
React 18 버전의 릴리즈는 기존의 웹 개발 패러다임에 다시 한번 큰 전환점을 제시했습니다. Concurrent Feature, Batching update, React Server Component(이후 RSC), 그리고 Streaming SSR 등 새로운 기능들이 많이 도입되었습니다.
이 중에서도 RSC와 Streaming SSR은 기존의 서버 사이드 렌더링을 획기적으로 개선했는데요.
오늘은 이 두 가지 기능에 초점을 맞추어, 기존 SSR 모델의 한계점과 새로운 기능들이 이 문제를 어떻게 해결하는지 살펴보겠습니다.
기존의 SSR
우선 기존 서버 사이드 렌더링(이후 SSR)의 렌더링 방식에 대해 살펴봅시다.
유저가 페이지를 요청하면 서버는 초기 렌더링에 필요한 HTML 파일을 만들어 응답하는 간단한 요청-응답 모델을 가지고 있습니다.
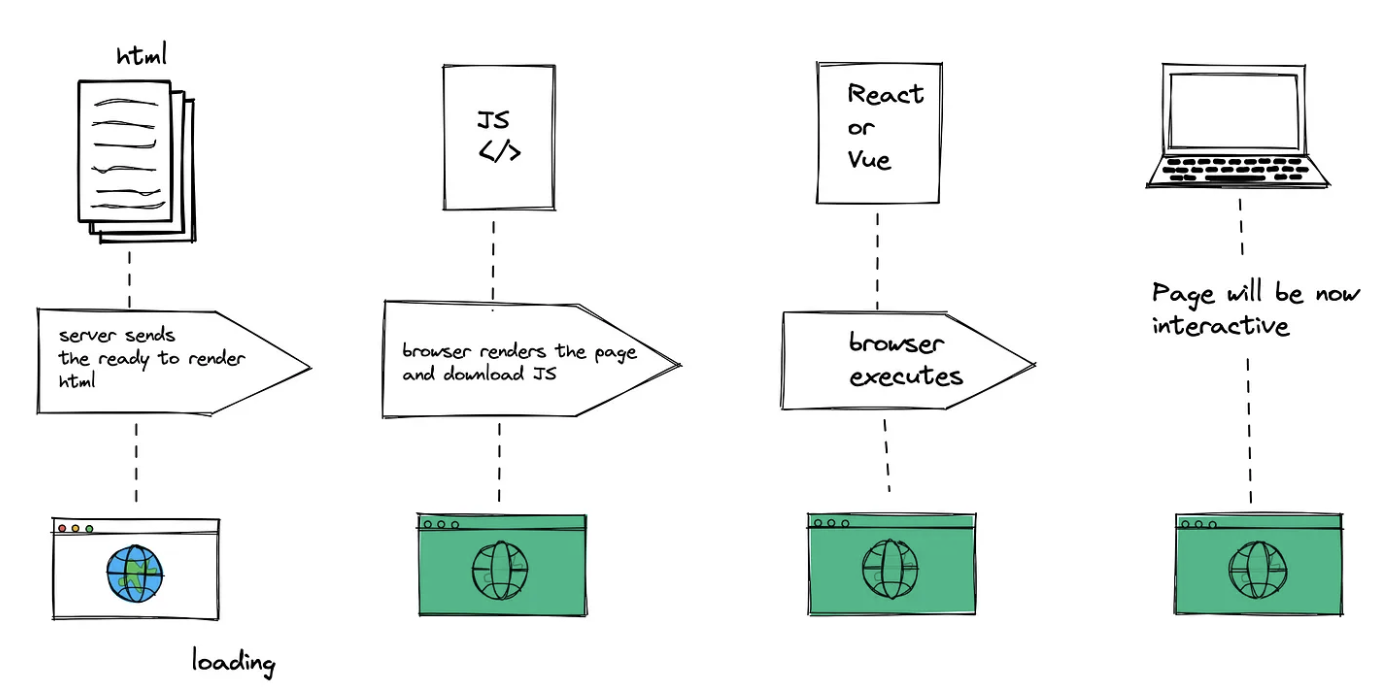
이미지 출처 : https://medium.com/geekculture/server-side-rendering-simplified-fd708d5520ba
이 과정을 좀 더 상세히 살펴보면 아래와 같습니다.
- 사용자가 페이지 진입 시 서버에 HTML 파일을 요청합니다.
- 서버에서는 데이터 패칭 등 필요한 작업들을 수행한 후 초기 HTML을 완성합니다.
- 완성된 HTML을 브라우저에 전송합니다.
- 브라우저는 받은 HTML을 렌더링합니다.
- 이후 리액트 컴포넌트를 실행하여 페이지를 상호작용 가능한 상태로 만듭니다.
기존 SSR 모델의 한계
이러한 SSR 모델은 어떤 문제점을 가지고 있었을까요?
첫번째로는 초기 로딩 시간이 길며, HTML이 반환되기 전에는 유저가 아무것도 볼 수 없다는 점입니다. 전체 페이지에 필요한 데이터를 한번에 내려받고, 완성된 HTML을 한번에 로드하기 때문입니다. 서버에서 HTML을 완성하는 데 걸리는 시간은 페이지의 복잡도에 비례해서 길어집니다.
두번째로는, 전체 렌더 트리에 대해 하이드레이션을 한번에 진행해야 한다는 점입니다. 초기 HTML을 받아서 화면을 그려낸다 하더라도, 모든 하이드레이션 과정이 종료되기 전에는 유저는 페이지를 정상적으로 사용할 수 없습니다.
리액트 코어 개발자인 Dan이 작성한 New Suspense SSR Architecture in React 18에도 이러한 SSR 모델의 문제점을 잘 설명하고 있습니다.
해당 글에서 Dan은 기존 SSR의 문제점을 아래 세가지로 요약합니다.
- 모든 것을 가져와야 무언가를 보여줄 수 있다. (You have to fetch everything before you can show anything)
- 모든 것을 로드해야 무언가를 하이드레이션할 수 있다. (You have to load everything before you can hydrate anything)
- 모든 것을 하이드레이션해야 무언가와 상호작용할 수 있다. (You have to hydrate everything before you can interact with anything)
세가지 문제점을 살펴보면 공통점이 있습니다. 바로 이전 단계가 모두 완료되기 전까지 다음 단계는 진행할 수 없다는 점인데요.
유저가 웹사이트를 정상적으로 이용하기 위해 데이터 패칭(서버) → HTML 생성(서버) → HTML 로드(클라이언트) → 하이드레이션(클라이언트)의 단계를 거쳐야 하는데, 각 단계는 이전 단계가 완료 된 후에 순차적으로 진행되어야 합니다.
즉, 기존의 SSR 모델은 waterfall을 가지고 있습니다. 리액트 팀은 기존 모델의 waterfall을 개선하고자 Streaming SSR과 Selective Hydration을 해결책으로 내놓습니다.
Streaming & Selective Hydration
기존의 SSR은 "All or Nothing" 방식이라고도 할 수 있습니다. 각 단계가 진행이 완료되거나, 안되거나 둘 중 하나이기 때문입니다. 유저 입장에서 중간 단계는 없습니다.
만약 각 과정이 나누어져서 진행될 수 있다면 어떨까요? 완성된 부분의 HTML을 먼저 수신하고, 도착한 부분부터 클라이언트에서 하이드레이션을 진행할 수 있다면요? 유저는 페이지를 더 빨리 보고, 더 빨리 사용할 수 있게 됩니다.
이게 Streaming SSR & Selective Hydration의 컨셉 입니다. 전 단계를 모두 완료한 후 다음 단계를 진행하는게 아니라, 각 단계를 쪼개서 진행하고 먼저 완료된 부분만 우선해서 보여주는 것이죠.
AS-IS와 TO-BE 모델을 그림으로 한번 살펴보며 비교해보겠습니다.
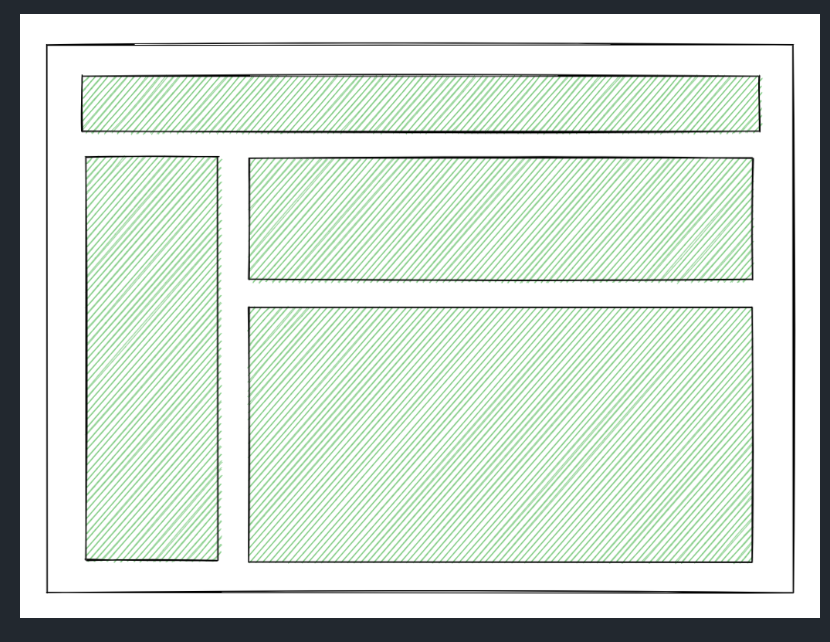
AS-IS
먼저, 기존 방식입니다. 아래와 같이 전체 HTML을 서버로부터 수신합니다. 이 단계가 완료되면 유저는 초기 화면을 볼 수 있습니다.

이후 전체 컴포넌트에 대해 하이드레이션을 진행합니다. 이 단계까지 완료되면 유저는 웹 사이트를 정상적으로 사용 가능합니다.
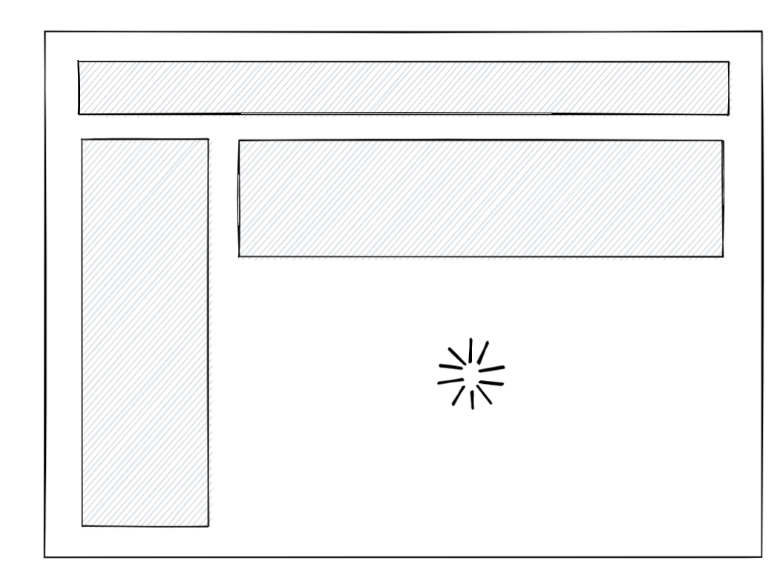
TO-BE
변경된 방식입니다. 서버는 완료된 HTML의 일부를 먼저 클라이언트로 내려줍니다. 유저는 전체 HTML 생성이 완료되지 않아도 화면을 볼 수 있습니다.
하이드레이션 역시 받은 부분부터 먼저 진행해줍니다. 화면의 특정 부분이 아직 보이지 않더라도, 유저는 페이지의 보이는 부분에선 상호작용을 할 수 있습니다.
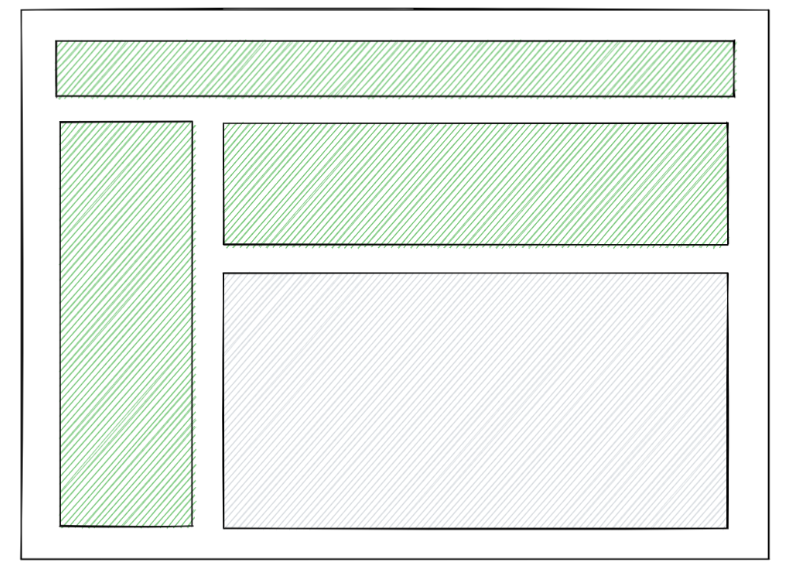
그림으로 보니 차이가 더 느껴지시나요? 이렇게 리액트는 한 단계 더 진화한 SSR 모델을 장착하게 되었습니다.
Streaming은 Suspense 경계로 동작하기 때문에 적용 또한 간단합니다. 아래와 같이 코드를 작성하면, Comments는 컴포넌트는 Streaming의 경계가 되고 Streaming 이전엔 Fallback UI를 노출합니다.
<Layout>
<NavBar />
<Sidebar />
<RightPane>
<Post />
<Suspense fallback={<Spinner />}>
<Comments />
</Suspense>
</RightPane>
</Layout>RSC
다음은 RSC입니다. RSC는 또 무엇이며, 왜 나왔을까요? 앞서 Streaming SSR로도 해결하지 못하는 문제가 있었던 걸까요? RSC에 대한 RFC 문서를 보면, 해당 질문에 대한 답을 얻을 수 있습니다.
문제의 핵심은 리액트는 여전히 클라이언트를 중심으로 동작하며, 서버를 충분히 활용하지 못하고 있다는 점입니다.
Streaming 방식을 사용한다고 해도 결국 서버는 초기 HTML을 만드는 과정에만 관여합니다. 초기 렌더링 과정 이후 라우팅을 비롯한 모든 작업은 클라이언트에서 사이드에서 진행되기 때문에 서버 자원을 최대로 활용한다고 보기 어렵습니다.
그래서 리액트 팀은 리액트를 서버를 조금 더 활용하는 방향으로 발전시키고자 했는데요. 그렇게 해서 등장하게 된 것이 바로 RSC 입니다.
RSC는 말 그대로 서버 환경에서 실행되는 컴포넌트를 의미합니다. 조금 더 강조하자면 서버에서'만' 실행되는 컴포넌트입니다. 클라이언트 사이드에서는 실행되지 않기 때문에 컴포넌트 내부에서 서버 자원에 접근하는 등 서버의 이점을 더 누릴 수 있습니다.
New Mental Model
서버 컴포넌트는 기존에는 없었던 개념이기 때문에 이해를 위해 약간의 배경 지식이 필요한데요. 이번에도 Dan이 작성한 "Why do Client Components get SSR'd to HTML?" 글의 일부를 살펴보며 서버 컴포넌트 동작 방식에 대해 더 자세히 살펴보도록 하겠습니다.
해당 글은 "왜 클라이언트 컴포넌트도 SSR이 되나요?"라는 질문에 대한 답변을 담은 글이지만, 새로운 리액트의 멘탈 모델에 대한 이해도를 높이기에도 아주 좋은 예제입니다.
우선, 기존의 리액트의 멘탈 모델에서부터 출발해 보겠습니다. 서버 컴포넌트가 없고 클라이언트 컴포넌트들만 존재하던 시절입니다.
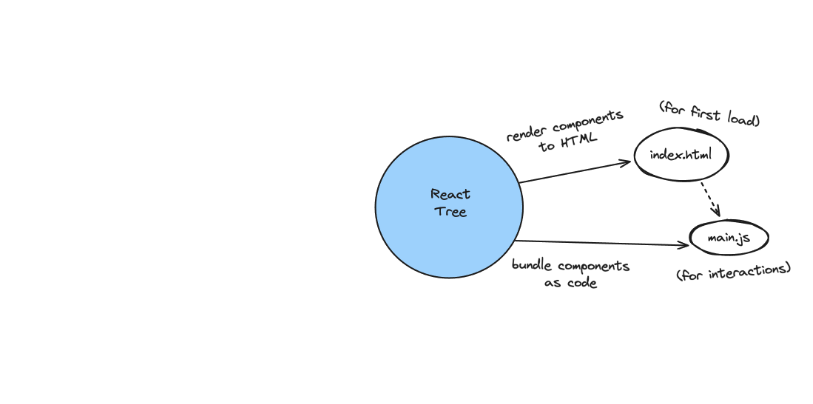
이제, 여기에 서버 컴포넌트로 구성된 서버 트리가 추가됩니다. 서버 트리는 서버 컴포넌트로 구성됩니다. 이 트리는 리액트 트리보다 먼저 실행되며 실행한 결과값을 리액트 트리로 넘겨줍니다.
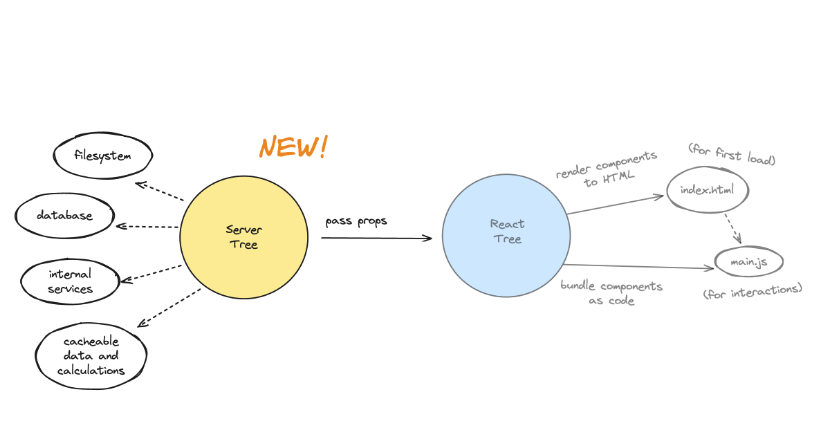
서버 트리는 클라이언트 사이드에서 실행되지 않기 때문에 파일시스템이나 데이터베이스 등 각종 서버 자원에 자유롭게 접근할 수 있습니다.
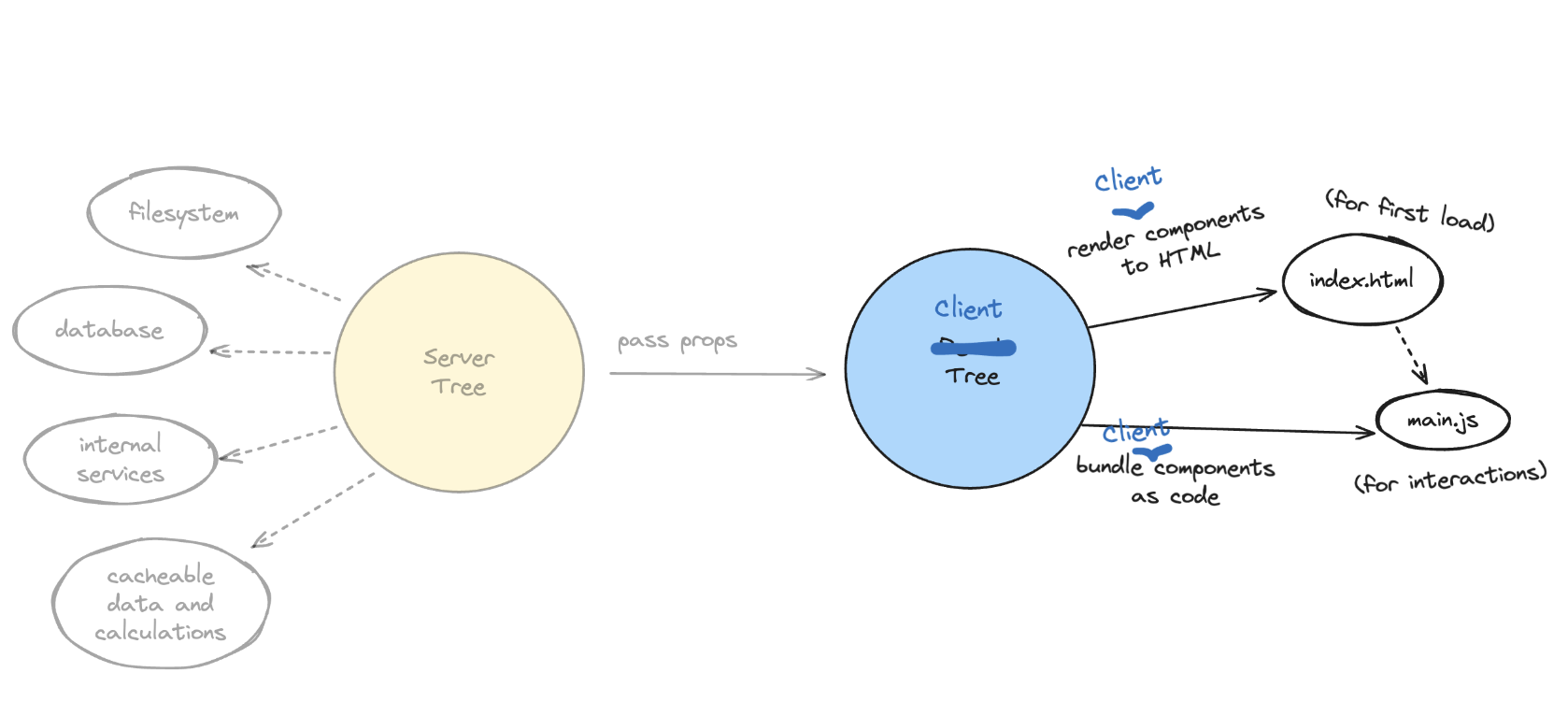
마지막으로 기존 리액트 트리에 서버 트리와 구분짓기 위해 클라이언트 트리라는 이름을 붙여줍니다. 클라이언트 트리라는 새로운 이름만 부여받았을 뿐 기존 리액트 모델에는 변화가 없습니다.
정리하면 기존의 리액트 모델은 유지되고, 새롭게 활용할 수 있는 서버 트리 레이어가 추가된 셈입니다. 이에 따라 개발자는 필요에 따라 렌더링 전략을 더 세밀하게 제어할 수 있게 되었습니다.
Benefits of RSC
그럼 이런 특성을 가진 서버 컴포넌트는 어떤 장점이 있을까요? 위에서 살짝 언급하긴 했지만, 서버 컴포넌트에서는 기존에 클라이언트 사이드에서 접근할 수 없었던 파일 시스템이나 데이터 베이스 등에 직접 접근할 수 있게 됩니다.
import fs from 'fs';
async function Note({id}) {
const note = JSON.parse(await fs.readFile(`${id}.json`));
return <NoteWithMarkdown note={note} />;
}물론, 컴포넌트 내에서 DB 접근도 가능합니다.
import db from 'db';
async function Note({id}) {
const note = await db.notes.get(id);
return <NoteWithMarkdown note={note} />;
}또한 서버 컴포넌트는 HTML의 형태로 클라이언트로 서빙되기 때문에 컴포넌트에서 내부에서 사용된 라이브러리를 번들 사이즈에 포함할 필요가 없습니다. 따라서 번들 사이즈도 획기적으로 줄일 수 있습니다.
서버 컴포넌트는 정확히는 RSC Payload라는 특별한 포맷으로 클라이언트로 전달되지만, 이 글에서는 이해를 돕기 위해 HTML로 설명합니다. 더 궁금하신 분들은 해당 글을 읽어보시길 권장드립니다.
이것도 코드로 한번 살펴봅시다. 아래는 우리가 기존에 클라이언트 컴포넌트를 활용할 때의 예시입니다. 브라우저에서도 해당 코드가 실행되어야 하기 때문에, 번들에 해당 라이브러리 코드를 포함해야 합니다.
// NOTE: *before* Server Components
import marked from 'marked'; // 35.9K (11.2K gzipped)
import sanitizeHtml from 'sanitize-html'; // 206K (63.3K gzipped)
function NoteWithMarkdown({text}) {
const html = sanitizeHtml(marked(text));
return (/* render */);
}만약 위 컴포넌트가 서버 컴포넌트로 전환된다면 어떨까요?
// Server Component === zero bundle size
import marked from 'marked'; // zero bundle size
import sanitizeHtml from 'sanitize-html'; // zero bundle size
function NoteWithMarkdown({text}) {
// same as before
}앞서 말씀드렸듯 서버 컴포넌트의 실행 결과물은 HTML이기 때문에 번들 사이즈에 기여하지 않습니다. 위의 예제의 경우 약 70KB의 번들을 줄일 수 있겠네요.
이렇게 서버 컴포넌트를 사용하면, 서버 리소스를 더 자유롭고 폭넓게 활용할 수 있게 됩니다.
Why RSC?
지금까지 RSC가 나온 기술적인 배경과, 간단한 예시를 살펴보았습니다. 그런데 사실 위에서 살펴본 예시들은 꼭 RSC를 사용하지 않고도 기존 서버 사이드에서 작업할 수 있는 것들입니다.
NextJS로 예를 들어보면 getServersideProps에서도 가능한 작업입니다. 그럼 RSC를 사용하는 것은 어떤 차이점을 가져다줄까요?
가장 크고 중요한 차이점은 해당 로직을 페이지 레벨이 아닌 컴포넌트 레벨로 내렸다는 것입니다. 그리고 이런 서버 컴포넌트는 전체 컴포넌트 트리 어디에서나 삽입될 수 있습니다. 아래 그림과 같이 말이죠.
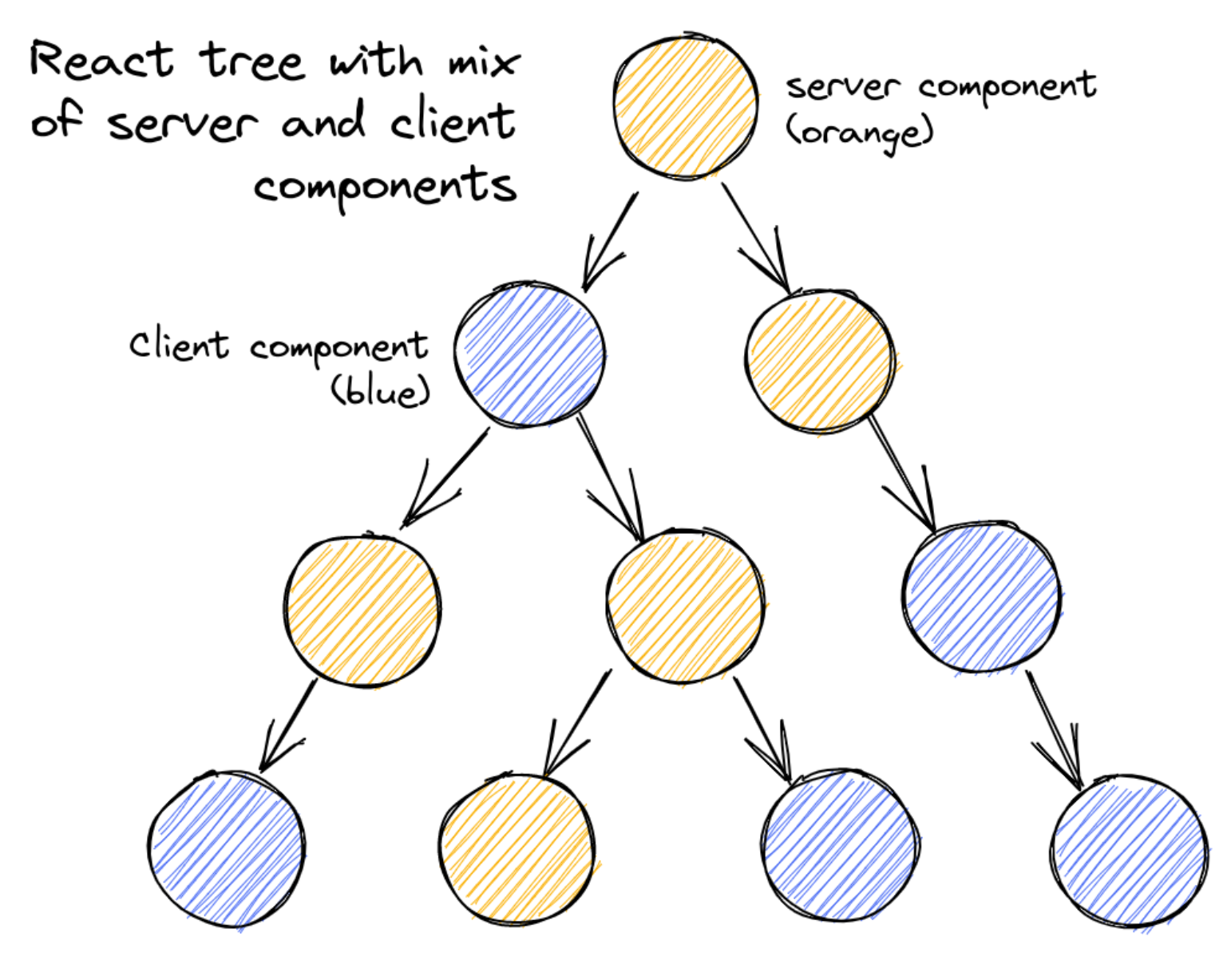
이렇게 컴포넌트 레벨에서 서버 접근이 가능하게 하고, 이를 Streaming ssr과 결합함으로써 기존 모델에 비해 훨씬 강력하고 유연한 모델을 갖게 됩니다.
마치며
RSC를 처음으로 구현한 App router가 출시된지 어느덧 1년이 훌쩍 넘었습니다. 그러나 레딧과 같은 해외 커뮤니티를 보면 App router는 여전히 뜨거운 감자 같은 녀석입니다.
출시 초기와 같이 "이건 PHP시대로의 회귀다!!", "이건 그냥 복잡한 똥덩어리다(이런 얘기는 없었을 수도 있습니다)"와 같은 강한 반감을 표하는 글은 많이 줄어든 듯 하지만, 기존 Page Router의 간결함을 좋아하던 사람들에게는 아직 큰 지지를 얻지 못하고 있는 듯 합니다.
심지어 Nextjs github discussion을 보면 page router vs app router와 같은 vote도 올라와 있더라구요. page router가 압도적으로 이기고 있는데, 제가 vercel 개발자라면 꽤나 슬플 것 같습니다.
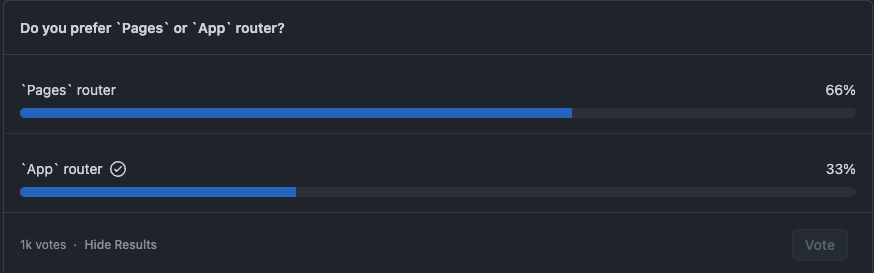
RSC 반대파의 의견을 살펴보면, DX는 낮아지고 복잡도는 높아진게 불호의 주된 이유입니다. 어느정도 동의하는 부분입니다.
저 또한 1년 정도 App router를 사용해오면서 개발 경험이 좋지 않다는걸 많이 느꼈거든요. 특히 Next 14 초반에는 App router 자체 버그가 꽤나 많기도 했구요. 지금은 많이 개선되었지만 여전히 갈 길이 먼 부분이라 느껴집니다(쌓여있는 이슈들 처리좀 해라...).
또 서버 컴포넌트의 사용은 전체적인 어플리케이션 복잡도를 확실히 높이는 것 같습니다. 기본적으로 클라이언트 컴포넌트인지 서버 컴포넌트인지 계속 신경쓰면서 개발해야 하고, 생각보다 서버 컴포넌트의 제약사항이 꽤 있기 때문에 잘 활용하려면 많은 고민이 필요하기도 하구요.
최근 리액트의 행보에는 이런 저런 의견이 많지만 개인적으로는 리액트가 더 똑똑한 아키텍쳐를 가지게 되었다고 생각합니다. 더 잘 깎아서 좋은 성능의 어플리케이션을 개발할 수 있도록 만들어 주었기 때문이죠.
사실 한국에서 서비스를 하는 경우에 대부분의 경우 성능은 큰 문제가 되지 않는 경우가 많습니다. 대다수의 유저가 최신 기기를 사용하고 네트워크 인프라도 훌륭하기에, 어플리케이션의 동작에만 집중해서 만들어도 준수한 서비스를 제공하기에 무리가 없거든요.
하지만 글로벌 서비스를 운영하면서, 디지털 격차는 여전히 크다는걸 알게 되었습니다. 아직도 10년 전 기기를 쓰는 유저가 꽤 많다는것도, 세상에는 정말 다양한 모바일 기기가 있다는 것도, 갤럭시 A15 시리즈는 여전히 현역이라는 것도, 크롬 네트워크 탭에 3G 쓰로틀링이 옵션이 괜히 있다는게 아니라는 것도요..😂
이렇게 원활하지 않은 네트워크 환경에서 저사양 기기로 접속하는 유저가 대부분인 환경이라면 단순 몇 KB의 번들 사이즈 개선도 유저 지표에 유의미한 영향을 미칩니다. 이러한 맥락에서 리액트 18버전은 큰 의미가 있다고 생각하고, 앞으로도 기대해 볼 여지가 많은 것 같습니다. 개발자 입장에서 이런 변화를 잘 활용해 통해 더 많은 사용자에게 준수한 성능을 제공할 수 있다면, 이 또한 넓은 의미에서의 접근성 준수가 아닐까요?ㅎㅎ
점점 주저리 주저리가 되는 것 같아 후기는 여기까지 하도록 하겠습니다. 그럼 긴 글 읽어주셔서 감사합니다.

좋은 글 감사합니다!!👍👍