먼저 QuerySet에 대해 정의해보자.
-
Django ORM에서 제공하는 데이터 타입으로, DB에서 전달받은 객체 목록이다.
-- 구조는 list와 같지만, 파이썬의 기본 자료 구조가 아니기 떄문에 파이썬 파일에서 읽고 쓰기 위해서는 자료형 변환을 해줘야 한다.
- select
- [클래스 명].objects.all() : 해당 테이블 안에 있는 모든 데이터 조회한다. (단, QuerySet 타입으로 반환.)
In : Drink.objects.all() Out: <QuerySet [<Drink: 나이트로 바닐라 크림>, <Drink: 나이트로 쇼콜라 클라우드>, <Drink: 망고 패션 후르츠 블렌디드>, <Drink: 딸기 요거트 블렌디드>, <Drink: 블랙 티 레모네이드>, <Drink: 쿨라임 피지오>, <Drink: 말차 초콜릿 라떼>, <Drink: 라임패션티>]> ```
-
[클래스 명].objects.get()
: 하나의 row(세로축)만 조회. 주로 PK(primerKey)컬럼(가로축)으로 조회한다.
중요! 결과가 1건 이상 일 때는 에러가 발생한다
QuerySet 타입이 아닌 객체 타입으로 반환한다.
In : Drink.objects.get(id=1)
Out: <Drink: 나이트로 바닐라 크림>
# pk컬럼명 대신 그냥 pk 키워드로도 조회 가능
In : Drink.objects.get(pk=1)
Out: <Drink: 나이트로 바닐라 크림>
# 조회 결과가 1건 이상일 땐 에러 반환
In : Drink.objects.get(category_id=1)
Traceback (most recent call last):
File "<console>", line 1, in <module>
File "/Users/yangah/miniconda3/envs/exercise/lib/python3.9/site-packages/django/db/models/manager.py", line 85, in manager_method
return getattr(self.get_queryset(), name)(*args, **kwargs)
File "/Users/yangah/miniconda3/envs/exercise/lib/python3.9/site-packages/django/db/models/query.py", line 433, in get
raise self.model.MultipleObjectsReturned(
products.models.Drink.MultipleObjectsReturned: get() returned more than one Drink -- it returned 2!-
[클래스 명].objects.filter()
: 특정 조건에 맞는 row만 조회하고 싶을 때 사용한다. QuerySet타입으로 반환
앞서 설명한 GET은 1개의 결과값만 된다면 이것은 여러개여도 상관없다.
# category_id = 1인 데이터를 제외한 모든 데이터 조회
In : Drink.objects.exclude(category_id=1)
Out: <QuerySet [<Drink: 망고 패션 후르츠 블렌디드>, <Drink: 딸기 요거트 블렌디드>, <Drink: 블랙 티 레모네이드>, <Drink: 쿨라임 피지오>, <Drink: 말차 초콜릿 라떼>, <Drink: 라임패션티>]>- [클래스 명].objects.exclude()
: 특정 조건을 제외한 데이터만 조회하고 싶을 때 사용한다.
QuerySet 타입으로 반환.
# category_id = 1인 데이터를 제외한 모든 데이터 조회
In : Drink.objects.exclude(category_id=1)
Out: <QuerySet [<Drink: 망고 패션 후르츠 블렌디드>, <Drink: 딸기 요거트 블렌디드>, <Drink: 블랙 티 레모네이드>, <Drink: 쿨라임 피지오>, <Drink: 말차 초콜릿 라떼>, <Drink: 라임패션티>]>- Lookup filter
filter(), exclude() 메소드에서 사용 가능한 내장 모듈로, 필드 별 구체적인 값에 대한 비교를 가능하게 하는 Django의 내장 모듈이다.
__contains : 특정문자가 포함된 것을 찾을 때 사용(대소문자 구분)
# english_name 컬럼에 'Blend'이라는 단어가 들어간 데이터 조회 (단, 대소문자 구분)
In : Drink.objects.filter(english_name__contains="blend")
Out: <QuerySet []>
In : Drink.objects.filter(english_name__contains="Blend")
Out: <QuerySet [<Drink: 망고 패션 후르츠 블렌디드>, <Drink: 딸기 요거트 블렌디드>]>__icontains : 특정 문자가 포함된 것을 찾을 때 사용 (대소문자를 구분하지 않음)
# english_name 컬럼에 'blend'이라는 단어가 들어간 데이터 조회 (대소문자를 구분하지 않음)
In : Drink.objects.filter(english_name__icontains="blend")
Out: <QuerySet [<Drink: 망고 패션 후르츠 블렌디드>, <Drink: 딸기 요거트 블렌디드>]>
In : Drink.objects.filter(english_name__icontains="Blend")
Out: <QuerySet [<Drink: 망고 패션 후르츠 블렌디드>, <Drink: 딸기 요거트 블렌디드>]>
__startswith : 특정 문자로 시작하는 것을 찾을 때 사용
# english_name 컬럼에 'Nitro'로 시작하는 문자열을 가진 데이터 조회 (단, 대소문자 구분)
In : Drink.objects.filter(english_name__startswith="Nitro")
Out: <QuerySet [<Drink: 나이트로 바닐라 크림>, <Drink: 나이트로 쇼콜라 클라우드>]>
In : Drink.objects.filter(english_name__startswith="nitro")
Out: <QuerySet []>__endswith : 특정 문자로 끝나는 것을 찾을 때 사용
# english_name 컬럼에서 'Tea'로 끝나는 문자를 가진 데이터 조회 (대소문자 구분)
In : Drink.objects.filter(english_name__endswith="Tea")
Out: <QuerySet [<Drink: 라임패션티>]>
In : Drink.objects.filter(english_name__endswith="tea")
Out: <QuerySet []>
__gt : 특정 값 보다 큰 데이터만 조회 (greater than의 약자)
# id가 3보다 큰 데이터만 조회(3포함 X)
In : Drink.objects.filter(id__gt=3)
Out: <QuerySet [<Drink: 딸기 요거트 블렌디드>, <Drink: 블랙 티 레모네이드>, <Drink: 쿨라임 피지오>, <Drink: 말차 초콜릿 라떼>, <Drink: 라임패션티>]>__lt : 특정 값 보다 작은 데이터만 조회 (less than의 약자)
# id가 3보다 작은 데이터만 조회
In : Drink.objects.filter(id__lt=3)
Out: <QuerySet [<Drink: 나이트로 바닐라 크림>, <Drink: 나이트로 쇼콜라 클라우드>]>__isnull : True로 지정 시 특정 필드 값이 null인 것만 조회
# description 컬럼이 null인 것만 조회
In : Drink.objects.filter(description__isnull=True)
Out: <QuerySet [<Drink: 나이트로 바닐라 크림>, <Drink: 나이트로 콜드 브루>]>
# description 컬럼이 null이 아닌 것만 조회
In : Drink.objects.filter(description__isnull=False)
Out: <QuerySet [<Drink: 망바>, <Drink: 딸요>, <Drink: 말차라떼>, <Drink: 얼그레이>]>__in : 리스트 안에 지정한 문자열들 중에 하나라도 포함된 데이터를 찾을 때 사용 (단, 문자열과 정확히 일치해야함)
# english_name 필드에 'Malcha' 또는 'Nitro Cold Brew' 값이 있는 것만 조회
In : Drink.objects.filter(english_name__in=['Malcha', 'Nitro Cold Brew'])
Out: <QuerySet [<Drink: 나이트로 쇼콜라 클라우드>, <Drink: 말차 초콜릿 라떼>]>
# english_name 필드에 'Malcha' 또는 'Nitro' 값이 있는 것만 조회
In : Drink.objects.filter(english_name__in=['Malcha', 'Nitro'])
Out: <QuerySet [<Drink: 말차 초콜릿 라떼>]>year, month, day, date : date 타입의 필드에서 특정 년(year), 월(month), 일(day) 혹은 특정 날짜(date : YY-MM-DD 형식)의 데이터를 찾을 때 사용
# pub_date 필드에서 년도가 2021 인 것만 조회
In : Question.objects.filter(pub_date__year='2021')
Out: <QuerySet [<Question: What's new?>, <Question: new>]>AND / OR
filter() 메소드 사용 시, 두개 이상의 조건을 AND 또는 OR을 이용하여 표현할 수 있다.
- AND 조건 : 두 개 이상의 쿼리 셋을 '&' 로 연결
- OR 조건 : 두 개 이상의 퀴리 셋을 '|'로 연결
# AND 조건 예시
In : Drink.objects.filter(id__gt=6) & Drink.objects.filter(korean_name__contains = "라임")
Out: <QuerySet [<Drink: 라임패션티>]>
# OR 조건 예시
In : Drink.objects.filter(id__gt=6) | Drink.objects.filter(korean_name__contains = "라임")
Out: <QuerySet [<Drink: 쿨라임 피지오>, <Drink: 말차 초콜릿 라떼>, <Drink: 라임패션티>]>[클래스 명].objects.count()
: 쿼리 셋에 포함된 데이터 개수를 리턴한다.
# Drink 테이블에 몇 개의 데이터가 들어있는지 조회
In : Drink.objects.count()
Out: 8[클래스 명].objects.exists()
: 해당 테이블에 데이터가 있는지 확인. 있으면 True, 없으면 False 반환.
# Menu에 name이 '음료'인 데이터가 있으면 True, 없으면 False
In : Menu.objects.filter(name="음료").exists()
Out: True
[클래스 명].objects.values()
: QuerySet의 내용을 딕셔너리 형태로 반환한다. 인자값에 아무 것도 넣지 않으면 해당 클래스의 모든 필드와 그 값을 보여주고, 인자값에 특정 필드를 입력하면 입력한 필드에 대한 값을 반환한다.
# Menu 테이블의 모든 필드를 딕셔너리 형태로 반환
In : Menu.objects.values()
Out: <QuerySet [{'id': 1, 'name': '음료'}, {'id': 2, 'name': '푸드'}, {'id': 3, 'name': '상품'}, {'id': 4, 'name': '카드'}]>
# Menu 테이블의 name 필드만 딕셔너리 형태로 반환
In : Menu.objects.values('name')
Out: <QuerySet [{'name': '음료'}, {'name': '푸드'}, {'name': '상품'}, {'name': '카드'}]>
[클래스 명].objects.values_list()
: values()와 같으나 QuerySet의 내용을 딕셔너리가 아닌 리스트 타입으로 반환
In : Menu.objects.values_list()
Out: <QuerySet [(1, '음료'), (2, '푸드'), (3, '상품'), (4, '카드')]>
In : Menu.objects.values_list('name')
Out: <QuerySet [('음료',), ('푸드',), ('상품',), ('카드',)]>[클래스 명].objects.order_by()
: 특점 필드를 기준으로 정렬을 할 때 사용. 필드명 앞에 -가 붙으면 내림차순을 의미한다.
# korean_name 필드를 기준으로 오름차순 정렬
In : Drink.objects.order_by('korean_name')
Out: <QuerySet [<Drink: 나이트로 바닐라 크림>, <Drink: 나이트로 쇼콜라 클라우드>, <Drink: 딸기 요거트 블렌디드>, <Drink: 라임패션티>, <Drink: 말차 초콜릿 라떼>, <Drink: 망고 패션 후르츠 블렌디드>, <Drink: 블랙 티 레모네이드>, <Drink: 쿨라임 피지오>]>
# korean_name 필드를 기준으로 내림차순 정렬, 두번째 기준은 id 필드
In : Drink.objects.order_by('-korean_name', 'id')
Out: <QuerySet [<Drink: 쿨라임 피지오>, <Drink: 블랙 티 레모네이드>, <Drink: 망고 패션 후르츠 블렌디드>, <Drink: 말차 초콜릿 라떼>, <Drink: 라임패션티>, <Drink: 딸기 요거트 블렌디드>, <Drink: 나이트로 쇼콜라 클라우드>, <Drink: 나이트로 바닐라 크림>]>[클래스 명].objects.first()
: 쿼리 셋 결과 중 가장 첫번째 row만 조회할 때 사용
# 전체 조회
In : Drink.objects.all()
Out: <QuerySet [<Drink: 나이트로 바닐라 크림>, <Drink: 나이트로 쇼콜라 클라우드>, <Drink: 망고 패션 후르츠 블렌디드>, <Drink: 딸기 요거트 블렌디드>, <Drink: 블랙 티 레모네이드>, <Drink: 쿨라임 피지오>, <Drink: 말차 초콜릿 라떼>, <Drink: 라임패션티>]>
# 가장 첫번째 row만 조회
In : Drink.objects.first()
Out: <Drink: 나이트로 바닐라 크림>[클래스 명].objects.last()
: 쿼리 셋 결과 중 가장 마지막 row만 조회할 때 사용. 둘 다 객체 타입 반환.
# 가장 마지막 row만 조회
In : Drink.objects.last()
Out: <Drink: 라임패션티>[클래스 명].objects.aggregate()
: django의 집계함수 모듈(Avg, Max, Min, Count, Sum 등)을 사용할 때 사용하는 메소드. 집계함수들을 파라미터로 받는다.
딕셔너리 타입으로 반환한다.
# 집계함수를 사용하려면 import 해줘야 함
In : from django.db.models import Max, Min, Avg, Sum
# Nutrition 테이블의 id 컬럼과 one_serving_kcal 컬럼만 조회
In : Nutrition.objects.values('id','one_serving_kcal')
Out: <QuerySet [{'id': 1, 'one_serving_kcal': Decimal('75.00')}, {'id': 2, 'one_serving_kcal': Decimal('120.00')}]>
# one_serving_kcal 값 모두 더하기
In : Nutrition.objects.aggregate(Sum('one_serving_kcal'))
Out: {'one_serving_kcal__sum': Decimal('195.00')}
# one_serving_kcal컬럼에서 가장 큰 값과 가장 작은 값의 차이
In : Nutrition.objects.aggregate(diff_kcal = Max('one_serving_kcal') - Min('one_serving_kcal'))
Out: {'diff_kcal': Decimal('45.00')}
# one_serving_kcal 컬럼 값들의 평균
In : Nutrition.objects.aggregate(avg_kcal = Avg('one_serving_kcal'))
Out: {'avg_kcal': Decimal('97.500000')}[클래스 명].objects.annotate()
: annotate은 주석이라는 뜻인데, annotate()는 각 컬럼별 주석을 달고 집계함수를 사용하여 반환한다.
SQL의 group by 절과 같은 의미라고 생각하면 된다.
결과는 QuerySet 형태로 반환한다.
In : Nutrition.objects.values('drink_id__category_id').annotate(Sum('one_serving_kcal'))
Out: <QuerySet [{'drink_id__category_id': 1, 'one_serving_kcal__sum': Decimal('80.00')}, {'drink_id__category_id': 2, 'one_serving_kcal__sum': Decimal('410.00')}, {'drink_id__category_id': 3, 'one_serving_kcal__sum': Decimal('170.00')}, {'drink_id__category_id': 4, 'one_serving_kcal__sum': Decimal('425.00')}]>위 쿼리 셋을 SQL로 표현하면 아래와 같다.
select d.category_id, sum(n.one_serving_kcal)
from nutritions n, drinks d
where n.drink_id = d.id
group by d.category_id
;결과 >> 쿼리셋의 결과와 같음을 확인할 수 있다. 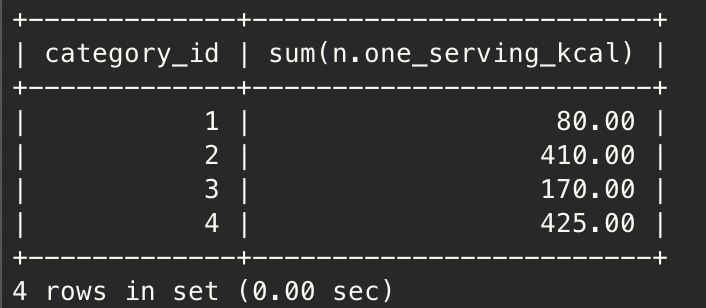
- chaining Methods
: 여러 메소드를 .으로 연결해서 사용할 수도 있다.
# filter 와 count 메소드를 함께 사용
In : Drink.objects.filter(category_id=2).count()
Out: 2- slicing
: 쿼리 셋 결과를 인덱스 slicing 하는 것 처럼 slicing 할 수 있다.
In : Drink.objects.all()[:2]
Out: <QuerySet [<Drink: 나이트로 바닐라 크림>, <Drink: 나이트로 쇼콜라 클라우드>]>
In : Drink.objects.all()[3:5]
Out: <QuerySet [<Drink: 딸기 요거트 블렌디드>, <Drink: 블랙 티 레모네이드>]>
In : Drink.objects.all()[6:]
Out: <QuerySet [<Drink: 말차 초콜릿 라떼>, <Drink: 라임패션티>]>
- insert
[클래스 명].objects.create()
In : Nutrition.objects.create(one_serving_kcal=120, sodium_mg=70, saturated_fat_g=0, sugers_g=25, protei
...: n_g=1, caffeine_mg=35, drink_id=3, size="Tall(톨)", size_fluid_ounce=355, size_ml=12)
Out: <Nutrition: 망고 패션 후르츠 블렌디드 nutritions>[클래스 명].objects.bulk_create()
: 여러 개의 object를 한꺼번에 생성할 때 사용
[클래스 명].objects.get_or_create()
: 해당 테이블에 조건에 맞는 데이터가 이미 존재하면 get을 해오고, 없으면 create하는 메소드.
튜플 타입을 반환해주는데 (get 또는 create한 객체, True/False) 형식으로 반환해준다.
여기서 True/False는 이미 존재하는 데이터면(=get하는 경우) False, 없는 데이터면(=create하는 경우) True를 의미.
# 이미 존재하는 데이터를 get_or_create 했을 때
In : Drink.objects.filter(korean_name='나이트로 쇼콜라 클라우드')
Out: <QuerySet [<Drink: 나이트로 쇼콜라 클라우드>]>
In : new_drink = Drink.objects.get_or_create(korean_name='나이트로 쇼콜라 클라우드')
# 기존에 있는 데이터 반환
In : new_drink
Out: (<Drink: 나이트로 쇼콜라 클라우드>, False)
# 없는 데이터를 get_or_create 했을 때
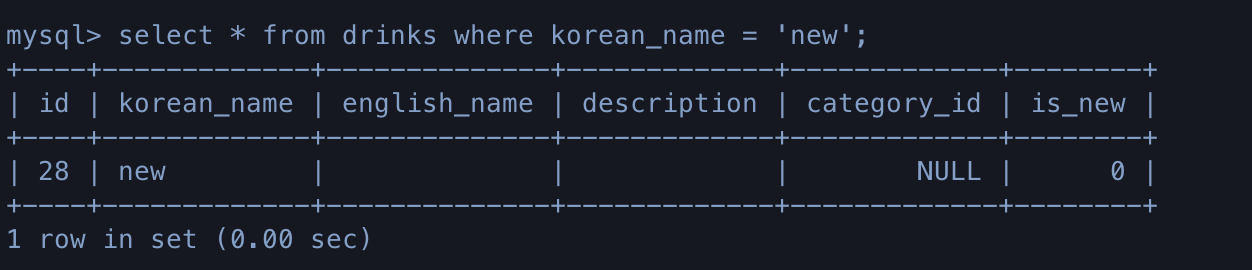
In : Drink.objects.filter(korean_name='new')
Out: <QuerySet []>
In : new_drink
Out: (<Drink: new>, True)
# 새로 추가된 것을 확인할 수 있다.
In : Drink.objects.filter(korean_name='new')
Out: <QuerySet [<Drink: new>]>단, 이렇게 create된 데이터는 나머지 컬럼에 '' 또는 null 또는 default 값이 자동으로 채워진다.
따라서 위 예시처럼 쓰는 것 보단 get_or_create()의 괄호 안에 그냥 create를 하는 것 처럼 써 주는게 좋다.
- update
방법 1)
업데이트 할 row를 변수에 저장을 하고 그 변수에서 각 필드에 접근하여 값을 변경해주는 방법.
반드시 .save()를 해줘야 변경사항이 저장됨.
a = Drink.objects.get(id=8)
In : a
Out: <Drink: 라임패션티>
# id가 8인 row의 description 컬럼 값을 'Lime Passion 2'로 업데이트
In : a.description = "Lime Passion 2"
# 변경사항 저장 >> 실제 DB에 적용됨
In : a.save()
# 결과 확인
In : Drink.objects.values('id','description').filter(id=8)
Out: <QuerySet [{'id': 8, 'description': 'Lime Passion 2'}]>방법 2)
filter().update()
# filter로 조건을 걸고(id=8) 그 row의 특정 컬럼(discription) 값을 update
In : Drink.objects.filter(id=8).update(description = "Lime Passion 3")
Out: 1
# 결과 확인
In : Drink.objects.values('id','description').filter(id=8)
Out: <QuerySet [{'id': 8, 'description': 'Lime Passion 3'}]>
- delete
: 삭제 할 row를 변수에 저장을 하고 그 변수에서 .delete() 메소드로 해당 데이터 삭제한다.
# 처음 데이터 확인
In : Menu.objects.all()
Out: <QuerySet [<Menu: 음료>, <Menu: 푸드>, <Menu: 상품>, <Menu: 카드>, <Menu: MD>]>
# 변수에 저장
In : a = Menu.objects.get(id=5)
# 삭제
In : a.delete()
Out: (1, {'products.Menu': 1})
# 결과 확인
In : Menu.objects.all()
Out: <QuerySet [<Menu: 음료>, <Menu: 푸드>, <Menu: 상품>, <Menu: 카드>]>출처:https://devvvyang.tistory.com/37?category=973523#recentComments
