
Elasticsearch란?
Elasticsearch는 Apache Lucene(아파치 루씬) 기반의 Java 오픈소스 분산 검색 엔진입니다.
Apache Lucene은 검색 라이브러리인데 이를 단독으로 사용할 수 있게 되었으며, 방대한 양의 데이터를 신속하게, 거의 실시간으로 저장, 검색, 분석할 수 있습니다.
Elastic Searchsms 검색을 위해 단독으로 사용되기도 하며, ELK(Elasticsearch + Logstatsh + Kibana) 또는 EFK(Elasticsearch + Fluentd + Kibana) 스택으로 사용되기도 합니다.
EFK Stack
- Elasticsearch
- Fluentd로 받은 데이터를 검색 및 집계를 하여 필요한 관심 있는 정보를 획득 - Fluentd
- 다양한 데이터 소스(HTTP, TCP)등으로부터 데이터를 받아 원하는 형태로 가공한 후 다양한 목적지(Elasticsearch, S3, HDFS 등)로 전달 - Kibana
- Elasticsearch의 빠른 검색을 통해 데이터를 시각화 및 모니터링
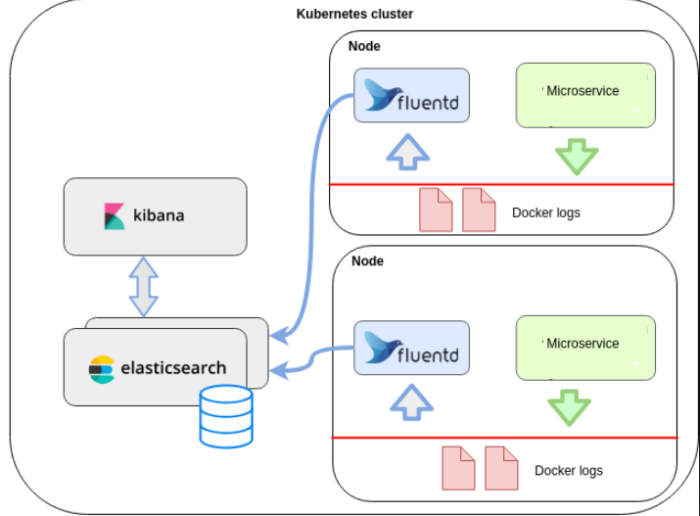
출처 : https://www.techmanyu.com/microservices-logging-using-efk/
Elasticsearch 아키텍처

1. cluster
클러스터란 Elasticsearch에서 가장 큰 시스템 단위를 말하며, 최소 하나 이상의 노드들로 이루어진 집합입니다.
서로 다른 클러스터는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템으로 유지되며,
여러 대의 서버가 하나의 클러스터를 구성할 수도 있고, 한 서버에 여러 개의 클러스타가 존재할 수도 있습니다.
2. node
Elasticsearch를 구성하는 하나의 단위 프로세스를 의미합니다.
그 역할에 따라 Master-eligible, Data, Injest, Tribe 노드로 구분할 수 있습니다.
3. Index / Shard / Replica
샤딩(Sharding)은 데이터를 분산해서 저장하는 방법을 의미합니다.
Elasticsearch의 스케일 아웃을 위해 index를 여러 shard로 쪼갠 것입니다.
기본적으로 1개가 존재하며, 검색 성능 향상을 위해 클러스터의 샤드 갯수를 조정하는 튜닝을 하기도 합니다.
replica는 또 다른 형태의 shard라고 할 수 있습니다.
노드를 손실했을 경우 데이터의 신뢰성을 위해 shard를 복제하는 것입니다.
Elastic 구조
논리적 구조
- Document
Elasticsearch 데이터 최소 단위(RDBMS의 row와 비슷).JSON 오브젝트하나.
하나의Document는 다양한 필드로 구성되어 있으며, 이 필드에는 데이터 필드에 해당하는 데이터 타입이 들어갑니다. 중첩구조를 지원하기 때문에 Document 내부에 Document가 들어가는 것이 가능합니다.
- Type
여러 개의 Document가 모여서 하나의 Type을 이룹니다. 하지만 Elasticsearch 7.0부터 Type이 완전히 사라졌으며, 현재Index가 RDBMS의Table과Database의 역할을 모두 한다고 생각하면 되겠습니다.
- Field
필드는 Document에 들어가는 데이터 타입으로 RDBMS의 열(column)과 비슷합니다. 하지만 Elasticsearch의 필드는 RDBMS보다 동적입니다. RDBMS에서는 하나의 열이 하나의 데이터 타입만 가질 수 있었지만, Elasticsearch에서는 하나의 필드가 여러개의 데이터 타입을 가질 수 있습니다.
- Mapping
매핑은 필드와 필드의 속성을 정의하고 색인 방법을 정의합니다. 매핑 정보에 여러가지 데이터 타입 지정이 가능하지만 필드명 자체는 중복이 불가능합니다.
- Index
RDBMS의Database+Table의 역할을 합니다.
Elasticsearch를클러스터로 구성했을 경우 Index는 여러 노드에 분산 저장/관리됩니다. 기본 설정은 5개의프라이머리 샤드와 1개의레플리카 샤드를 생성합니다.
샤드 수는 인덱스 생성 시 옵션 값을 이용하여 변경이 가능합니다.
Elasticsearch 특징
- Scale out
샤드를 통해 규모가 수평적으로 증가 가능 - 고가용성
Replica를 통해 데이터의 안정성을 보장 - Schema Free & 문서 중심
Json 문서를 통해 데이터 검색을 수행하므로 스키다 개념이 없음
모든 필드는 기본적으로 인덱싱되며, 모든 익덱스들은 단일 쿼리로 빠르게 검색 및 활용할 수 있음 - Restful & 플러그인 형태로 구현
데이터 CRUD 작업은 HTTP Restful API를 통해 수행
검색엔진을 직접 수행하지 않고, 필요한 기능에 대한 플러그인을 적용하여 기능을 확장할 수 있음
Elasticsearch가 빠른 이유
Elasticsearch가 빠르게 검색을 실행할 수 있는 이유는 inverted index에 있습니다.
Elasticsearch는 텍스트를 파싱해서 검색어 사전을 만든 다음에 inverted index 방식으로 텍스트를 저장합니다.
예를 들어,
Elasticsearch is based on Apache Lucene Library
위의 문장을 모두 파싱해서 Elasticsearch,is,based ,on,Apache,Lucene,Library 처럼 저장 후 대문자를 소문자로 처리하고, 유사어 체크와 같은 작업을 진행하여 텍스트를 저장합니다.
