[R] Data pre-processing
★ [학습목표]
공공데이터 중 신문고 데이터를 이용한 데이터 처리방법을 이해한다.
-
Raw data를 확인한다.
-
Data의 Dimension(차원)와 Structure(구조), 그리고 column들의 name, 상위/하위 5개의 데이터를 확인하여 데이터를 간단히 리뷰한다.
dim(df) # Raw Data의 차원 확인
str(df) # Raw Data의 구조 확인
colnames(df) # Raw Data의 Column의 이름을 확인
head(df,5) # Raw Data의 상위 5개의 데이터 확인
tail(df,5)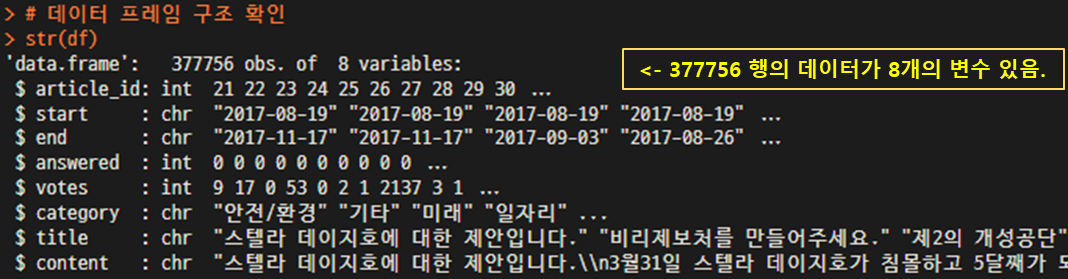
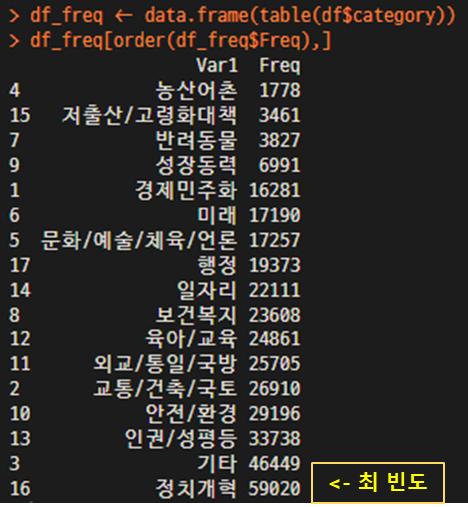
- 필요한 column을 선정하여 추출한다. 데이터의 빈도도 확인하고, 필요한 항목을 선정한다.
table(df$category)
df_freq <- data.frame(table(df$category))
df_freq[order(df_freq$Freq),]
- 날짜 데이터를 정량화 한다.
※ 기간을 정의하기 위해 데이터 연산시 문자형식의 날짜는 적용이 어렵기 때문에 "date" 타입으로 전환하여 별도의 column 정의 필요!!!
df$start_date <- as.Date(df$start) # 문자를 날짜(date)로 변환.
# 단, 데이터 보존을 위한 파생변수 사용 권장
df$end_date <- as.Date(df$end)
df-
이해하기 쉽게 column 이름을 재설정한다.
-
주어진 column의 산술계산(평균 등)으로 column을 추가한다.
-
NA, Null 값, 이상치(box plot 등) 등을 확인하여 후처리한다.
is.na(df)
colSums(is.na(df)) # column별 결측치의 갯수를 확인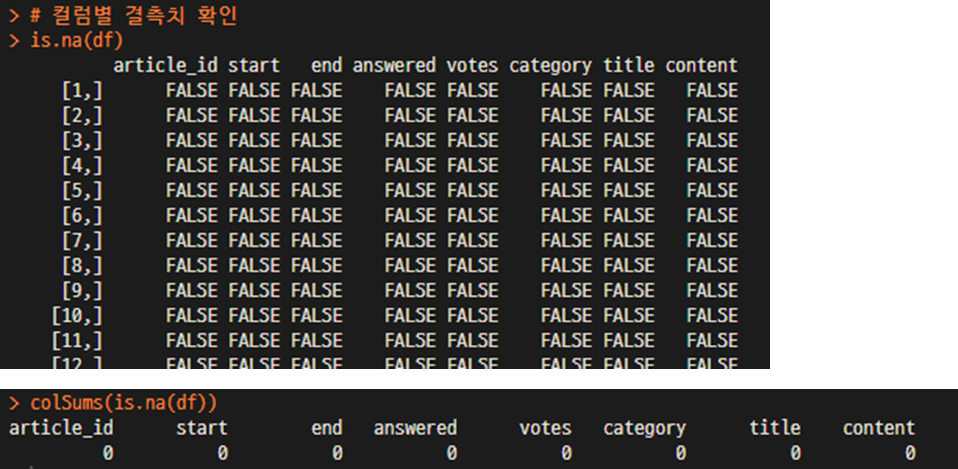
- 데이터를 조건에 맞춰 그룹핑 한다.
# 파생변수[answer] : 답변대상 청원
# answerd : 청와대 답변 여부.
df$answer <- df$votes > 200000 # 20만개 이상의 동의 ==> 답변 대상 청원
dim(df)
df$duration <- df$end_date - df$start_date # 기간 계산을 위해 날짜 데이터 이용
df[order(df$duration),]
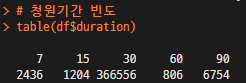
# 청원기간 빈도
table(df$duration)
# 청원기간이 30일이고 답변 대상인 건
str(df)
df[(df$duration == 30) & (df$answer == 1),]
# 청원기간이 90일이고 답변 대상 건
df_90_answer <- df[(df$duration == 90) & (df$answer == T),]
cat(dim(df_90_answer))
head(df_90_answer)
# 청원기간이 7일
df_7 = df[(df$duration == 7),]
head(df_7)
- 기숱통계 자료를 확인한다.
※ Mean값과 Median값을 비교하여 정규성 및 분포도를 대략 Review가 가능
summary(df)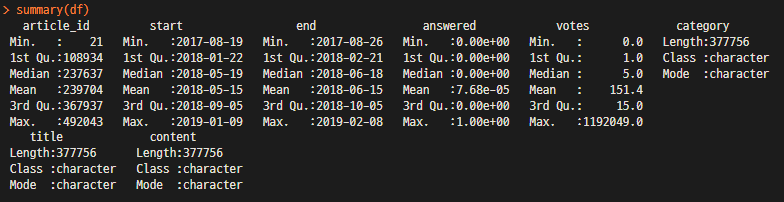
- 독립변수와 종속변수를 구분하여 Data를 구조화 한다.
별도의 과정으로 설명예정....
- 독립변수의 갯수와 종속변수의 갯수에 따라 추론통계법을 적용하여 데이터를 분석한다.
예) 1개의 독립변수와 3개의 종속변수가 있을 경우 ANOVA를 통해 평균의 차별성을 검증한다.
