
**위의 사진은 하둡이 일반컴퓨터에서도 빠르게 작동하는 모습을 표현한 사진입니다. 출처
1. 가상머신(Virtual Machine) 설치
2. CentOS Linux 설치
**주의** 가상머신과 리눅스는 설치하기 쉽다. 하지만, 하둡은 셀 상에서 vi / vim을 명령어를 이용하여 파일을 편집해 주면서 설치하는 프로그램이다. 이때, 오타를 각별히 주의해야 한다!
어떻게 알았냐구요??? 저도 오타가 안났다면 몰랐어요^^...
사실
라는 위대하고 편리하고 한눈에 실행화면을 편하게 볼 수 있는 도구가 있지만, 잘못 사용하면 저작권법에 걸린다.. 이런 점을 주의해서 편리한 생활을 하자!

3. Hadoop 설치
이 두 사진이 Hadoop의 정상 설치 모습이다. 그동안 설치하느라 힘쓴거에 비해 아무것도 아니라는 듯 보인다.
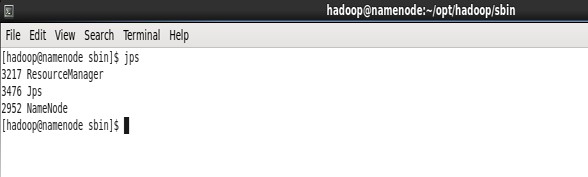
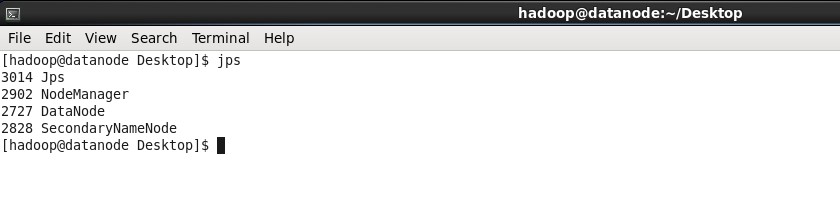
4. MapReduce 실험
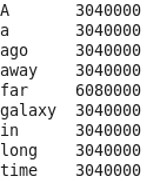
하둡 설치 후 화면이 조금 허무한듯 보였지만, 하둡에 MapReduce를 돌려보면 그 위력을 알 수 있다. 약 120MB 짜리 텍스트 데이터의 Word Count를 진행해 보았는데, 5분 밖에 안걸렸다.. GPU도 아닌 일반 컴퓨터인데 엄청 빠르게 처리되어서 살짝 놀랐다. 컵라면에 물이라도 받아둘 걸 그랬다.

Soli Deo Gloria. / Sapere Aude.