자바스크립트 문자열은 다양한 나라의 언어를 표현할 수 있습니다. 자바스크립트는 수 많은 국가의 언어들을 어떻게 구분하고 저장할 수 있을까요?
이 의문을 해결하려면 자바스크립트가 내부적으로 문자열을 어떻게 표현하는지, 문자열의 인코딩과 디코딩 과정에 대한 이해가 필요합니다.
자바스크립트는 고수준 언어로 대부분의 경우 인코딩 & 디코딩 과정을 내부적으로 처리해주고, 필요한 경우에도 간단한 메서드를 통해 처리가 가능하기 때문에 개발하며 신경 쓸 일이 많이 없는데요.
그래서 인코딩과 디코딩은 자주 사용하는 용어임에도 불구하고 막상 설명을 해보려 하면 쉽지 않은 주제인 것 같습니다. 이번 글에서는 인코딩 & 디코딩이 무엇인지 관련 개념들과 함께 살펴보겠습니다.
Bit & Byte
근원이 되는 bit와 byte부터 이야기하며 시작 해보겠습니다. 컴퓨터의 CPU(중앙 처리 장치), 메모리(Memory), 저장 장치(Storage) 등은 모두 bit를 사용하여 데이터를 처리합니다.
bit는 0과 1로 이루어져 있고, 8개의 bit 모여 1byte를 이루게 됩니다. 아래 그림과 같은 형태입니다.
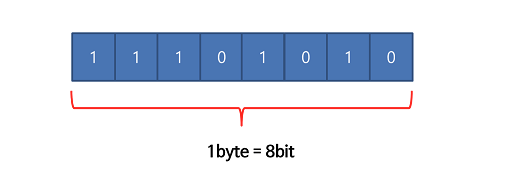
즉 메모리에 올라가는 모든 데이터는 0과 1로 변환되어 저장되게 됩니다.
아래와 같이 str이라는 변수에 문자열을 할당했다고 가정해봅시다.
const str = 'Hello world'
'Hello world'라는 문자열을 저장해야하는데, 저장 되기 위해선 모든 알파벳도 0과 1로 변환이 되어야 할텐데요.
이 때 각 알파벳은 어떤 숫자로 변환되어야 할까요? 알파벳 <-> 숫자를 상호간에 변환해주기 위해서는 '기준'이 필요합니다.
아스키코드
이를 위해 아스키코드가 등장하게 됩니다. 아스키 코드는 1960년대에 제정되어서 초기 컴퓨터 시스템에서 문자를 표현하기 위해 사용되었습니다.
아스키코드는 7비트로 표현되어 128개의 문자를 표현할 수 있고, 알파벳과 일부 문자들로 구성됩니다.
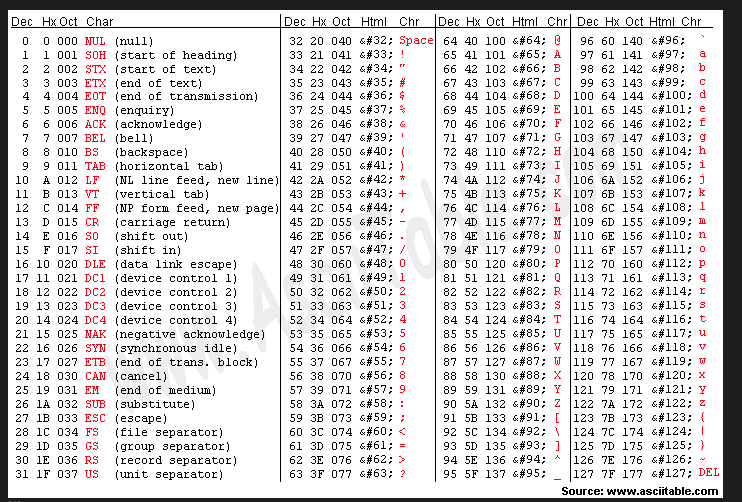
위 표를 보면 'H'는 72로 맵핑되어 있는것을 확인할 수 있습니다. 그러면 'H'는 이진수로 1001000로 변환되어 저장될 수 있겠네요. 'Hello world'에 있는 다른 문자들도 각각 값으로 변환되어 저장될 수 있습니다.
컴퓨터가 처음 나왔을때는 주로 영어권 국가에서만 사용되었기 때문에, 아스키 코드를 통해 영어 알파벳을 포함한 몇가지 문자들만 표현 가능해도 사용하는데 무리가 없었습니다.
그러나 시간이 흘러 다른 언어를 사용하는 국가들도 컴퓨터를 사용하게 되면서 다양한 언어들이 표현될 필요성이 생기게 되었습니다. 처음에는 국가 별로 아스키 코드에 남는 128개의 공간에 자국의 언어를 넣어서 사용하거나, 아스키코드표와 같은 국가의 표준을 직접 정의하여 사용하기도 했습니다.
이 방식은 인터넷이 나오기 전까지는 꽤 유효하게 동작했지만 인터넷의 발전으로 다른 언어를 사용하는 페이지도 방문할 필요성이 생김에 따라 결국 국제적인 표준이 필요하게 되었습니다.
유니코드
그래서 유니코드가 등장합니다. 유니코드란 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준을 말합니다. 쉽게 말하면 이 세상에 존재하는 모든 나라의 언어를 특정 숫자로 맵핑시켜놓은 표라고 생각할 수 있습니다.
유니코드는 0000부터 10FFFF까지의 범위를 가지며, 약 114만개의 문자를 표현할 수 있습니다. 현재 웹에서 사용되는 대부분의 언어를 표현하고도 빈 공간이 많이 남아있다고 합니다.
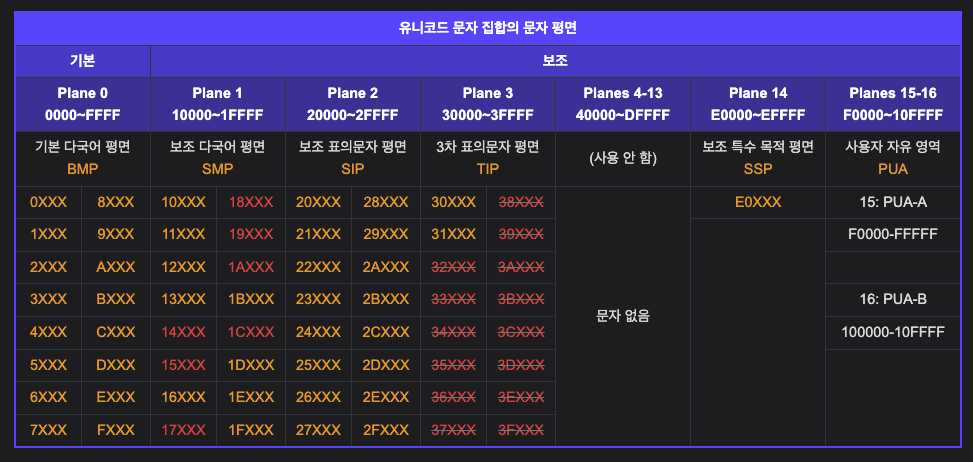
이렇듯 표현 가능한 문자들이 굉장히 많기 때문에 유니코드는 전체 공간을 17개로 나누어 용도별로 관리하고 있는데요. 각 공간을 '평면'이라고 부르고 있습니다.
한글을 포함한 기본 문자들은 대부분 0번 평면인 기본 다국어 평면(Basic Multilingual Plane)에 속해 있습니다. 한글은 0xAC00 ~ 0xD7A3 까지 차지하고 있습니다. 여기서 앞에 붙는 0x는 16진수임을 알려주는 prefix입니다.
아래는 유니코드 표를 보면 한글 '안'은 유니코드로 C548에 맵핑되어 있는것을 확인할 수 있습니다.

인코딩 & 디코딩
지금까지 아스키코드와 유니코드의 등장 배경에 대해서 알아보았습니다. 그리고 컴퓨터는 내부적으로 0과 1로 데이터를 표현하기 때문에 문자열 또한 컴퓨터가 이해 가능한 이진수로 바꾸어서 저장해야 한다는 사실도 알게 되었습니다.
이렇게 문자열을 컴퓨터가 이해가능한 이진수로 바꾸는 과정을 인코딩, 반대로 이진수를 문자열로 바꾸는 과정을 디코딩이라고 합니다.
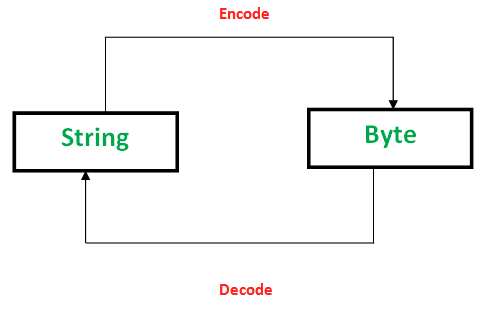
그러면 자바스크립트에서 모든 문자열들은 유니코드에 있는 값으로 변환되는걸까요? 아쉽게도 그렇지는 않습니다.
자바스크립트는 내부적으로 문자열을 유니코드를 이용한 인코딩 방식인 UTF-16 형식으로 인코딩하여 저장합니다.
MDN : Strings are represented fundamentally as sequences of UTF-16 code units. UTF-16 characters, Unicode code points, and grapheme clusters
Strings are represented fundamentally as sequences of UTF-16 code units. In UTF-16 encoding, every code unit is exact 16 bits long. This means there are a maximum of 216, or 65536 possible characters representable as single UTF-16 code units... (중략)
EcmaScript :
A String value is a member of the String type. Each integer value in the sequence usually represents a single 16-bit unit of UTF-16 text. However, ECMAScript does not place any restrictions or requirements on the values except that they must be 16-bit unsigned integers.
UTF-16은 또 무엇일까요? 유니코드는 엄밀히 말하면 인코딩 방식은 아닙니다. 유니코드를 기반으로 변환하는 UTF-8, UTF-16과 같은 인코딩 방식이 존재합니다.
즉 유니코드의 코드 포인트 그대로 메모리에 저장하지는 않는다는 소리인데요. 이 코드 포인트 값을 기반으로 한번 더 변환해서 저장하여 사용합니다.
왜 유니코드의 값을 그대로 사용하지 않고 다른 값으로 한번 더 변환하여 사용할까요? 가장 큰 이유는 효율성 때문입니다. 앞서 유니코드는 문자를 0000부터 10FFFF 사이의 코드포인트에 할당한다고 말씀드렸는데요.
10FFFF를 10진수로 변환하면 약 114만개이고, 이를 이진수로 표현하기 위해서는 대략 2^21 > 114만이므로 최소 21비트가 필요합니다.
따라서 유니코드 문자를 그대로 이용해서 처리하려면 24비트, 바이트로는 3바이트가 필요합니다. 하지만 컴퓨터의 구조상 홀수 바이트인 3바이트로 끊어 처리하는 것이 효율적이지 않기 때문에 빈 바이트를 0으로 채워 4바이트로 늘려서 처리하게 되는데요.
그럼 가장 사용 비중이 높은 영어의 입장에서는 기존의 ASCII를 사용했을때에 비해 저장 용량이 4배가 되어 굉장히 비효율적인 저장방식이 됩니다.
유니코드 초기에는 이러한 저장 방식(UCS-4)을 사용했지만, 문자열을 조금 효율적으로 표현하고 저장하기 위해 유니코드를 기반한 특정한 규칙으로 다시 변환하는 인코딩 방식인 UTF-8과, UTF-16이 등장했고 보다 더 보편적으로 사용되고 있습니다.
정리하면, 유니코드는 각 글자에 숫자를 배당하는 방식이고 인코딩은 유니코드 숫자를 표현하고 저장하는 방식이라고 볼 수 있겠습니다.
각 인코딩이 어떤 규칙을 통해 문자를 byte로 변환하는지는 잘 설명해놓은 포스팅이 많기도 하고, 포스팅의 길이가 너무 길어질 것 같아 다루지 않겠습니다. 궁금하신 분들은 이 글을 읽어보시길 추천드립니다.
TextEncoder
인코딩 방식에 대해 알아보고 난 뒤 '자바스크립트에서 인코딩과 디코딩을 직접 해볼 수 있을까?'라는 궁금증이 들어 조금 더 찾아보았는데요.
자바스크립트에서도 문자열 인코딩과 디코딩을 도와주는 네이티브 객체인 TextEncoder, TextDecoder 객체가 존재합니다.
TextEncoder는 문자열을 바이트로 변환합니다. TextEncoder를 이용하여 '안녕'이란 문자열을 utf-8 인코딩된 바이트로 변환해보겠습니다.
UTF-8 인코딩 방식에서 한글은 글자당 3바이트를 차지합니다. '안'은 '0xEC9588'로, '녕'은 '0xEB8595'로 표현됩니다.
실제로 TextEncoder를 통해 변환해보며 제대로 된 값을 뱉어주는지 확인해보겠습니다.
const encoder = new TextEncoder(); // TextEncoder 객체 생성
const uint8Array = encoder.encode("안녕"); // '안녕'이란 문자열을 utf-8 바이트로 변환
console.log(uint8Array); // [236, 149, 136, 235, 133, 149]얻은 uint8Array를 16진수로 변환해보면 0xEC, 0x95, 0x88, 0xEB, 0x85, 0x95이고, 3바이트씩 조합하면 '0xEC9588', '0xEB8595'네요. 제대로 변환해 주는것을 확인했습니다.
아쉽게도 TextEncoder는 생성자에 특정 인코딩 방식을 전달할 수 없고, 오로지 utf-8의 byteArray로의 변환만을 지원합니다.
TextDecoder
이제 반대로 TextDecoder를 사용해서 바이트 정보를 문자열로 변환해보겠습니다. TextDecoder는 TextEncoder와는 다르게 다양한 방식의 인코딩 데이터 input을 지원하는데요. 예전에 자주 쓰였던 방식 중 하나인 EUC-KR 인코딩 방식을 이용해 바이트 데이터를 문자열로 바꿔보겠습니다.
EUC-KR 인코딩 방식에서 '안'은 '0xBEC8', '녕'은 '0xB3E7'로 표현되는데요. 이를 byteArray로 표현하면 [190, 200, 179, 231]입니다.
const uint8Array = new Uint8Array([190, 200, 179, 231]);
const decoder = new TextDecoder('euc-kr');
const decodedString = decoder.decode(uint8Array);
console.log(decodedString); // 안녕역시 제대로 된 결과값을 뱉어주는것을 확인할 수 있습니다.
iconv-lite
iconv-lite는 인코딩 & 디코딩 관련 기능을 제공해주는 라이브러리입니다. 앞서 말씀드렸듯이 TextEncoder는 utf-8로의 인코딩만 지원하는데요. 다른 방식으로 문자열을 인코딩 해야할 때 iconv-lite를 유용하게 사용할 수 있습니다.
사용법은 간단합니다.
import iconv from 'iconv-lite';
const string = '안녕';
const encodedText = iconv.encode(string, 'euc-kr');
console.log(encodedText); // [190, 200, 179, 231]단점으로는 인코딩 변환 테이블을 라이브러리 내부에서 다 들고있기 때문에 번들 크기가 조금 커질 수 있습니다. (약 167.1k 정도네요 😅)
마치며
지금까지 자바스크립트의 인코딩과 디코딩에 과정에 대해 알아보았습니다.
사실 이 포스팅은 EUC-KR 형식으로 인코딩된 txt파일을 export하는 기능을 만들며 수많은 눈물을 흘린 후 작성되었는데요. 처음에는 브라우저에서의 변환이 불가능한줄 알았는데, 되긴 되더라구요. 사실 저도 엄청 많이 궁금하진 않았습니다.
혹시 틀린 내용이 있다면 댓글을 통해 말씀해주시면 감사하겠습니다🙇♂️
reference
https://d2.naver.com/helloworld/19187
https://brunch.co.kr/@font/179
https://velog.io/@goggling/%EC%9C%A0%EB%8B%88%EC%BD%94%EB%93%9C%EC%99%80-UTF-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0
