코사인 유사도
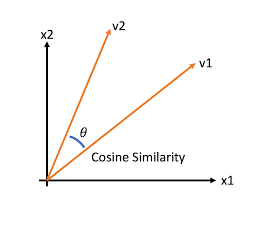
- 두 벡터의 내적을 계산한 결과가 0이면 두 벡터는 직교
- 0에서 1에 가까워 질수록 두 벡터의 방향이 비슷해지며 1이 되면 완전히 같은 방향이 됨
- -1일 때는 벡터가 완전히 반대 방향을 향함
- 즉, 이 방법을 활용하여 두 벡터가 닮았는지를 판단하는 것
코사인 유사도를 구하는 식은 다음과 같다.
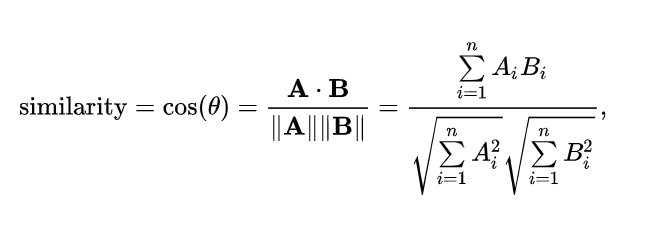
유사도 구하기
먼저 단순한 문장부터 해 보자.
import numpy as np
# 형태소 종류 5개 중 각각의 문장이 가진 형태소 종류 카운트
def v(V, D):
for value in ['파란','하얀','하늘','구름','파도']:
if value in D:
V.append(D[value])
else:
V.append(0)
return V
# 코사인 유사도 구하기
def sim(a,b):
return a@b/(np.linalg.norm(a) * np.linalg.norm(b))
# 문장에서 형태소를 분리한다
A = '파란 하늘 파란 파도'
B = '파란 하늘 하얀 파도'
C = '하얀 구름 파란 하늘'
LA = A.split()
LB = B.split()
LC = C.split()
DA = {word:LA.count(word) for word in LA}
DB = {word:LB.count(word) for word in LB}
DC = {word:LC.count(word) for word in LC}
VA=[]
VB=[]
VC=[]
va=np.array(v(VA,DA))
vb=np.array(v(VB,DB))
vc=np.array(v(VC,DC))
print(sim(va,vb)) # 0.8164965809277261
print(sim(va,vc)) # 0.6123724356957946
print(sim(vb,vc)) # 0.75결과를 확인해보면 문장 A와 문장 B가 유사하다는걸 알 수 있다.
이번엔 실제 문장에서 형태소를 분리한 뒤 유사도를 구해보자.
from konlpy.tag import *
import numpy as np
# 형태소 종류 중 각각의 문장이 가진 형태소 종류 카운트
def make_vec(feature,data):
v = []
for f in feature:
cnt =0
for word in data:
if word == f:
cnt += 1
v.append(cnt)
return np.array(v)
# 코사인 유사도 구하기
def sim(a,b):
return a@b/(np.linalg.norm(a) * np.linalg.norm(b))
okt = Okt()
# input에서 형태소 분리
A = okt.nouns(input()) # 내 이름은 코난, 탐정이죠
B = okt.nouns(input()) # 내 이름은 유난, 떨고있죠
C = okt.nouns(input()) # 으하하하
print(A) # ['내', '이름', '코난', '탐정']
print(B) # ['내', '이름', '유난']
print(C) # ['하하']
feature = set(A+B+C)
va = make_vec(feature,A)
vb = make_vec(feature,B)
vc = make_vec(feature,C)
print('va & vb', sim(va,vb)) # va & vb 0.5773502691896258
print('vb & vc', sim(vb,vc)) # vb & vc 0.0
print('va & vc', sim(va,vc)) # va & vc 0.0문장 A와 B는 유사하지만, B와 C, C와 A는 유사하지 않음을 결과로 알 수 있다.

꼴리는대로 사는게 꿈입니다