관심사의 분리란(Seperation Of Concern) 2편

Dependency Direction
좋은 관심사 분리의 특징은 의존성 방향을 이상적으로 확립하는 것이다.
이상적인 의존성 방향은 잠재적으로 재사용성을 가장 높일 수 있는 엔티티가 의존성의 역할을 가져가는 형태의 consumer↔dependency의 역할을 수립한다.
의존성 방향의 컨셉을 묘사하는 간단한 예가 있다.
비즈니스 컴포넌트와 유틸리티 컴포넌트 사이의 흔한 관계가 그 예시이다.
더 큰 효율성을 위해 캐싱된 데이터를 빈번하게 요청하는 '주문 질의 프로세스'를 제공하는 시스템을 생각해봐라.
주문 질의 캐싱을 촉진하기 위해, 캐싱 유틸리티 컴포넌트는 주문 질의 프로세스 나머지 부분으로부터 캐싱 관심사를 분리하는 방향으로 개발될 수 있다.
Figure8은 2개의 컴포넌트를 가진 해당 시스템을 묘사하고 있다.
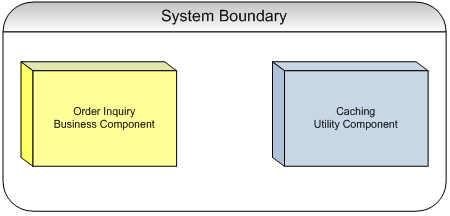
캐싱 기능은 주문 질의 프로세스 보다 더 포괄적인(more generic) 행동이기 때문에, 캐싱 컴포넌트는 둘 중에 잠재적인 재사용성이 더 높다.
그러므로, 이 경우에서 최고의 의존성 방향은 비즈니스 컴포넌트 → 유틸리티 컴포넌트가 될 것이다.
이 의존성은 Figure9에 묘사되어있다.
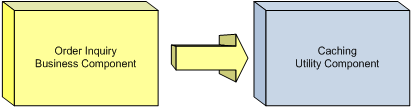
이런 관계는 캐싱 컴포넌트가 비즈니스 문의 프로세스에 대한 지식 없이 유지될 수 있게 해줘서, 미래의 프로세스들에 의해 재사용될 수 있게 한다.
Data Concerns
관심사의 분리 법칙을 데이터에 적용하는 것은 시스템이 관리하는 정보를 적절하게 모델링하는 것을 나타낸다.
데이터 모델링 관점은 객체지향 및 데이터베이스 설계 모두에 적용하지만, 이번 논의에선 객체지향 데이터 관심사에 대해 집중하려고 한다. 왜냐하면 데이터베이스의 주요 니즈는 형식이 기능을 뒤따르기 위해 필요한데서 오기 때문이다.
객체 모델 내에서 데이터를 구성할 때, 드러난 정보는 그걸 표현하는 엔티티에 내제되어 있어야 한다.
예를 들어, 제품을 소비자에게 판매하는 시스템을 생각해보자.
제품을 정의하는 객체는 소비자와 관련된 정보를 포함하지 않아야 한다. 제품은 본질적으로 제품을 구매하는 사람들과 관련이 없기 때문이다. 개념적으로 제품 정보와 소비자를 결합하는 주문 객체를 만드는게 더 나은 접근이라고 할 수 있다.
이 접근은 미래에 제품 객체를 다른 프로세스들이 재사용하게 해준다.(그 프로세스들은 소비자 정보와 관련이 없을 것이다.)
게다가 다른 맥락들 내에 있는 데이터 모델의 잠재적 재사용을 고려하면, 데이터의 직관적인 구조는 매우 복잡한 시스템을 유지 보수할 때 유익하다.
예를 들어, 새로 들어온 엔지니어가 이미 메모리에 들어 있는 제품 객체와 결합한 특정 부분의 시리얼 숫자에 접근하는 일을 맡았다고 해보자.
그 엔지니어는 특정 제품 파트를 찾으려고 시도할 것이고, 그 다음 "SerialNumber"와 관련된 부분이나 비슷한 이름을 가진 프로퍼티를 검사하려 할 것이다.
그 엔지니어는 제품 객체가 가리키는 제품 숫자-시리얼 숫자 형태를 가진 딕셔너리 같은 무언가를 찾으려고 생각하지 못할 것이다. 왜냐하면 그건 그 데이터의 자연스러운 표현이 아니기 때문이다.
이 문제는 시리얼 숫자(제품의 일련번호)를 가진 손목시계를 찼기 때문에 그 제품의 시리얼 넘버를 가지게 된 사람의 케이스를 고려하는 것과 유사하다.
그러나 그 데이터의 본질적인 구조가 정보 탐색을 위해 효율적인 메커니즘을 표현하지 못 할 때가 있다.
예를 들어, 전체 구리 요소들의 개수를 알아내기 위해 빈번하게 검사할 필요가 있는 유난히 복잡한 제품 객체가 있다고 하면,
그 객체는 그 객체와 결합된 원소들을 교차 참조하거나 검사하는 것을 통해선 효과적으로 다뤄지지 않을 것이다.
이런 경우에는 본질적인 모델링 그 자체로는 충분하지 않고, 전문화된 니즈를 충족하는 개념적 타입으로 보충해야 객체 모델의 온전함이 유지될 수 있다.
만약 제품의 결합이 한번 결합되고 고정적으로 유지된다면, 예를 들어서, 제품의 귀금속 정보(ProductPreciousMetalManifest)를 나타내는 개념적 모델은 제품 정보와 동등한 수준으로 결합될 지 모른다.
만약 제품의 결합이 빈번하게 변경되고, 결합 프로세스들이 집중화 된다면, 귀금속 정보는 이 프로세스의 한 부분으로 갱신 될 지 모른다.
그렇지 않으면, 전문화된 컴포넌트(PreciousMetalDetector)가 제품의 귀금속 정보를 동적으로 리턴하게 처리해야 할 것이다.
첫번째 예시로 보면, 본질적 모델로부터 개념적 필요를 분리하면 다른 프로세스들이 본질적이지 않은 특성의 오버헤드를 초래하는 것 없이 그 모델을 재사용 할 수 있는 이점이 있다. 그리고 그 모델은 쉽게 유지보수 하는게 유지 될 수 있다.
Behavior Concerns
행위 분리는 시스템 프로세스들을 관리 가능하고, 재사용 할 수 있는 논리적 코드 단위로 분리하는 것을 나타낸다.
행위 분리는 관심사 분리의 가장 근본적인 형태이다.
객체지향 시스템 내에서 잘개 쪼개진 행위들은 메소드를 사용해서 분리한다. 반면에 덩어리 단위로 쪼개는 행위는 객체, 컴포넌트, 애플리케이션, 서비스를 사용해서 분리한다.
데이터 분리와 마찬가지로, 캡슐화된 행위는 그 행위가 포함하는 경계에 내재 되어 있어야 한다.
예를 들어, CreateCustomer()라는 메소드는 새로운 customer를 생성하는 것과 관련된 행위만 포함해야 한다. 새로운 소비자의 주문을 처리하는 것은 기대하지 않는다. 비슷하게, ProductAssembler라는 컴포넌트는 assembly of products에 관련된 행위와 데이터만 포함하는걸 기대한다. 소비자와 관련된 행위나 데이터를 포함하는 것은 기대하지 않는다.
좋은 행위 분리를 달성하는 것은 반복적인 프로세스이다. 시스템의 주요 행위는 일반적으로 설계 단계 동안 만들어지지만, 시스템 설계의 구체적 구현은 관심사들이 잘개 쪼겨져 명백해지는 몇 번의 반복적인 리팩토링을 필요로 한다.
행위를 구성할 때는 아래의 목표들이 요구된다.
- 기능의 중복을 제거하라.
- 유지보수 가능한 사이즈로 작업의 범위를 제한하라.
- 가지고 있는 경계를 묘사하는 것으로 작업의 범위를 제한하라(객체가 해야 하는 책임의 범위만 묘사하는 식으로 제한하라.)
- 행위가 경계를 본질적으로 드러낼 수 있게 작업 범위를 제한하라.
- 외부 의존성을 최소화해라
- 잠재적인 재사용성 고려를 최대화해라.
Extending Concerns
확장은 기존의 관심사 세트에 새로운 행위를 추가할 수 있는 관심사 분리의 전략이다.
확장은 시스템에 내제된 행위가 아니거나, 시스템의 코어 기능 세트의 부분으로서 현실적으로 포함되기 어렵고, 목표하는 시스템에 추가될 수 없는 '원하는 행위(desired behavior)'인 기존의 관심사들을 향상시키기 위해 사용된다.
Figure 10은 목표 시스템에 의존성 관계를 확장하는 것을 묘사하는 그림이다.
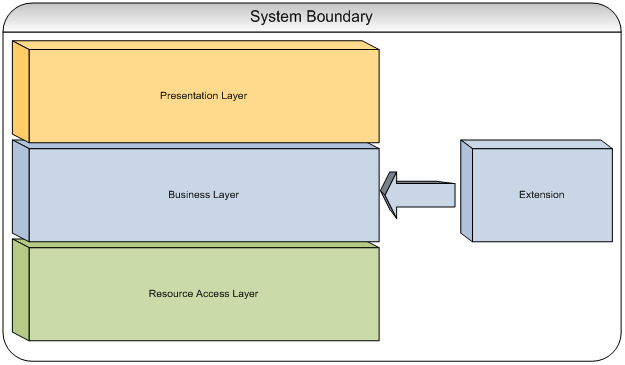
확장은 핵심 이벤트들의 알림에 호응하여 목표 시스템과 상호작용한다.
확장에 의한 행위 예시는 목표 시스템 내에서 새로운 views나 controls 표현, 일반적인 processing의 변화, 데이터 변화 등이라고 보면 된다.
확장은 일반적으로 호스트 add-in 형태를 취하며, 전형적으로 config나 dynamic discovery process를 통해 등록된다.
여러개의 클라이언트 애플리케이션이 기업 내에서 유지 보수 될 때, 하나의 클라이언트의 확장에 의해 제공되는 행위가 다른 클라이언트에게 마찬가지로 추가되는건 가치 있다는걸 발견할 수 있다.
만약 확장이 타겟 어플리케이션에 고도로 커스텀 되어있고 상대적으로 간단한 행위를 제공한다면, 가장 좋은 행동 방침은 새로운 애플리케이션에 그 기능을 복제하는 것이다.
그러나 확장의 행위가 크기와 복잡성이 상당하다면, 일반적으로 엔터프라이즈 서비스를 통해 행위를 제공하는게 더 적절할 수 있다.
만약 서비스가 제공하는 행위가 호스트 시스템의 핵심 의존성으로 포함하는게 부적절하다면, 새로운 확장은 애플리케이션을 대표하여 서비스와 상호작용하게 개발 될 수 있다.
Delegating Concerns
관심사 위임은 하위 컴포넌트에게 행위를 수행하는 책임을 할당하기 위한 프로세스를 뜻한다.
이 전략은 실행으로부터 책임에 대한 관심사를 분리하고, 상세 구현이 외부 조건에 따라 다양할 수 있는 컴포넌트를 디자인하기 좋다.
이 전략을 사용하면, 컴포넌트들은 특정 혹은 전체 데이터 요청과 메소드 호출을 특정한 방법으로 그것들을 수행하게 설계된 다른 컴포넌트에게 대신 처리하게 전달한다.(proxy)
예를 들어, 현재 유저에 할당된 역할 리스트를 리턴하게 설계된 컴포넌트는 local XML 파일이나 데이터베이스, 혹은 원격 서비스에서 역할을 검색하게 설계되어있는 1개 이상의 하위 컴포넌트에게 요청을 위임한다.
Figure 11은 다양한 데이터 소스를 가진 컴포넌트에게 권한 관심사를 위임하는걸 묘사한다.
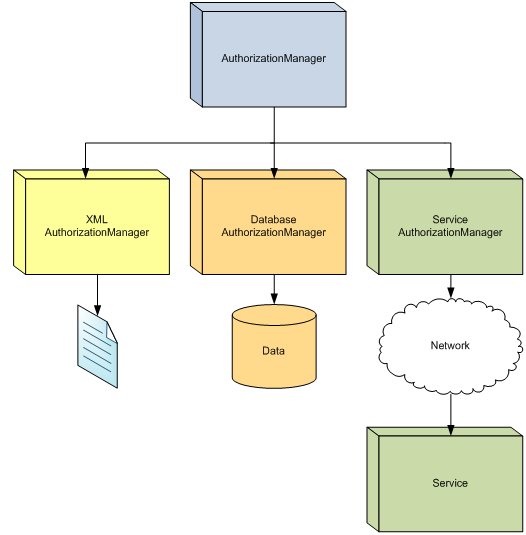
위임은 외부에서 수행되게 컴포넌트의 행위를 분배할 수 있는 Strategy Pattern, Plug-in Pattern, Microsoft Provider Model, 다른 변형 패턴 등을 사용해 동작될 수 있다.
Inverting Concerns
IoC로 더 잘 알려진 관심사 뒤집기는 설정해놓은 경계 밖의 관심사를 이동시키는 프로세스를 의미한다.
몇몇은 관점 분리 영향, 필수적이지 않은 프로세스 최소화, 특정 추상 전략과 컴포넌트 분리, 인프라 컴포넌트로 책임 이동시키기를 포함하는 관심사 뒤집기를 사용한다.
몇몇 특정 애플리케이션은 하드웨어 상호작용, 워크 플로우 관리, 등록 프로세스, 의존성 획득에 적용되는 책임을 완화하는 것을 포함하는 관심사 뒤집기를 사용한다.
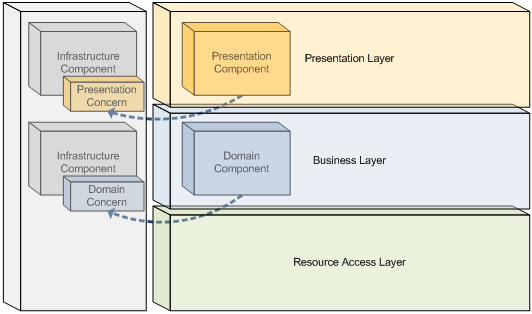
Figure 12는 presentation 컴포넌트와 domain 컴포넌트가 인프라 레벨 컴포넌트로 이동된 관심사를 가지게되는 관심사 뒤집기 프로세스를 묘사한다.
관심사 뒤집기의 예시는 Template Method 패턴 사용에서 볼 수 있다.
이 패턴은 상속을 통해 variation을 허가 하기 위해 프로세스 행동을 일반화하는데 사용된다.
기존 컴포넌트에 이 패턴을 사용할 때, 원하는 프로세스가 수행하는 단계는 일반화 될 수 있고, base 클래스로 캡슐화 될 수 있다.
그러면 기존 컴포넌트는 새 base 클래스를 상속받고, 특정 행동만 유지 하게 된다. 다른 타입들은 다양한 구현을 제공하기 위해 base 클래스를 자유롭게 상속받을 수 있다.
이 로직은 알고리즘 시퀀스 관심사를 뒤집는 하나의 예시가 된다.
관심사 뒤집기의 다른 예시는 인터랙티브 콘솔 애플리케이션을 GUI 애플리케이션으로 변환할때 관측된다.
전형적인 인터랙티브 콘솔 애플리케이션은 유저가 정보를 입력하기 위한 프롬프트가 뜨고 데이터가 입력되는걸 기다리는 메인 루프를 제공한다.
GUI 애플리케이션으로 변환될 때, 프로그램의 메인 컨트롤은 일반적으로 인프라 컴포넌트가 제공한다. 그리고 유저 인터랙션 알림은 Observer 패턴을 사용해 달성한다.
이 행위는 애플리케이션 인프라에 의존하거나 이런 관심사를 위한 환경을 호스팅해서 유저 인터랙션 프로세스의 메인 컨트롤을 뒤집는다.
의존성 주입은 외부 의존성을 얻는 것과 관련된 관심사 뒤집기 용어이다.
이 용어는 뒤집기 형태와 관련된 프레임워크 클래스 행동을 더 명확하게 묘사하기 위해 구상되었다.
의존성 주입의 목표는 의존성이 경계에 있는 핵심 관심사를 얻는 방법에 대한 관심사를 분리하기 위한 것이다.
의존성 주입은 컨텍스트에 따라 의존이 다양해지는 컴포넌트가 그 의존성들을 받게 되는걸 가능하게 함으로써 재사용성을 향상시킨다.
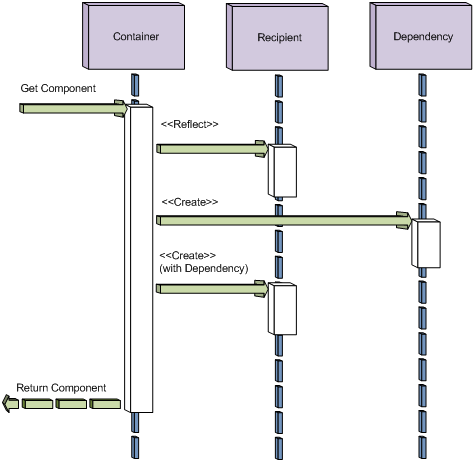
의존성 주입 프로세스는 일반적으로 컨테이너, 의존성, 수신자 역할을 포함한다.
컨테이너 역할은 수신자 컴포넌트에게 의존성을 할당하는 책임이 있는 컴포넌트가 얻게 된다.
컨테이너는 일반적으로 수신자와 의존성 컴포넌트들을 만들어주기 위한 Factory Pattern 을 사용해 구현된다.
수신자 역할은 컨테이너로부터 의존성을 수령하는 컴포넌트가 얻게 된다.
수신자는 컨테이너가 지원하는 strategy를 사용하는 의존성들을 선언하기 위해 필요하다.
의존성 정보를 결정하는 strategy들은 일반적으로 하나 이상의 수신자의 멤버 타입을 검사하기 위해 리플렉션을 사용한다. 그리고 암묵적으로나 명시적으로 의존성들을 구체화하기 위해 attribute나 annotation 사용을 필요로 한다.
이런 역할들을 나타내는 시퀀스 다이어그램이 Figure13에 나타나있다.
의존성 주입을 사용하는 예시는 Factory 나 Factory Method 패턴들을 사용하는 것 대신에 비즈니스 컴포넌트로부터 캐싱 기능을 추상화하기 위한 사례가 있다.
의존성 주입을 사용해 캐싱 컴포넌트를 수신자에게 전해줌으로써, 수신자는 캐싱 컴포넌트를 구체적인 팩토리에 결합시키는 것 없이 느슨하게 결합 시키게 된다.
의존성 주입을 사용하는 또 다른 예시는 Singleton Pattern 을 사용하는 것 대신에 만들어진 캐싱 컴포넌트들의 숫자를 컨트롤하는 것이다.
주입은 애플리케이션이 생애주기 동안 오직 하나의 인스턴스만 사용하는걸 보장한다. 혹은 수신자가 컴포넌트의 인스턴스들을 받는 권한을 컨트롤 한다.
또한 주입은 그들의 소비자와 함께 테스트 되는 singleton 객체들을 필요로 하는게 아니라 가짜(mock) 의존성을 사용하게 해줌으로써 그들이 사용하는 의존성을 고립시킨 환경에서 컴포넌트들을 테스트하는 능력을 향상시킨다.
의존성 탐색이나 객체 생성 관심사를 추상화 하기 위해 Factory, Factory Method, Abstract Factory, Singleton, Plug-in, Service Locator 같은 패턴을 사용하는 컴포넌트들은 의존성 주입으로 추가하거나 그것으로 대체하기 위해 고려되는 좋은 후보자들이다.
위에서 얘기한 패턴이나 다른 패턴들과 협력하거나 그들을 대체하기 위해 의존성 주입을 사용함으로써, 컴포넌트 소비는 완전히 특정한 추상화 전략으로부터 추상화될 수 있다.
The Exaggeration Exercise
설계 선택의 부정적인 결과, 특히 확장성과 재사용성에 관련된 선택은 시스템이 만들어지고 오래 지나기 전까지는 명백해지지 않는다.
확장성과 재사용성의 문제는 보통 관심사 분리 원칙을 고수하지 못한데서 기인한다.
관심사를 최적화하는데 도움을 줄 수 있는 프로세스는 과장된 상황 아래에서 적용됐을 때 설계의 영향을 고려한다.
이 행동을 통해, (가정해서 말하면)이 시스템을 사용하는 건 설계 접근 측면에서 잠재적인 약점을 드러내기 위해 시스템의 알려진 기대치들을 넘어서 과장되어 있다.
예를 들어, 2개의 기존 시스템에 사용되는 객체 모델을 설계할 때, 하나의 시스템에서 객체 모델이 50개의 시스템에 공유된다면 무슨 결과가 나올지 고려해야 한다.
설계 사용을 부풀려보면, 형편없이 조직된 책임들이 파악되기 쉬워질 것이다.
이 행위를 검증하기 위해 아래의 예시를 생각해보자. 예시는 새로운 종합적 CRM 시스템 제작에 관한 것이다.
IT 부서는 커스텀 CRM 앱을 만들어달라는 요청을 받았다. 그 앱은 각각의 개발팀들이 특정 기능들로 특화된 모듈을 개발하게 되는 구조다.
기업 내 주요 고객 관련 세그먼트는 세일즈, 빌링, 테크니컬 서포트 팀이 될 것이다. 각각의 세그먼트에 대한 기능을 지원하기 위해 할당된 여러개의 개발팀이 있을 것이다.
그들은 애플리케이션이 고객들을 다수의 기준들(이름, 주소, 전화번호, 주문 번호, 제품 일련 번호 등)로 질의하는 메인 스크린을 가져야 한다고 요청 받았다.
그러나 결과로 나올 화면들이나 워크플로우들은 그 비즈니스 기능들이 정해진 시간에 완료되는지에 따라 달려있다.
예를 들어 고객 검색 기준을 제출하자마자, 세일즈 유저들은 과거 구매 트랜드, 신용점수, 제안된 연쇄 판매 스크립트이 관계된 화면이 보일 것이다
반면에 빌링 유저는 고객 구매 히스토리, 청구서 분쟁 히스토리, 잔고를 보여주는 화면이 보일 것이다.
첫번째 분석은 총 5개의 다른 검색 기준에서 나오는 3개의 워크플로우 변화의 총합을 드러낸다. 그리고 모든 세그먼트에 필요한 정보를 가지고 있는 3개의 백엔드 시스템이 있다.
왜냐하면 변형정도가 낮고, 선택이 메인 화면, 고객 검색 기능과 워크플로우, 검색 모듈 안에 있는 워크플로우 시작기능에서 중점적으로 이루어지기 때문이다.
새로운 검색 기능이 추가되는 것은 검색 모듈 개발팀의 변경이 필요로 한다. 그러나 이런 필요는 빈번하지 않을 것 같다.
이런 디자인 선택을 과장해서 적용한다는 것은 만약 비즈니스의 세그먼트 수나 백엔드 시스템이 50개까지 증가한다면 어떤 결과가 뒤따를지를 고려하는 것이다.
검색 기능과 워크플로우 시작 기능을 중앙화하는 것의 결과로 이런 관심사 범위의 증가는 또한 검색 기능 개발팀의 책임과 일거리를 늘리는 것이다.
이 책임과 일거리는 이런 관심사들과 관계된 모든 새로운 기능과 변화의 범위산정, 분석, 디자인, 코딩, 테스팅 등을 포함한다.
결국, 이건 검색 모듈팀이 필요한 개발 리소스의 수를 늘릴 필요가 있게 만든다.
또한 이런 관심사들의 통합이 야기하는 동일한 초기 가정이 검색 모듈을 만드는 다른 설계 결정에 도움을 줄 수 있다는 것이다.
이건 새로운 관심사를 다루기 위해 특정 레벨의 내부 재설계를 필요로 하는, 책임들이 증가하는데 쉽게 도움을 주지 못하는 설계 선택들을 야기하고 있다.
이런 과정을 통해 관측되는 중요한 문제는 검색 팀에게 요구되는 일거리 양이 시스템이 지원하는 워크플로우나 비즈니스 세그먼트의 양과 비례적으로 늘어난다는 것이다.
초기 솔루션은 니즈가 증가하는 것만큼 스케일이 커지지 않는다는 사실은 관심사가 시스템 도처에 적절하지 못하게 분산되어있다는걸 알려주는 것이다.
검색 기능과 그에 따른 워크플로우를 통합하는 결정은 각각의 use case 사이에 유사점을 인식한 결과이다. 동일한 고려사항으로 주어지지 않은 것은 각각의 use case가 특화된 방법으로 다루어져야 한다는 사실이다. 그리고 가능성의 수가 정확한 경계를 가지지 않는다는 사실이다.
검색 스크린은 많은 모듈들에 대한 중앙적 기능을 제공하기 때문에 내재되어있는 인프라 관심사를 소유할 수 있다.
그러므로 모든 모듈에 공통적인 행위를 제공하는 것을 기대해야 한다. 그러나 각각의 케이스에 대한 세부사항은 공통적이지 않고, 각각의 상대적인 모듈의 내제된 관심사를 고려할 수 있다.
내제된 책임을 인식하자마자, 대체적인 접근법은 공통의 관심사를 통합하기 위해 프레임워크 개발을 포함한다. 그러나 각각의 도메인 특정한 관심사의 배포 또한 가능해진다.
이런 접근은 각각의 모듈이 가능한 검색 기준을 등록하고, 상응하는 워크플로우를 호출하기 위해 capabilities를 제어하는 기능을 제공하는 add-in을 제공함으로써 성취될 수 있다.
프레임워크는 검색 기준의 통합적인 관점을 보여주는 책임을 가지게 될 것이다.
그리고 각각의 검색 기준과 그에 상응하는 워크플로우 핸들러를 연관짓는 포괄적인 인프라를 제공하는 책임을 가지게 된다.
이 접근을 사용함으로써 검색 모듈은 무제한의 use case를 수용하기 위해 설계될 수 있다.
과장해서 행동하는 것이 매우 확장가능한 설계를 만드는데 유용하긴 하지만, 이건 오직 최적의 관심사 분리를 성취하기 위해 주요한 목표의 부산물이다.
과장해서 행동하는 것은 기저에 있는 잠재적인 문제 증상을 테스트하기 위해 환자의 온도를 체크하는 의학적 관습과 비교할 수 있다.
이 행동은 잠재적인 디자인의 확장성 관점을 조사함으로써 관심사 분리와 관련있는 문제를 발견하기 위해 시도한다.
디자인의 실제 스코프를 과장하는 것을 통해, 작은 문제들은 더 쉽게 확인되기 위해 확장된다.
한번 확인되면, 이것은 어떤 액션의 코스가 취해져야 하는지 결정된다.
Separation Anxiety
관심사 분리 법칙을 적용하는 것은 단지 앱의 도메인 관심사를 얘기하는 것을 넘어서 특정 레벨의 복잡도를 앱에 가져오는 고급 컨셉과 생각들을 포함할 것이다.
이런 프로그래밍 테크닉에 익숙치 않은 개발자들에겐 이 반응은 디자인 스킬의 개인 레퍼토리를 더하는 기회를 넘으며, 가능한 가장 편리한 방법으로 일을 해결할 수 있게 포함된 추가적인 양의 복잡도에 대한 부정적인 반응을 넘어서 열광적인 흥분 스펙트럼 내에서 속한다.
이런 테크닉들은 비숙련된, 혹은 좀 더 전술적인 마인드를 가진 개발자들이 그들이 처음 배울 때 가졌던 좌절감에 기반해 "너무 복잡하거나" "오버 엔지니어링을 하거나" 같은 디자인에 특화되게 만든다. 그리고 매일매일 그런 아키텍쳐를 통해 행동하게 한다.
더군다나, 즉각적인 만족감을 위해 프로젝트 매니저, 프로덕트 매니저, 상위 레벨 매니지먼트, 마케팅 혹은 엔드 유저들에게서 오는, 항상 존재하는 압박이 종종 있다. 그 만족감이란 사려깊은 설계를 넘어 편의를 보상하고 권장하는 경향이 있다.
이러한 상태들은 단지 기술적인 문제를 해결하는 것을 넘어 좋은 설계를 개발하는데 장애물로 존재할 수 있다.
관심사 분리를 촉진하는 설계가 종종 애플리케이션에 복잡함을 더할 수 있지만, 그것들은 또한 일반적으로 부족한 관심사 분리와 연관된 복잡함을 제거하기도 한다는 걸 주목해야 된다.
많은 앱에서 트레이드 오프는 정돈된 복잡함과 정돈되지 않은 복잡함 사이에 있다.
적절한 양의 관심사 분리를 드러내지 않은 앱들은 부분을 이해하기 전에 종종 전체를 이해할 필요가 있기 때문에 배우기 어렵다. 그리고 유지보수하고 확장하기도 어렵다.
매우 복잡하지만 형편없이 모듈화 되어있는 앱들은 또한 개발 팀원의 높은 이직률을 야기할 영향을 가지고 있다. 혹은 변화를 싫어하고 그들의 커리어를 그 조직 내에서 필수적으로 있어야 할 미로의 주인이 되게 만드는걸 추구하는 사람들을 끌어들인다.
개발팀들은 확실히 복잡함을 위한 복잡함을 추구하면 안된다.(그게 불명료함 콘테스트에 들어가지 않는다면) 그러나 발전된 설계 컨셉이 복잡함을 피하는 것과 동일시하는 개념은 떨쳐져야 한다.
Conclusion
간단하게 관심사 분리 법칙의 목표가 질서라는걸 새겨라.
시스템 내에 요소들을 단일하고 유니크한 목적과 부합되게 보장함으로써, 복잡한 시스템들은 생산성과 유지보수성을 최대로 설계 될 수 있다.
질 읽고 갑니다.