-SELECT문
Column 1개
SELECT
first_name
FROM
customer;
1개의 열만 조회가 되었다.
가장 기본적인 형태라고 할 수 있다.
Column 여러 개
SELECT
first_name,
last_name,
email
FROM
customer;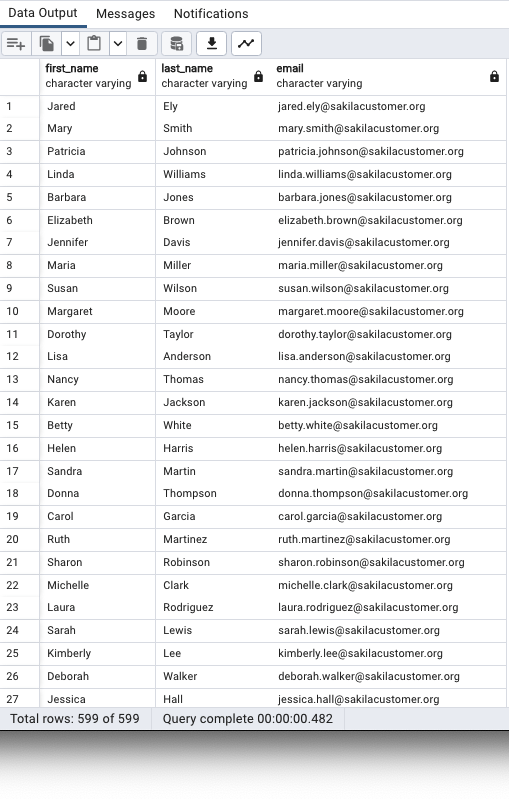
여러 개의 열을 선택해서 조회할 수 있다.
추가를 해도 되고, 제거를 해도 되고 자유롭다.
전체(*) 행 조회
SELECT
*
FROM
customer;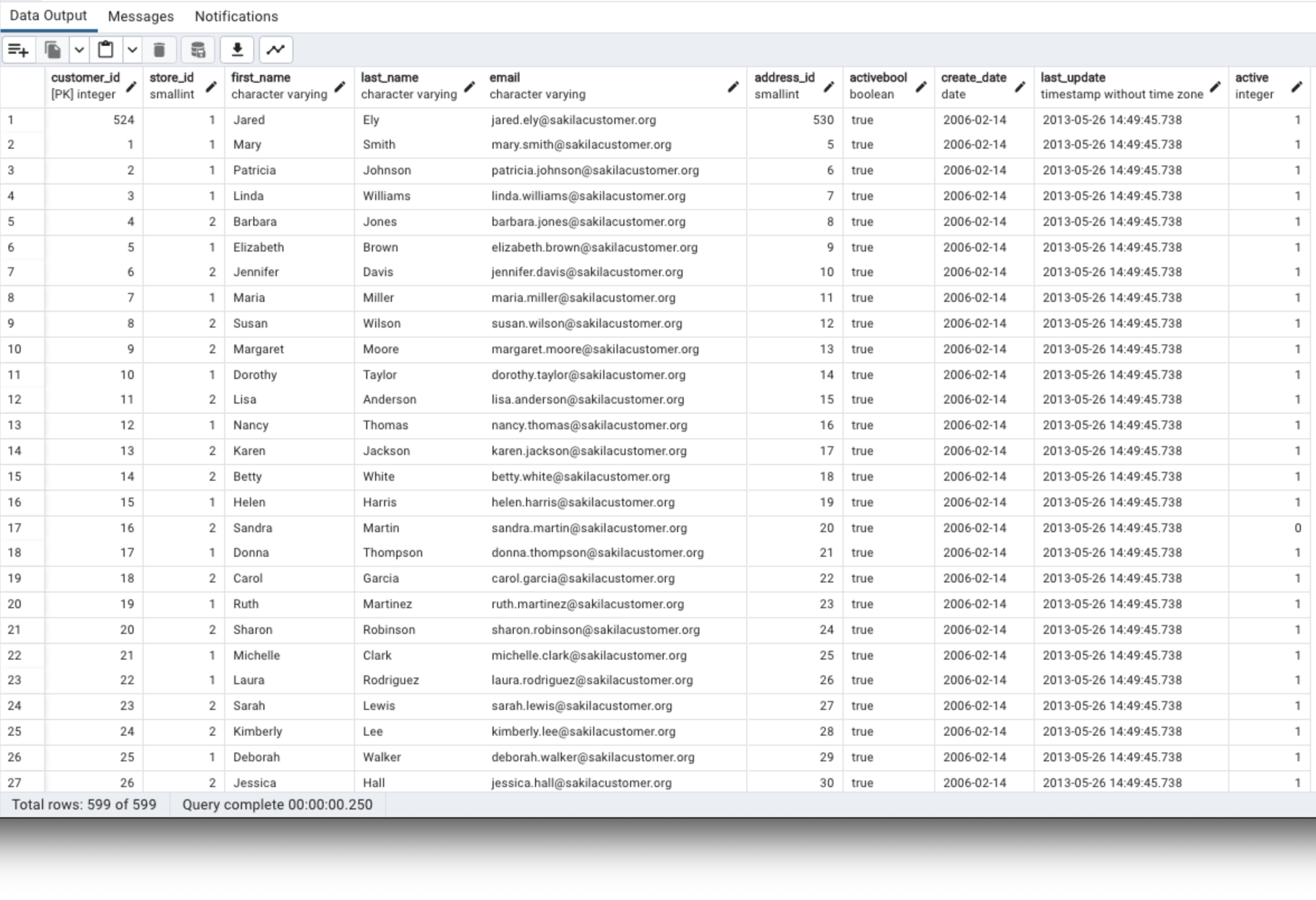
전체 행을 조회했다.
* 이 별표는 영어로 Asterisk라고 부르며,
애스터리스크 라고 부르면 된다.
2행 합치기
SELECT
first_name || ' ' || last_name,
email
FROM
customer;
두 개의 행을 합칠 수 있다.
내가 MySQL 혹은 Oracle을 이용할 때 이렇게 사용해본 적이 있는가
고민을 해봤는데 없었던 것같다.
first_name 과 last_name 사이에 작은 따옴표로 공백을 줘서
Jared Ely처럼 이름과 성을 확실하게 구분을 해주었다.
이게 필요할까 싶은 예제
SELECT
5 * 3;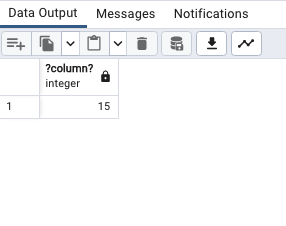
사용할 일 없다.
아마도?
-Column Alias
기본 형태
SELECT
column_name AS alias_name
FROM
table_name;AS는 별칭을 지정해주는 것인데,
아래의 쿼리처럼 생략 가능하다.
SELECT
column_name alias_name
FROM
table_name;별칭 지정(AS)
SELECT
first_name,
last_name AS surname
FROM customer;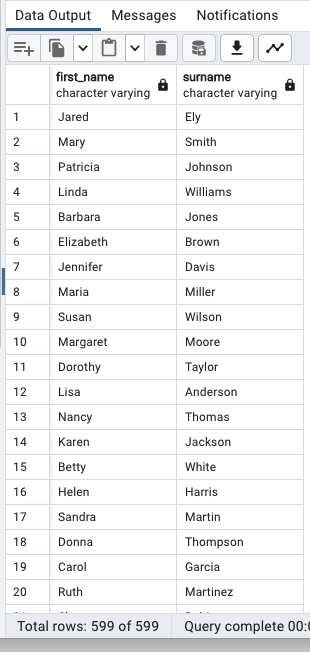
별칭 지정(AS 생략)
SELECT
first_name,
last_name surname
FROM
customer;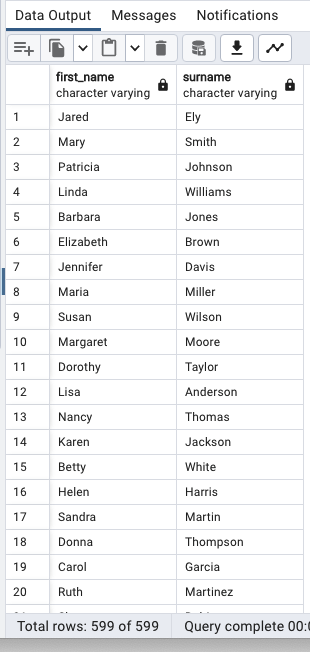
두 열 합치기(별칭 지정 전)
SELECT
first_name || ' ' || last_name
FROM
customer;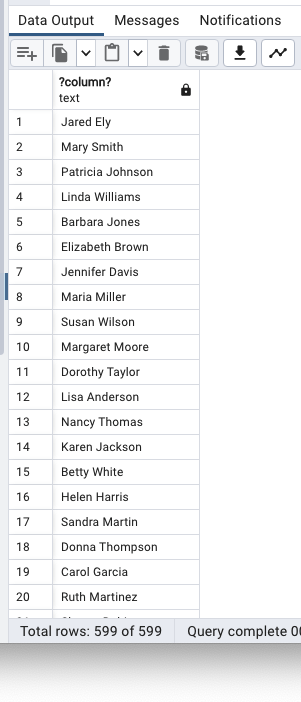
두 열 합치기(별칭 지정 AS)
SELECT
first_name || ' ' || last_name AS full_name
FROM
customer;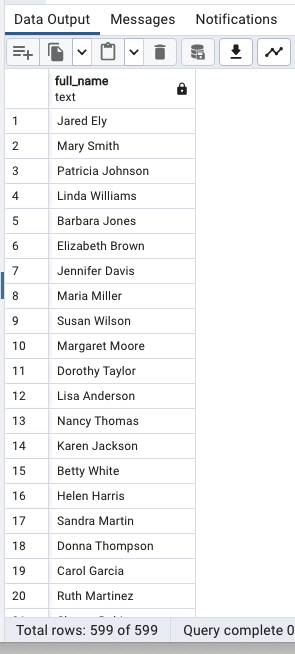
두 열 합치기(별칭 지정 + AS 생략)
SELECT
first_name || ' ' || last_name "full name"
FROM
customer;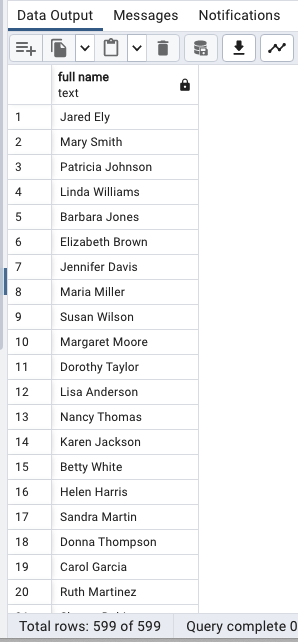
-ORDER BY
(예제를 위한)테이블 추가 및 INSERT
-- create a new table
CREATE TABLE sort_demo(
num INT
);
-- insert some data
INSERT INTO sort_demo(num)
VALUES(1),(2),(3),(null);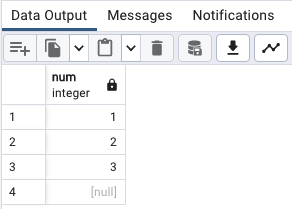
기본형태
SELECT
select_list
FROM
table_name
ORDER BY
sort_expression1 [ASC | DESC],
...
sort_expressionN [ASC | DESC];한 개의 열 기준 정렬(ASC 오름차순)
SELECT
first_name,
last_name
FROM
customer
ORDER BY
first_name ASC;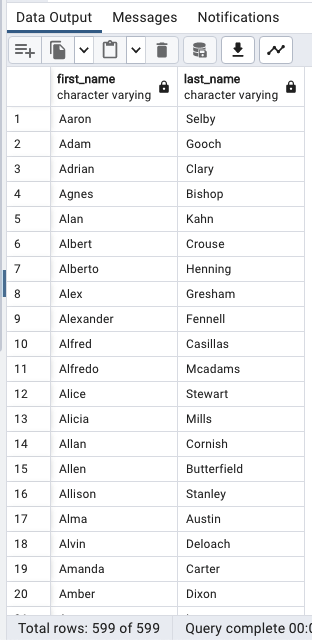
만약 ASC 혹은 DESC가 생략되어 있을 경우
Default값은 ASC(오름차순)
한 개의 열 기준 정렬(내림차순)
SELECT
first_name,
last_name
FROM
customer
ORDER BY
last_name DESC;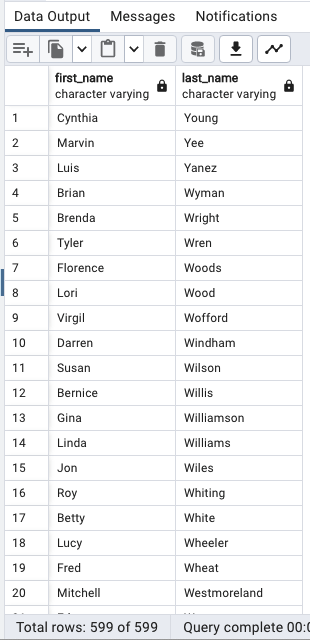
여러 개의 열 기준 정렬
SELECT
first_name,
last_name
FROM
customer
ORDER BY
first_name ASC,
last_name DESC;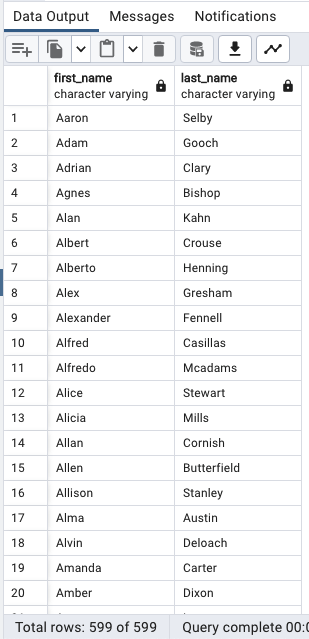
순서
1. first_name 열을 기준으로 오름차순
2. last_name 열을 기준으로 내림차순
글자 수를 기준으로 정렬
SELECT
first_name,
LENGTH(first_name) len
FROM
customer
ORDER BY
len DESC;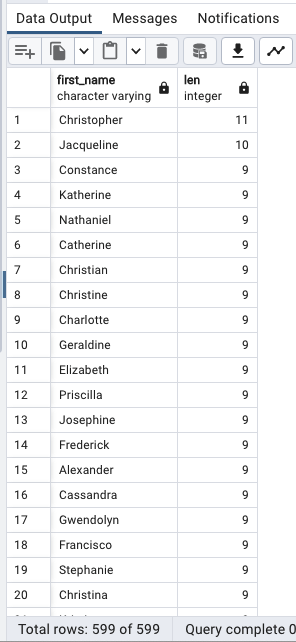
first_name의 글자수를 세어 len이라는 하나의 열을 생성 하고,
len 숫자를 기준으로 정렬을 했다.
*LENGTH 사용법
SELECT LENGTH({열 이름})
FROM {테이블}
NULL값이 처음에 오기
SELECT
num
FROM
sort_demo
ORDER BY
num NULLS FIRST;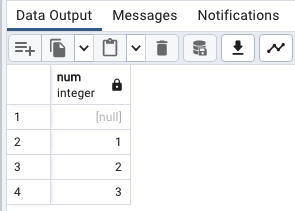
NULL값이 마지막에 오기
SELECT
num
FROM
sort_demo
ORDER BY
num NULLS LAST;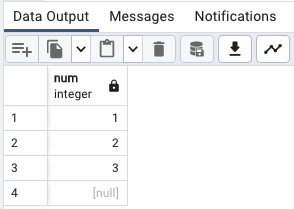
내림차순 + NULL값 마지막
SELECT
num
FROM
sort_demo
ORDER BY
num DESC NULLS LAST;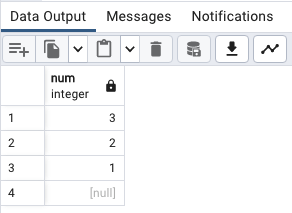
-SELECT DISTINCT
(예제를 위한)테이블 추가 및 INSERT
테이블 생성 및 INSERT
CREATE TABLE distinct_demo (
id serial NOT NULL PRIMARY KEY,
bcolor VARCHAR,
fcolor VARCHAR
);
INSERT INTO
distinct_demo (bcolor, fcolor)
VALUES
('red', 'red'),
('red', 'red'),
('red', NULL),
(NULL, 'red'),
('red', 'green'),
('red', 'blue'),
('green', 'red'),
('green', 'blue'),
('green', 'green'),
('blue', 'red'),
('blue', 'green'),
('blue', 'blue');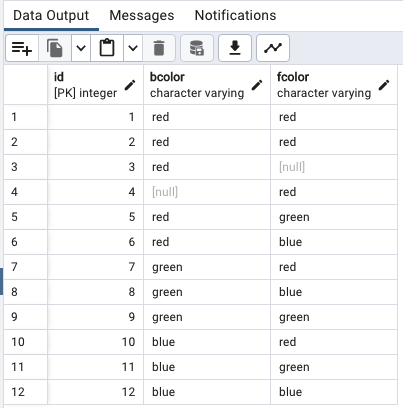
한개의 열 중복제거
SELECT
DISTINCT bcolor
FROM
distinct_demo
ORDER BY
bcolor;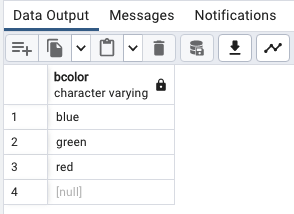
여러 개의 열 중복제거
SELECT
DISTINCT bcolor,
fcolor
FROM
distinct_demo
ORDER BY
bcolor,
fcolor;
원래
('red', 'red'),
('red', 'red')
이렇게 똑같았던 행이 중복이 사라져서
('red', 'red')
하나의 행만 표시된다.
DISTINCT ON
SELECT
DISTINCT ON (bcolor) bcolor,
fcolor
FROM
distinct_demo
ORDER BY
bcolor,
fcolor;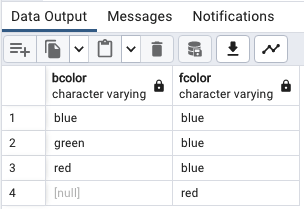
이것은 원래 내가 생각하는대로 하면
이해가 안되었다.
원래의 순서라면
FROM -> SELECT -> ORDER BY
이런식인데,
distinct on은 다르게 생각하는 것이 편하더라
FROM -> SELECT(열 선택만) -> ORDER BY -> DISTINCT ON(해당 열 중복 제거)
