
BLEU: a Method for Automatic Evaluation of Machine Translation (a.k.a. BLEU score)
This page is posted for explaining the BLEU score.
BLEU Score (BiLingual Evaluation Understudy)
1. What is the 'BLEU Score'?
Evaluation metrics in Translation, Summarization, and similar NLG(Natural Language Generation) tasks.
Translation Evaluatation
Summarization Evaluatation

2. How to evaluate BLEU Score.
(1) N-gram precision
- Evaluate how much machine-translation and human-transalation overlap by n-gram (n = 1~4).
- Machine - translation : 빛이 쐬는 노인은 완벽한 어두운곳에서 잠든 사람과 비교할 때 강박증이 심해질 기회가 훨씬 높았다
- Human - transalation : 빛이 쐬는 사람은 완벽한 어둠에서 잠든 사람과 비교할 때 우울증이 심해질 가능성이 훨씬 높았다
(2) Modified Uni-gram precision
1) Clipping
- Correct the overfitting when the same word occurs consecutively.
- Machine - translation : The more decomposition the more flavor the food has
- Human - transalation : The more the merrier I always say
2) Brevity Penalty
- Correct the overfitting about sentence length.
- Machine - translation : 빛이 쐬는 노인은 완벽한 어두운곳에서 잠듬
- Human - transalation : 빛이 쐬는 사람은 완벽한 어둠에서 잠든 사람과 비교할 때 우울증이 심해질 가능성이 훨씬 높았다
(3) Modified N-gram precision
(4) BLEU Score
- Machine - translation : 빛이 쐬는 노인은 완벽한 어두운곳에서 잠든 사람과 비교할 때 강박증이 심해질 기회가 훨씬 높았다
- Human - transalation : 빛이 쐬는 사람은 완벽한 어둠에서 잠든 사람과 비교할 때 우울증이 심해질 가능성이 훨씬 높았다
score resultprint(min(1, 14/14) * (10/14 * 5/13 * 2/12 * 1/11)**(1/4))(result) 0.25400289715190977



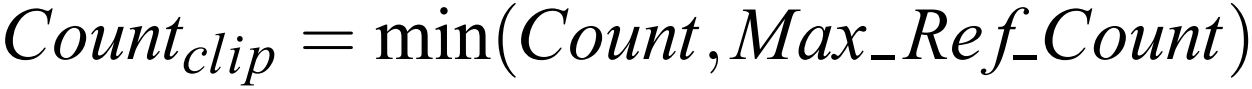
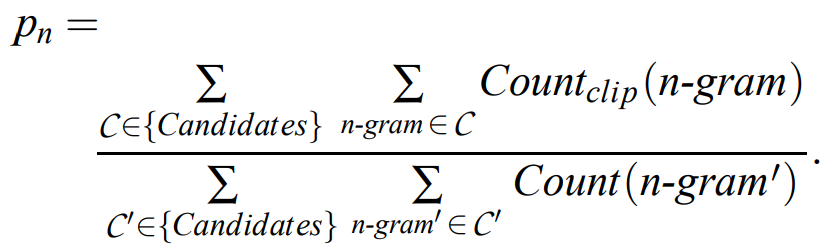


Source Code
import numpy as np
from collections import Counter
from nltk import ngrams
# n-gram count in tokens of sentence
def simple_count(tokens, n):
return Counter(ngrams(tokens, n))
# n-gram clipping count in tokens of sentence
def count_clip(candidate, reference_list, n):
ca_cnt = simple_count(candidate, n)
max_ref_cnt_dict = dict()
for ref in reference_list:
ref_cnt = simple_count(ref, n)
for n_gram in ref_cnt:
if n_gram in max_ref_cnt_dict:
max_ref_cnt_dict[n_gram] = max(ref_cnt[n_gram], max_ref_cnt_dict[n_gram])
else:
max_ref_cnt_dict[n_gram] = ref_cnt[n_gram]
return {
n_gram: min(ca_cnt.get(n_gram, 0), max_ref_cnt_dict.get(n_gram, 0)) for n_gram in ca_cnt
}
# modified unigram precision
def modified_precision(candidate, reference_list, n):
clip_cnt = count_clip(candidate, reference_list, n)
total_clip_cnt = sum(clip_cnt.values())
cnt = simple_count(candidate, n)
total_cnt = sum(cnt.values())
if total_cnt == 0:
total_cnt = 1
return (total_clip_cnt / total_cnt)
# return the closest reference length with cadidate
def closest_ref_length(candidate, reference_list):
ca_len = len(candidate)
ref_lens = (len(ref) for ref in reference_list)
closest_ref_len = min(ref_lens, key=lambda ref_len: (abs(ref_len - ca_len), ref_len))
return closest_ref_len
# brevity_penalty
def brevity_penalty(candidate, reference_list):
ca_len = len(candidate)
ref_len = closest_ref_length(candidate, reference_list)
if ca_len > ref_len:
return 1
elif ca_len == 0 :
return 0
else:
return np.exp(1 - ref_len/ca_len)
# bleu score
def bleu_score(candidate, reference_list, weights=[0.25, 0.25, 0.25, 0.25]):
bp = brevity_penalty(candidate, reference_list)
p_n = [modified_precision(candidate, reference_list, n=n) for n, _ in enumerate(weights,start=1)]
score = np.sum([w_i * np.log(p_i) if p_i != 0 else 0 for w_i, p_i in zip(weights, p_n)])
return bp * np.exp(score)
candidate = '빛이 쐬는 노인은 완벽한 어두운곳에서 잠든 사람과 비교할 때 강박증이 심해질 기회가 훨씬 높았다'
references = [
'빛이 쐬는 사람은 완벽한 어둠에서 잠든 사람과 비교할 때 우울증이 심해질 가능성이 훨씬 높았다'
]
print('BLEU Score :', bleu_score(candidate.split(),list(map(lambda ref: ref.split(), references))))(result) BLEU Score: 0.25400289715190977import nltk.translate.bleu_score as bleu
candidate = '빛이 쐬는 노인은 완벽한 어두운곳에서 잠든 사람과 비교할 때 강박증이 심해질 기회가 훨씬 높았다'
references = [
'빛이 쐬는 사람은 완벽한 어둠에서 잠든 사람과 비교할 때 우울증이 심해질 가능성이 훨씬 높았다'
]
print('BLEU Score 0f NLTK :', bleu.sentence_bleu(list(map(lambda ref: ref.split(), references)),candidate.split()))(result) BLEU Score 0f NLTK : 0.25400289715190977References
- BLEU Score paper (Go to Site)
- BLEU Score (Wikidocs) (Go to Site)
- BLEU Score (Personal Blog, Donghwa-Kim) (Go to Site)







Generative AI