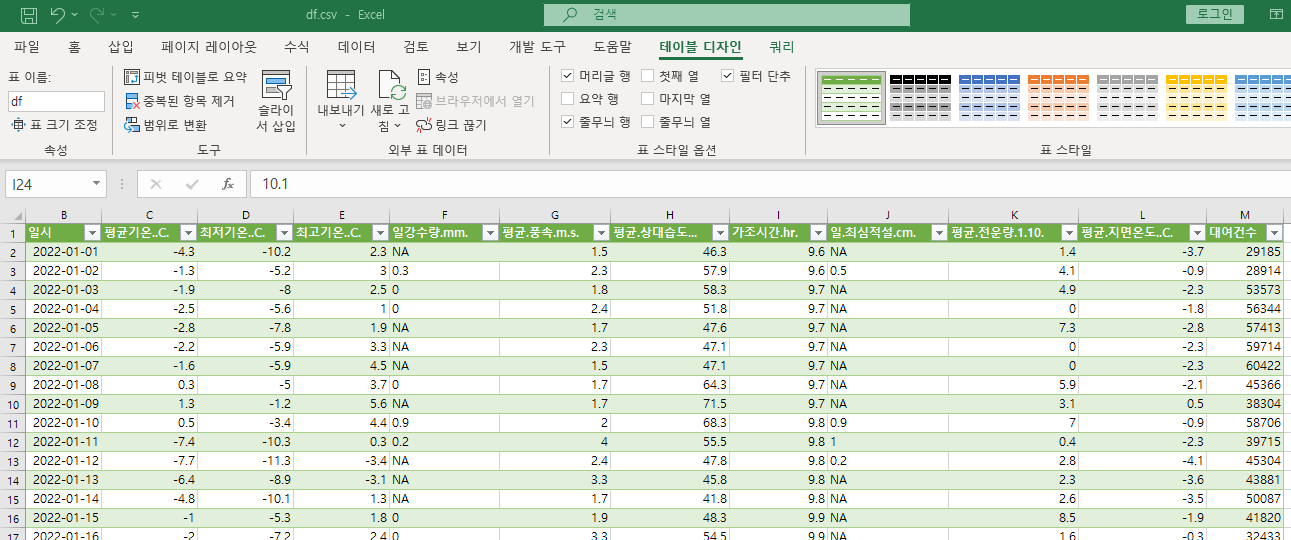
[R] 공공데이터
★[학습목표]
공공데이터를 Wed에서 Download 받아서 분석할 수 있다.
기상청 1년치 날씨데이터와 서울 자전거 대여건수 상,하반기 2개 데이터를 병합하여 기상청 데이터와 비교를 할 수 있다.
ref) https://data.kma.go.kr/data/grnd/selectAsosRltmList.do?pgmNo=36
1. (1단계) 날씨 데이터 Review
# 기후 데이터 (365일)
library(dplyr)
getwd() #작업 Directory 확인
df1 <- read.csv("SURFACE_ASOS_copy.csv", fileEncoding="euc-kr")
※ 주의 대부분의 파일은 Utf-8(2바이트를 한문자로 인식)의 형식인데,
한글이 포함되어 있을 경우 읽기에 문제가 발생한다.
이를 해결하기위해 file의 형식을 euc-kr(완성형)으로 변경후 읽어야한다.
head(df1)
tail(df1)
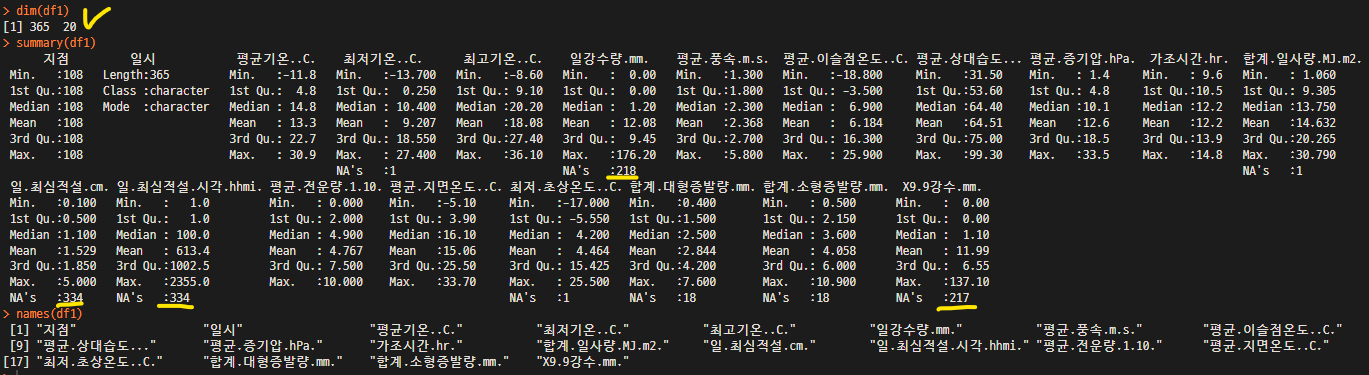
dim(df1) # Data Dimension 확인
summary(df1) # Data 기술통계량 확인
names(df1) # Data Column 이름 확인
colSum(is.na(df1)) # Data Column별 NA 갯수 확인 가능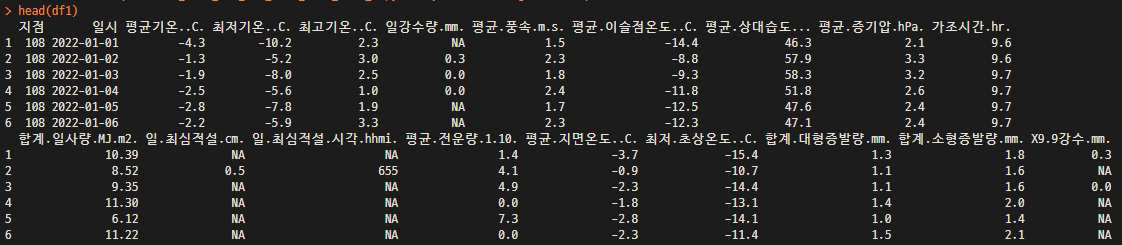
- 20개의 변수에 365개의 데이터가 존재함
- Column 별 결측치를 확인할 수 있다. 예) 강수량은 365일중 217개가 NA 이다.
- df1(날씨) 데이터에 df4(자전거 대여건수) 데이터를 병합하는 방법
- 또는, df1(날씨) 데이터 중 "평균기온"의 3배의 값을 column으로 만들어 비교도 가능
2. 자전거 대여건수 정보 Data Review
- 22년도 df2(상반기 181개)와 df3(하반기 184개) 데이터로 구분되어 있음.
- 두개의 데이터를 Rbind로 365개의 파일 df4로 병합
# 1년치의 데이터를 통합
df4 <- rbind(df2,df3)
dim(df4)3. 날씨 정보와 자전거 데여건수 정보의 병합
# 자전거 대여건수와 날씨데이터를 병합
df1$대여건수=df4$대여건수 # df1 대여건수 변수를 생성, df4 대여건수 데이터를 입력(A)
df1$대여건수.estimate=df1$평균기온..C.*3 # df1 대여건수.estimate 변수생성, 평균기온*3 값으로 입력(B)
df1
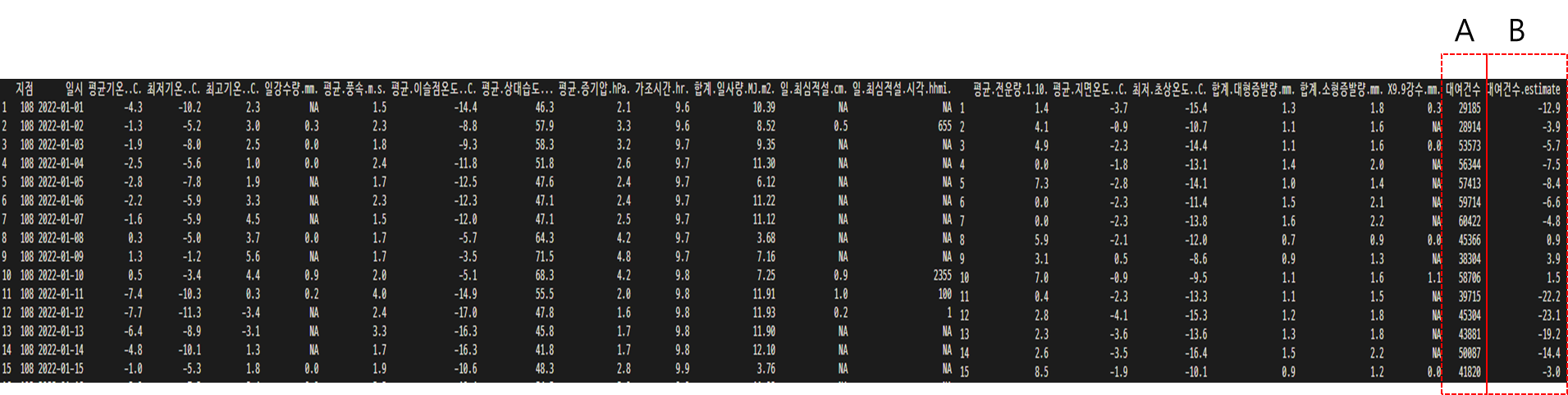
- 데이터의 결측치를 확인하여 제거하거나, 다른 값으로 대체하여 입력도 가능함
4. 통합정보 결측치 처리
# 결측치
is.na(df) #결측치 여부 확인
sum(is.na(df)) #결측치 갯수 확인
table(is.na(df)) # 결측치 여부 빈도 확인
complete.cases(df) # 결측치 미존재 여부 확인
table(complete.cases(df)) # 결측치 미존재 여부 빈도 확인
df[!complete.cases(df),] # 결측치 행 확인
# 결측치 0으로 대체
df$최저기온..C.[is.na(df$최저기온..C.)]=0
df$일강수량.mm.[is.na(df$일강수량.mm.)]=0
df$일.최심적설.cm.[is.na(df$일.최심적설.cm.)]=0
summary(df)
sum(is.na(df))
# 평균기온에 대한 년간동일온도개수
df %>% count(평균기온..C.) # group_by() %>% summarise(n=n()) : Unique Value Count
a <- count(df,평균기온..C.) # group_by() %>% summarise(n=n()) : Unique Value Count5. 통합정보 중 선택적 정보만 추출
# 데이터 분석을 위한 컬럼 삭제
df <- df1[names(df1) %in% c("일시","평균기온..C.","최저기온..C.","최고기온..C.","일강수량.mm."
,"평균.풍속.m.s.","평균.상대습도...","가조시간.hr.","일.최심적설.cm."
,"평균.전운량.1.10.","평균.지면온도..C.","대여건수" )]
df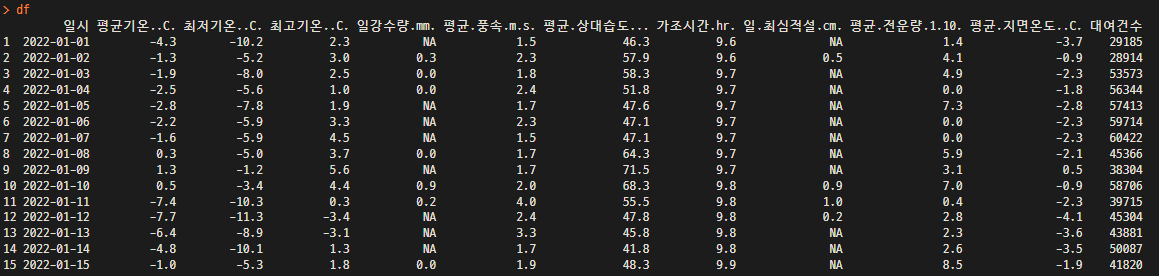
6. 데이터간의 상관성을 분석
# 평균기온에 대한 년간동일온도개수
df %>% count(평균기온..C.) # group_by() %>% summarise(n=n()) : Unique Value Count
a <- count(df,평균기온..C.) # group_by() %>% summarise(n=n()) : Unique Value Count
a
plot(a[,1],a[,2], col="Blue", ylab="년간동일온도개수"
, xlab="평균기온..C.")
# 평균기온에 대한 대여건수
plot(df$평균기온..C.,df$대여건수, ylab="자전거 대여건수"
, xlab="평균기온..C.")
correlation <- cor.test(df$평균기온..C., df$대여건수) # 두개의 변수간 상관성을 검증하는 방법, P-value 가 0.05 이하라면 상관성이 있다는 대립가설이 채택됨
correlation
# 일강수량에 대한 대여건수
plot(df$일강수량.mm.,df$대여건수, ylab="자전거 대여건수"
, xlab="일강수량.mm.")
# 상대습도에 대한 대여건수
plot(df$평균.상대습도...,df$대여건수, ylab="자전거 대여건수"
, xlab="평균.상대습도...")
# 가조시간에 대한 대여건수
plot(df$가조시간.hr.,df$대여건수, ylab="자전거 대여건수"
, xlab="가조시간.hr.")
# 일 최심적설에 대한 대여건수
plot(df$일.최심적설.cm.,df$대여건수, ylab="자전거 대여건수"
, xlab="일.최심적설.cm.")
# 평균전운량에 대한 대여건수
plot(df$평균.전운량.1.10.,df$대여건수, ylab="자전거 대여건수"
, xlab="평균.전운량.1.10.")
# 평균지면온도에 대한 대여건수
plot(df$평균.지면온도..C.,df$대여건수, ylab="자전거 대여건수"
, xlab="평균.지면온도..C.")
# 상관관계 구하기
corData <- cor(df[,c(2:11)], use = "all.obs", method="pearson")
corData
round(corData,2)
corData
## 상관관계 그림(heatmap)으로 표현하기
install.packages("ggcorrplot")
library(ggcorrplot)
ggcorrplot(round(corData,2))
# 상관 행렬
pairs(df)
str(df)
pairs(df[,c(2:11)])
pairs(iris)
str(iris)- 지면온도와 자전거 대여건수와의 상관성 산점도로 확인
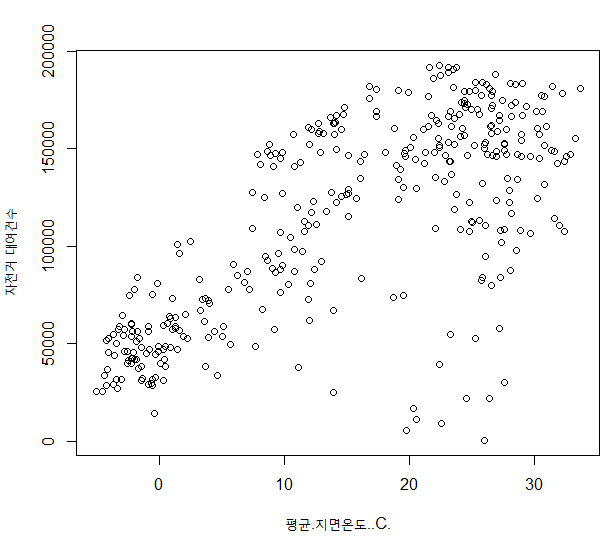
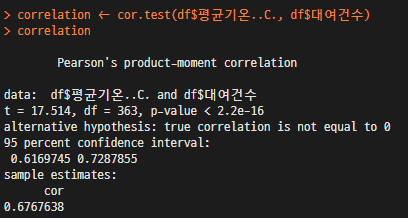
-
각 인자별 상관성을 종합적으로 가시화가 가능
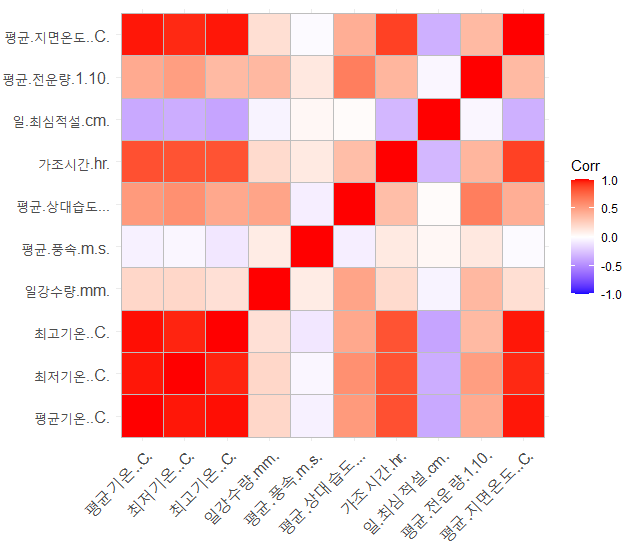
-
상관행렬도 확인이 가능함.
pairs(df[,c(2:11)])

7. 선택된 최종 정보을 .csv 파일로 별도 저장
- 정리된 또는 전처리된 데이터를 .csv 파일로 저장할 수 있음.
df.sum<-data.frame(df) # df를 data.frame의 형태로 df.sum에 입력
write.csv(df.sum, file = "./test/df.csv") # df.sum를 work directory 하위폴더 test에 df.csv 파일생성
write.csv(df.sum, file = "./test/df.csv", fileEncoding = "CP949")- 주의사항 csv(엑셀 등) 저장시 utf-8이 기본이라 한글이 깨질수 있어서, fileEncording을 CP949로 지정하여 호환성을 증대시킬수 있음.
- CP949는 한글 문자를 위한 마이크로소프트 윈도 시스템에서 널리 사용되는 문자 인코딩 방식입니다. 한글 외에도 한자, 알파벳 등을 포함한 다양한 문자를 지원합니다.
CP949는 한국어 전용 문자 인코딩이기 때문에 한국에서 주로 사용됩니다.
- CP949는 한글 문자를 위한 마이크로소프트 윈도 시스템에서 널리 사용되는 문자 인코딩 방식입니다. 한글 외에도 한자, 알파벳 등을 포함한 다양한 문자를 지원합니다.