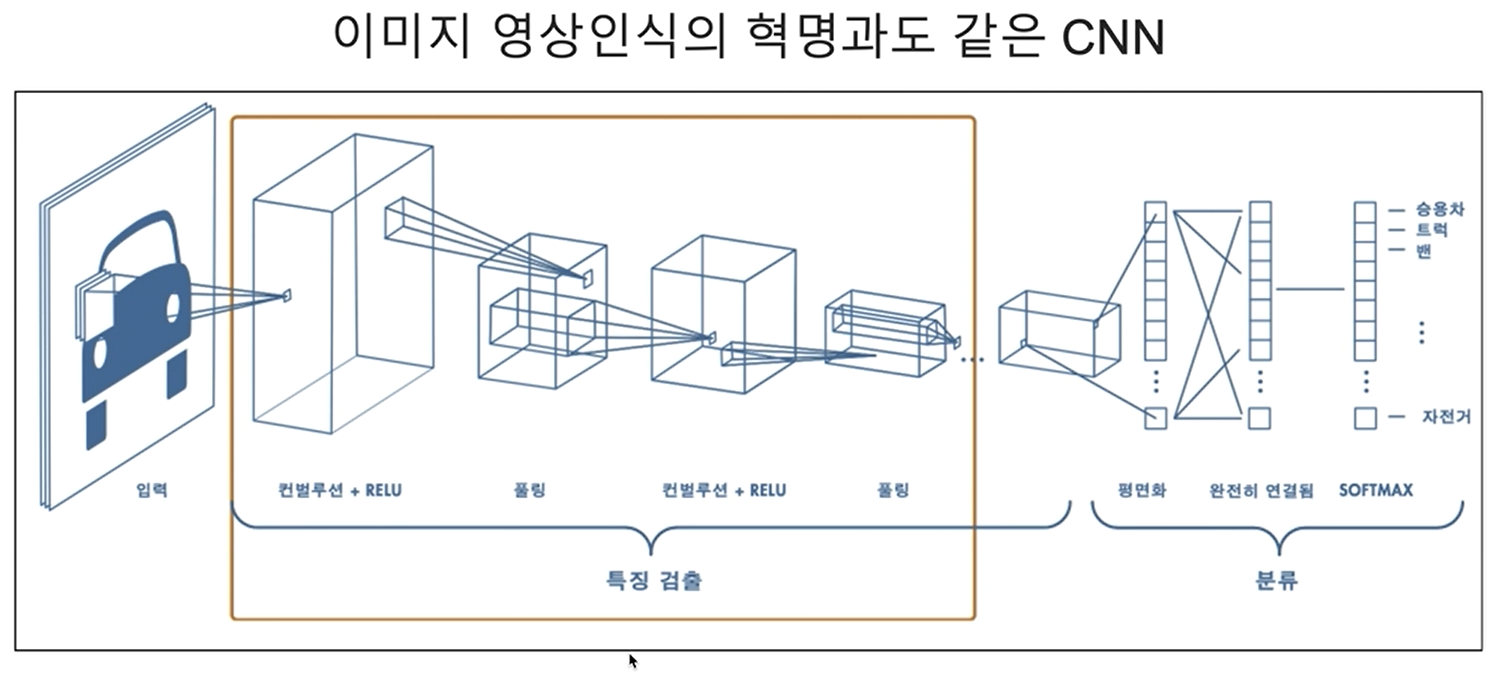
CNN에 대한 것은 https://velog.io/@seaurchin2/신경망과-CNN 에서 정리되어있습니다.
이 글은 CNN을 이용해서 직접 적은 손글자를 구분하는 것을 해볼 예정

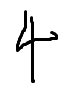
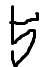
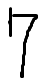
미리 그림판에 숫자들을 적어서 따로 PNG 파일로 저장해놓으면 준비는 완료되었다.
0. 시작하기에 앞서
먼저 그림판에 적은 숫자들은 학습 데이터가 아닌, 테스트 데이터이다. 그렇기에 내가 적은 손글자가 아닌 다른 데이터로 학습을 시켜야 하는 점이 있다.
그리고 지금 내가 적은 손글자를 모델이 바로 알아볼 수 없다. 그렇다면 이 손글자를 모델이 테스트 할 수 있게 변형시켜야 한다.
이 두가지 점이 내가 해결해야 하는 멈이다.
1. 데이터 학습
데이터는 tensorflow의 keras에서 데이터를 가져올 예정이다.
import tensorflow as tf
(data_train, label_train), (data_test, label_test) = tf.keras.datasets.mnist.load_data()으로 데이터를 가져온다. 이때, tensorflow의 버전에 따라 (1.0 / 2.0) 불러오는 방법이 다르다. 나는 버전이 2.0이기에 이 방법으로 가져왔다.
그런 다음에 데이터를 확인해보면
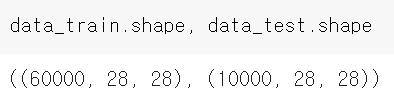
데이터를 정상적으로 불러온 것을 알 수 있다.
그 다음 데이터를 data와 label로 구분해주는 작업이 필요하다.
data=np.concatenate((data_train,data_test),axis=0)
label=np.concatenate((label_train,label_test),axis=0)
이 작업을 완료해주면

data와 label로 구분이 된 것을 알 수 있다.
2. CNN 모델 제작
그 다음으로 진행할 것은 CNN 모델을 제작할 것이다.
모델 이름은 알기쉽게 CNN으로 할 예정이다.
먼저 불러와야 할 라이브러리가 많기에, 그것들을 먼저 불러와준다.
from sklearn.model_selection import train_test_split
train_input,test_input,train_output,test_output=train_test_split(data,label,test_size=0.2)
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Conv2D #kernel
from keras.layers import Flatten
from keras.layers import MaxPooling2D #pooling위는 학습 데이터의 input과 output을 불러온 뒤, 데이터들을 train_test_split()을 통해 넣어준다
아래는 모델 제작을 위해 불러온 라이브러리들이다.
이중 Conv2D와 FLatten에 대해 간단히 설명하자면, Conv2D는 Convolution Layer를 사용할 때 불러오는 라이브러리로, 옆에 Kernel라고 적힌 것처럼 커널로 사용할 수 있다.
Flatten 같은 경우 데이터 평탄화를 위해 사용해준다. 만약 데이터가 2차원 배열로 생성되어있으면 1차원 배열로 평탄화를 시킬 수 있다.
그 다음 모델을 생성해준다.
Cnn = Sequential()
Cnn.add(Conv2D(3, input_shape=(28,28,1), kernel_size=(3,3),padding="same", activation="relu"))
Cnn.add(MaxPooling2D(2))
Cnn.add(Flatten())
Cnn.add(Dense(200,activation="relu"))
Cnn.add(Dropout(0.2))
Cnn.add(Dense(100,activation="relu"))
Cnn.add(Dense(10,activation="softmax")) #0~9
Cnn.compile(loss="sparse_categorical_crossentropy",metrics="accuracy",optimizer="adam")간단히 정리하면
- 컨볼루션 레이어 사용
- Max pooling을 사용하여 pooling layer 선언
- 입력층은 ReLU 사용, 은닉층은 1층으로 ReLU 사용
- 출력층은 softmax 사용
- compile시 adam 사용
이렇게 모델 생성 이후 fit을 한 번 해주면
Cnn.fit(train_input,train_output,epochs=10, batch_size=100)
이렇게 정확도가 약 0.98로 나온다. 그러나 이 값이 overfit일 수도 있기에 구분해둔 test 데이터로 한 번 검사해보자.
Cnn.evaluate(test_input,test_output)
다행히 overfit은 아니다. 그렇다면 실제 내가 쓴 손글자를 적용해보자.
3. 손글자 적용
이제는 실제로 내가 쓴 손글자를 적용시켜볼 것이다. 위에서 적어놓았지만 모델은 내가 쓴 손글자를 그대로 받아들이지 못한다. 그렇기에 모델이 알아볼 수 있게 png 파일을 적절히 변형시켜줄 필요가 있는데, 나는 cv2.imread()을 이용해 Gray Scale로 변형시켜줄 것이다.
import cv2
test = cv2.imread("/content/(숫자).png",cv2.IMREAD_GRAYSCALE)
plt.imshow(test)이렇게 해주면 변형된 파일을 볼 수 있다.
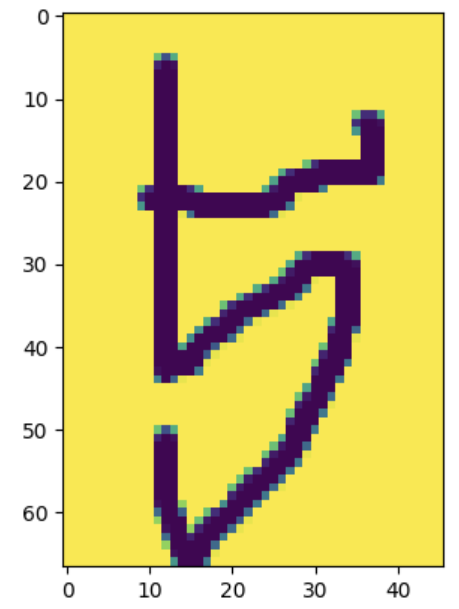
이때 데이터가 (40,40)인 것을 볼 수 있는데, 이 크기는 너무 크기 때문에 (28,28)로 바꿔 줄 것이다.
test_BW=255-test
plt.imshow(test_BW)
test_BW_size=cv2.resize(test_BW,(28,28))
# test_BW_size.shape
test_BW_size_re=test_BW_size.reshape(1,28,28)이렇게 변경해준 뒤, 내 손글씨를 알아보는지 확인해보자.
Cnn.predict(test_BW_size_re)
np.argmax(Cnn.predict(test_BW_size_re))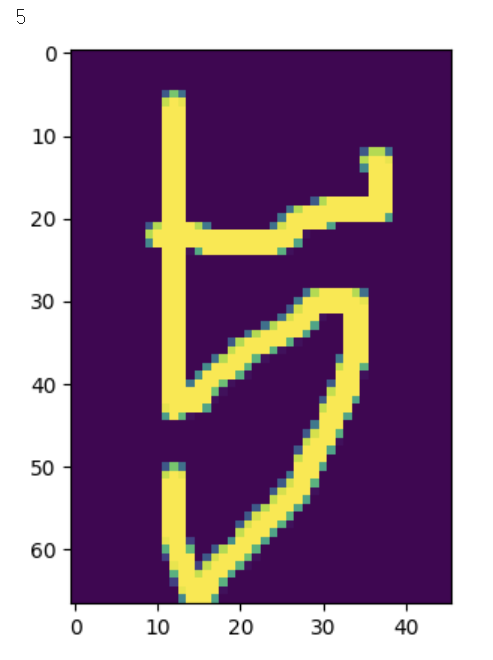
이렇게 위의 내가 적은 5와 위의 결과인 5가 같은 것을 볼 수 있다.
다른 데이터도 확인한 결과, 잘 맞추는 것을 볼 수 있다.
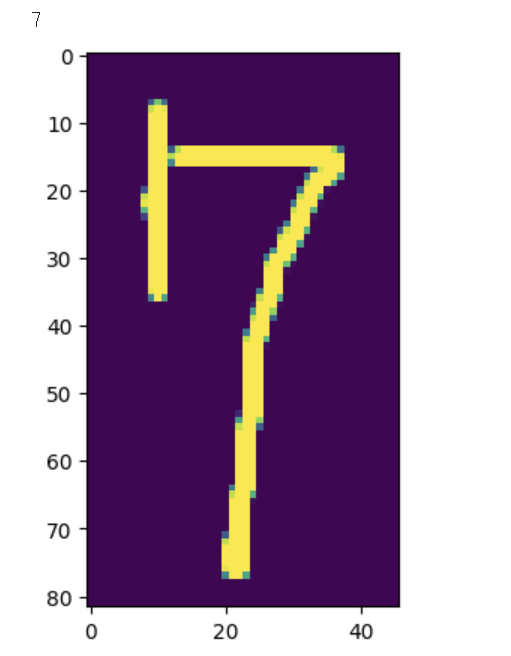
4. 후기
CNN을 사용하면서 크게 2가지의 문제에 부딪혔다.
첫번째로는 tensorflow의 버전에 따라 데이터를 불러오는 방법이 다르다는 것을 몰랐다. 처음에는 구글에 검색한 뒤 가장 보편적으로 나온 방법을 따라 불러오려고 시도했지만 계속해서 데이터가 로드되지 않았던 점이다. 그래서 공식 문서를 찾아 확인해보니, tensorflow가 2.0에서 불러오는 방법이 다르다는 것을 알게 되었고, 공식 문서의 예제를 따라 하니 해결되었다.
두번째는 모델에서 Dropout의 사용이었다. 처음에 모델을 생성하면서 Dropout을 생각하지 않고 제작했는데, 그로 인한 문제가 생겼다. 그래서 이 문제를 해결하기 위해 다른 방법들을 많이 사용했는데, 해결이 되지 않았다. 그래서 이 문제가 왜 생긴걸까 하며 처음부터 CNN에 대한 것을 둘러봤는데, 이때 Dropout에 대한 이야기가 있었다. 그 다음으로는 Dropout을 검색해보고 적용시켜보니 문제가 해결되었다.
이 두 문제를 해결하면서 CNN에 대해 다시 공부하고, tensorflow에 대해서도 알게 되었고, 결국 문제를 해결했다.
전체 코드
(Colab에서 진행되었고, tensorflow의 버전은 2.0이다.
imread에서의 사진 경로에 대해서는 Colab의 기본이 Content이기에 거기다가 올리면 된다.)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
(data_train, label_train), (data_test, label_test) = tf.keras.datasets.mnist.load_data()
data=np.concatenate((data_train,data_test),axis=0)
label=np.concatenate((label_train,label_test),axis=0)
from sklearn.model_selection import train_test_split
train_input,test_input,train_output,test_output=train_test_split(data,label,test_size=0.2)
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Conv2D #kernel
from keras.layers import Flatten
from keras.layers import MaxPooling2D #pooling
Cnn=Sequential()
Cnn.add(Conv2D(3, input_shape=(28,28,1), kernel_size=(3,3),padding="same", activation="relu"))
Cnn.add(MaxPooling2D(2))
Cnn.add(Flatten())
Cnn.add(Dense(200,activation="relu"))
Cnn.add(Dropout(0.2))
Cnn.add(Dense(100,activation="relu"))
Cnn.add(Dense(10,activation="softmax")) #0~9
Cnn.compile(loss="sparse_categorical_crossentropy",metrics="accuracy",optimizer="adam")
Cnn.fit(train_input,train_output,epochs=10, batch_size=100)
Cnn.evaluate(test_input,test_output)
import cv2
test = cv2.imread("/content/(숫자).png",cv2.IMREAD_GRAYSCALE)
plt.imshow(test)
test_BW = 255-test
plt.imshow(test_BW)
test_BW_size = cv2.resize(test_BW,(28,28))
# test_BW_size.shape
test_BW_size_re = test_BW_size.reshape(1,28,28)
#test_BW_size_re.shape
Cnn.predict(test_BW_size_re)
np.argmax(Cnn.predict(test_BW_size_re))