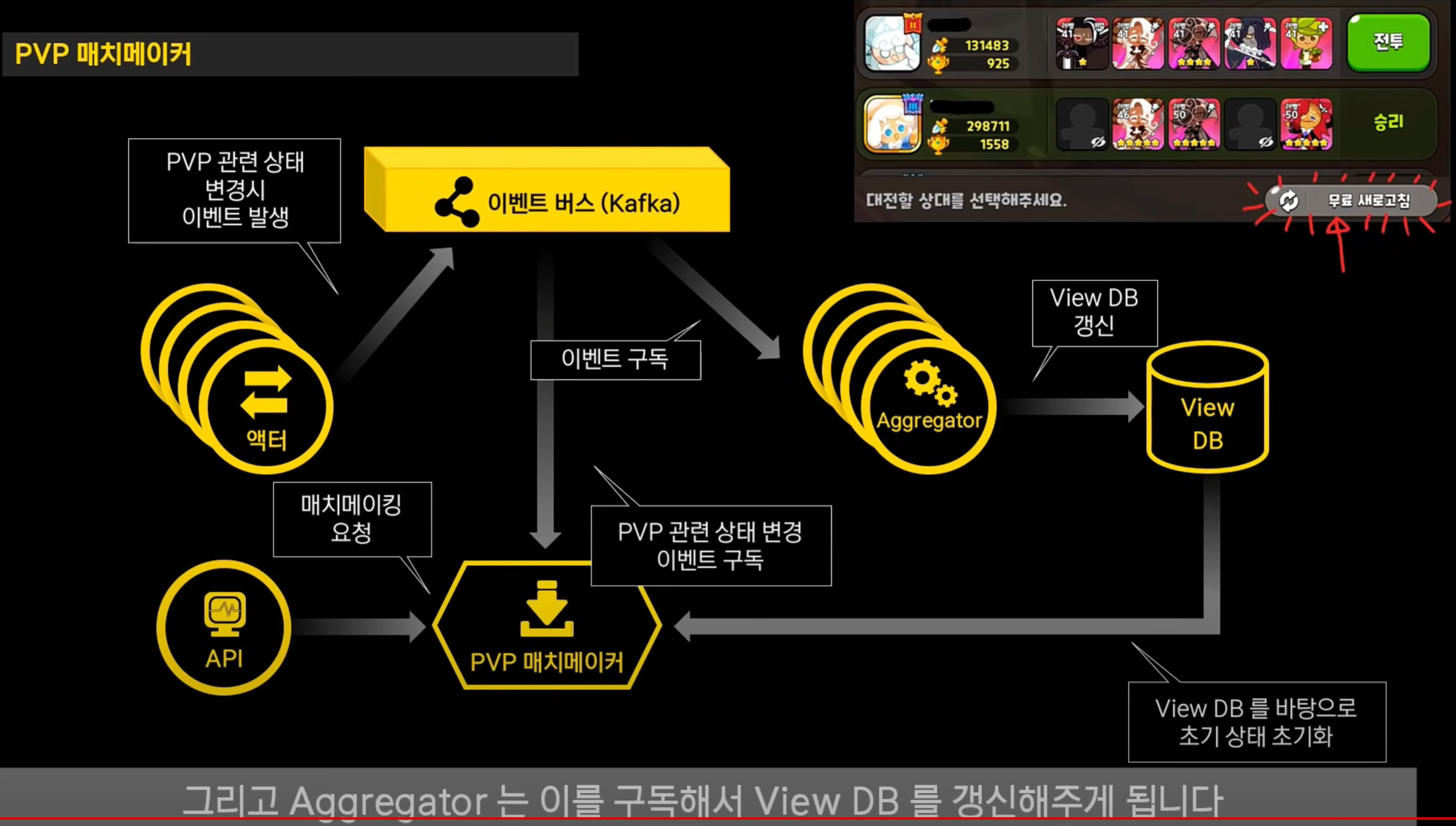
이벤트 발생하면 kafka로 쏴주고, Aggregator는 구독하고 있다가 View DB 갱신
PVP 매치메이커 컴포넌트는 kafka로부터 이벤트 구독해서 상태를 최신으로 갱신
매치메이킹 요청은 pvp 매치메이커 상태를 바탕으로 이루어지게 된다고 함.
전통적으로 OOP에서 RPC나 메소드 콜을 이용해 컴포넌트들이 메세지 통신하는 것에 비해서 이벤트 기반 아키텍쳐가 가지는 장점들이 있다고 함.

특정 컴포넌트가 자신의 상태변화를 여러 컴포넌트에 전달해야 하면,
RPC 기반이면 그 컴포넌트들에게 다 RPC 호출을 해줘야 하는데,
이벤트 기반이면 이벤트 한번 발행하면, 필요로 하는 컴포넌트들이 구독해서 정보를 가져가게 됨.특정 컴포넌트 부하가 심하더라도 큐에 이벤트가 쌓이니까 유실없이 처리 가능(RPC 기반은 Back pressure 구현이 필요함)
백프레셔란? :
다만 실시간성이 중요한 기능의 경우, 이벤트 기반 아키텍쳐가 적절하지 않을 수 있음.
이벤트가 중복 처리 될 수 있는 것도 유의해야 한다.
이벤트들을 idempotent하게 만들어서 중복처리해도 안전하도록 설계해야 함.
결론
이 강연을 통해서 분산 트랜잭션, SAGA패턴, 2PC, CQRS 패턴, 백프레셔, 액터모델, 순수함수, 이벤트 소싱 등등 들어봤지만 제대로 몰랐던 개념에 대해 더 잘 알게되었고,
새로운 개념들도 많이 익힐 수 있었던 게 가장 큰 수확.