정규화란 ?
정규화의 목표는 테이블 간 중복된 데이터를 허용하지 않는 것이며, 관게형 데이터베이스에서 중복을 최소화하기 위해 데이터를 구조화하는 작업이다.
데이터 중복이 발생하게 된다면 ?
우선 동일한 데이터가 여러 테이블에 중복 저장된다는 것은 저장공간의 낭비가 발생하게 되며, 데이터 중복에 의해 발생하는 문제인 이상현상 이 생길 수 있게 된다.
이상현상(Anomaly) 의 종류
-
삽입이상
: 불필요한 정보를 함께 저장하지 않고서는 어떤 정보를 저장하는 것이 불가능하다.
-
삭제이상
: 필요한 정보를 함께 삭제하지 않고서는 어떤 정보를 삭제하는 것이 불가능하다
-> 원치않은 정보도 함께 삭제해야 하는 것.ex) 수강정보 테이블 내 학생정보와, 현재 수강 중인 과목 정보가 함께 들어있다고 가정했을 때, 만약 해당 과목이 폐강될 경우 ? 해당 과목정보를 삭제하게 되면서 학생 정보까지 함께 삭제되는 현상
-
갱신이상
: 반복된 데이터 중 일부를 갱신할 때 데이터의 불일치가 발생한다.
이러한 이상현상은 정규화(Normalization)을 이용하여 방지할 수 있음 !!
정규화된 결과를 정규형이라고 하며, 정규형은 기본정규형, 고급 정규형으로 나뉜다.
- 기본정규형 : 제1정규형, 제2정규형, 제3정규형, BCNF(보이스/코드정규형)
- 고급정규형 : 제4정규형, 제5정규형
제 1 정규형
릴레이션에 속한 모든 속성의 도메인이 더 이상 분해되지 않는 원자값으로 구성된 정규형이다.
제 2 정규형
릴레이션이 제1정규형에 속하고, 기본키가 아닌 모든 속성이 기본키에 완전 함수 종속되면 제2정규형에 속한다. -> 부분 함수 종속을 제거해야한다.
제 3 정규형
제 3 정규형은 제 2 정규화를 진행한 테이블에 대해 이행적 종속이 없도록 테이블을 분해하는 것이다. 기본키 이외 다른 컬럼이 그외 다른 컬럼을 결정할 수 없는 것 !!!
- 이행종속이란 ? A -> B, B -> C 가 성립할 때, A -> C가 성립되는 것을 뜻함.
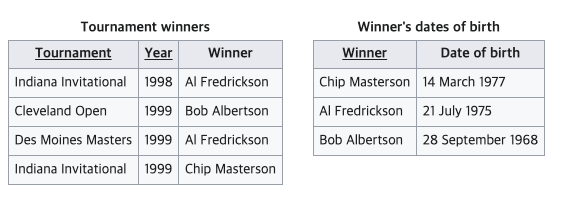
ex)

위 테이블의 후보키는 (Tournament, Year) 이 되는데, Winner Date of Birth 는 Winner에 의존하는 것을 볼 수 있으며 Winner를 통해 후보키에 종속되고 있다.
따라서 아래와 같이 테이블을 분리하게 되면 제 3 정규형을 만족하게 된다.
BCNF
제 3 정규형을 만족하면서, 모든 결정자가 후보키집합에 속하면 BCNF를 만족한다.
-> 모든 결정자가 후보키 집합에 속해야 한다는 뜻은, 후보키 집합에 없는 컬럼이 결정자가 되어서는 안된다.
정규화의 장점
- 데이터베이스 변경 시 이상현상들이 발생하는 문제를 해결할 수 있다.
- 정규화된 데이터베이스 구조는 새로운 데이터 형의 추가로 인한 확장 시, 그 구조를 변경하지 않아도 되거나 변경해야할 것을 최소화합니다.
정규화의 단점
- 릴레이션 분해로 인해 테이블 간 Join 연산이 많아지기 때문에 질의에 대한 응답 시간이 느려질 수 있다. -> 이와 같은 성능저하 문제는 반정규화로 해결 가능.
