- R 공부를 시작하고 2달... 이제는 기본 문법을 찾아가면서, 추가로 배워가면서 프로그램 행간의 의미를 파악하는 수준에 도달한 것 같다.
★ [학습목표]
1) 외부 sample data set을 R로 import
2) Data 전처리(EMD) 과정 실습
: Melt down, munging, bining , encoding 등의 과정 연습
1) Raw DB 확보
2) Cleanzing : 데이터 Review (결측치, 이상치, 정규화 등)
3) Data Trimming (categorize) : 예) subset.data.frame(data, select=c("column1","column2"))
4) Data Munging : 날짜 데이터를 문자로 변경, 숫자로 추출, 주차 추출 등
5) 기술적 통계(평균, 분산 등) 및 EDM : 구조(숫자, 문자 등)를 파악해야함
6) 표본검사 : 표본 추출 시 난수 추출법
7) 데이터 구분 (모델개발/학습용, Test 용)
8) 모델 결정 (신경망 등)
9) 분석 및 결과 Report
예로 사용한 DATA는 Titanic 생존자 정보를 사용하겠다.

- 결측치 확인 및 제거
## 전처리 preprocessing
library(dplyr) # dplyr 패키지 : 데이터 전처리 관련
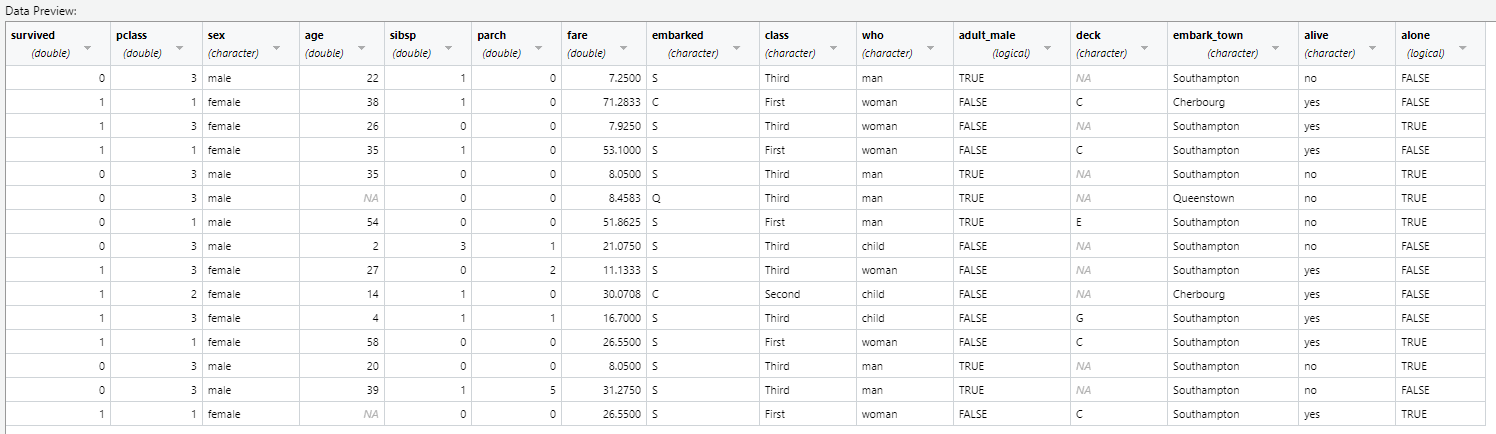
pretitanic <- read.csv("preprocess_titanic.csv") # 데이터 import
head(pretitanic) # 데이터 상위 10개말 보여줌
is.na(pretitanic) # NA의 존재여부를 확인함
sum(is.na(pretitanic)) # NA의 갯수를 확인함
sum(is.na(pretitanic$survived)) # 대용량 데이터는 column별로 확인이 가능
sum(is.null(pretitanic)) # null 갯수를 확인함 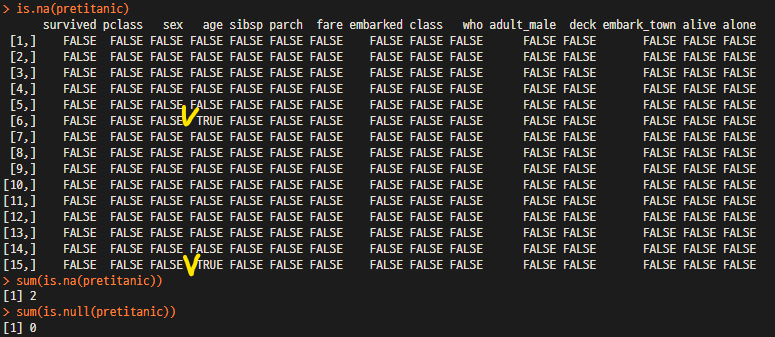
summary(pretitanic)
pred_titanic <- na.omit(pretitanic) # NA가 포함된 행 2개 제거 후 다른이름으로 저장
pred_titanic
summary(pred_titanic)
sum(is.na(pred_titanic))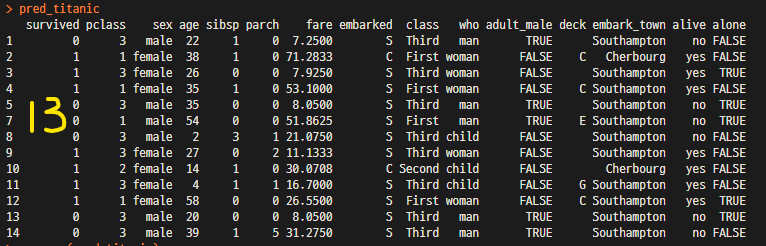
- 결측치 대체
pretitanic[is.na(pretitanic$age),] # age column에 NA인것 추출
pretitanic$age[is.na(pretitanic$age)]=25 # NA인것에 25로 입력
pretitanic[c(6,15),] # 수정되었는지 6행,15행을 출력해봄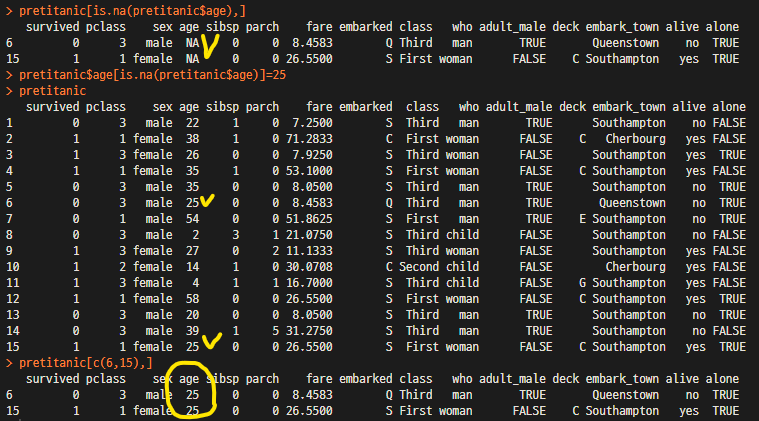
- 데이터 선택 (Filter, Select)
: 원하는 Row(filter), column(select)들 만 추출 할 수 있다.
pretitanic <- read.csv("preprocess_titanic.csv")
filter(pretitanic, pclass ==3, sex=="female", age>=25) # filter 사용법 ※ 주의 "=="
select(pretitanic, pclass, sex, age) # select 사용법 ※ 주의 ""사용없음, 벡터 아님, 경로지정 없음.
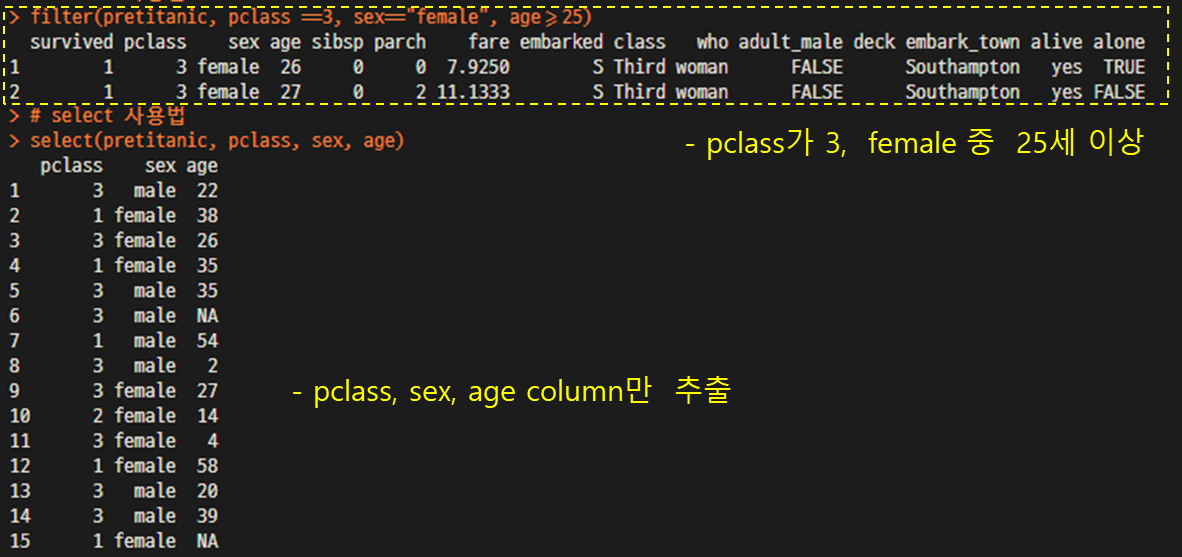
- column 추가
mutate(pretitanic, agefare=age/fare) # agefarte column 추가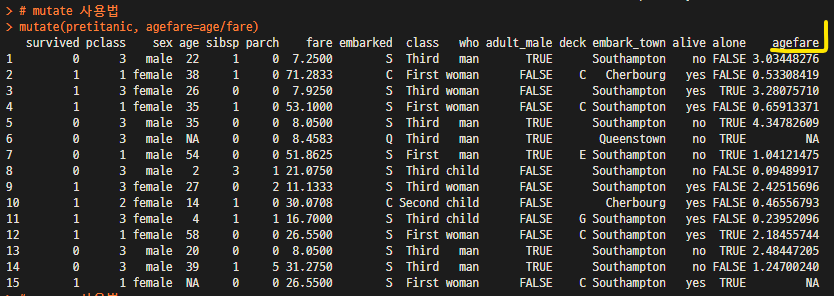
- 정열 : 오름차순으로 정렬(default)
arrange(pretitanic, pclass, age)
- Chain 기능 : %>% 파이프 연산자
library(dplyr)
select(pretitanic, pclass, sex, age) # 3개의 column을 추출
resulttitanic <- pretitanic %>% select(pclass, sex, age) %>% arrange(pclass)
# 3개의 column중 pclass 기준으로 정렬
resulttitanic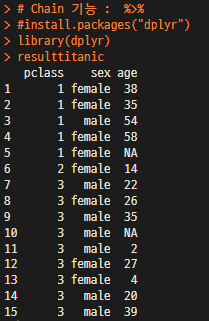
- 그룹 별로 모아서 평균 등의 통계자료 출력
# summarise 사용법
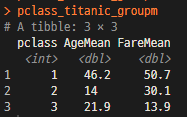
pclass_titanic <- arrange(pretitanic, pclass)
pclass_titanic_group <- group_by(pclass_titanic,pclass) # pclass 기준으로 그룹핑
pclass_titanic_groupm <- summarise(pclass_titanic_group, AgeMean=mean(age),
FareMean=mean(fare)) # 그룹핑된 자료에 나이평균과 요금평균 column을 만든다. 이자료는 data.frame을 만들어 별도 사용도 가능함.
pclass_titanic_groupm
pclass_titanic_group <- na.omit(pclass_titanic_group) # NA를 제거하여 올바르게 평균값을 표현할 수 있음.
pclass_titanic_groupm <- summarise(pclass_titanic_group, AgeMean=mean(age), FareMean=mean(fare))
pclass_titanic_groupm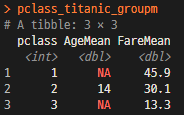
NA를 제거하여 재출력한 경우