
API Caching
Redis를 사용하여 API의 응답을 캐시하는 기능을 개발했을 때의 일입니다. 이커머스 도메인의 검색 서비스였고, 여러 이유로 검색엔진의 상품 검색 쿼리가 그다지 가볍지 않아 프론트엔드의 입장에서는 꽤 부담이 있었습니다. 핵심적인 API지만 응답을 대기하느라 페이지 렌더링이 지연되는 경우가 빈번했고, 검색 키워드에 따라 상품 검색 결과(문서) 수가 많거나 하면 몇 초가 소요되기도 했습니다.
때문에 캐시가 히트하기만 하면 확실히 체감 가능한 수준으로 빨라졌고, API 호출량도 대폭 감소하니 백엔드 인프라(검색엔진 등)의 부담도 크게 저감될 수 있었습니다.
하지만 동시에 신경써야 할 문제도 하나 생겨났습니다. 데이터 정합성 이슈입니다. 상품은 수시로 생성/수집되어 검색엔진에 동적으로 인덱싱되고 있고, 비즈니스 특성상 최대한 리얼타임에 가깝게 상품 정보를 보여주는 것이 중요한 요구사항이었습니다.
또한 검색 품질 향상 및 이슈 대응 등을 목적으로 종종 운영자의 관리와 개입이 필요한 상황이 있기도 해서, 캐시가 만료되기 전까지는 과거의 상품 정보를 보여준다는 문제가 갈 수록 두드러졌습니다.
물론 적절한 TTL(expire)이 설정되어 있기는 했지만, 최소한의 관리가 이루어지기 위해서는 적어도 캐시를 조회/삭제/갱신하는 등의 기본적인 기능을 개발할 필요가 있었습니다. 그래서 기획자와 논의를 거쳐 간단한 관리 도구를 개발하기 시작했습니다.
KEYS 명령어의 위험성
가장 먼저 구현한 기능은 특정 검색 키워드의 캐시를 삭제하는 기능이었는데, key를 삭제하기 위해서는 먼저 조회를 해야 합니다.
이때 일반적으로 생각할 만한 명령어가 바로 KEYS 입니다. glob pattern으로 간단히 데이터베이스의 모든 key를 조회할 수 있고, 시간 복잡도가 O(N)이기는 하지만 공식 문서에 따르면 저사양 랩탑에서도 40ms 내에 100만 개의 key가 존재하는 데이터베이스를 스캔할 수 있다고 합니다.
그러나 이 명령에는 치명적인 문제점이 있는데, 해당 명령이 실행되는 도중에는 다른 모든 명령의 실행이 블로킹된다는 점입니다.
Redis는 싱글 스레드 아키텍처이기 때문으로, 데이터베이스의 규모가 클 수록 블로킹의 영향으로 성능이 저하되고 장애가 발생할 가능성이 매우 커질 수 있어, 일반적으로 프로덕션 환경에서는 절대 사용하지 말아야 한다고 알려져 있습니다.
SCAN 명령을 사용하자
그래서 대안으로 SCAN이라는 명령이 존재합니다. KEYS와 달리 다른 명령의 실행을 거의 차단하지 않아 프로덕션에서도 비교적 안전하게 사용할 수 있습니다.
이것이 가능한 원리는, 작은 단위로 증분 반복 순회하면서 데이터베이스를 스캔하는 것입니다. 한 번의 명령 호출 당 적은 수의 요소만 반환하기 때문에, 중간중간 다른 명령어를 처리할 수 있게 되는 식입니다.
공식 문서의 예제를 인용해 보겠습니다.
redis 127.0.0.1:6379> scan 0
1) "17"
2) 1) "key:12"
2) "key:8"
3) "key:4"
4) "key:14"
5) "key:16"
6) "key:17"
7) "key:15"
8) "key:10"
9) "key:3"
10) "key:7"
11) "key:1"
redis 127.0.0.1:6379> scan 17
1) "0"
2) 1) "key:5"
2) "key:18"
3) "key:0"
4) "key:2"
5) "key:19"
6) "key:13"
7) "key:6"
8) "key:9"
9) "key:11"필수 인수로 cursor라는 값을 0으로 주고 명령을 호출하자 조회된 key들과 함께 17이라는 값이 반환되었는데, 이것은 다음 순회의 시작점이 될 업데이트된 cursor를 나타냅니다. cursor가 0이 반환되었다면 모든 collection을 순회했다는 의미이며, 이를 전체 순회(full iteration)라고 합니다.
cursor란 bucket을 찾아가기 위한 다음 index 값을 의미합니다. 특이한 점은 위 예제에서처럼 순차적, 규칙적으로 증감하는 값이 아니며 0에서 시작해 0으로 끝난다는 것입니다. 이는 내부적으로 index가 비트 연산되는 과정에서 비롯된 것으로, 수시로 확장/축소 조정될 수 있는 해시 테이블의 크기에 대한 reverse 값이어서 마치 무작위로 변동되는 것처럼 보이며, 시작과 끝이 0이 되는 형태를 취하게 됩니다.
이 내용에 대해서는 잘 설명된 글이 있어 공유합니다.
kakao Tech, 'Redis의 SCAN은 어떻게 동작하는가'
Redis는 기본적으로 key-value 형태로 데이터를 저장하는데, 여기에 bucket을 활용하여 Linked List 자료구조를 구현합니다. 이때 bucket이란 Linked List 형태의 key들이 매핑/할당된 일종의 구획/슬롯이라 할 수 있고, SCAN 명령은 이것을 기준으로 하나씩 순회해 나가는 식으로 동작합니다. 그래서 이러한 bucket을 가리키는 cursor가 기준점이 되는 것입니다.
SCAN 명령의 특징
이렇게 KEYS와는 다른 동작으로 인해 몇 가지 특징을 가지는데, 간단히 나열하면 아래와 같습니다.
-
얼마든지 중복된 key가 반환될 수 있습니다. 만약 반환된 key로 무언가 다른 명령을 실행하고자 한다면 고려해야 할 부분입니다. 공식 문서에서는 중복 제거를 애플리케이션의 몫이라 설명하고 있습니다.
-
전체 순회 과정에서 collection에 지속적으로 존재하지 않았던 key는 반환이 될 수도, 안 될 수도 있습니다.
SCAN명령에는 '상태'의 개념이 없기 때문입니다. -
count인수를 전달하여 매 순회마다 반환할 요소의 개수를 지정할 수 있지만, 이것이 항상 정확하다는 보장은 없습니다. 어디까지나 명령에 대한 일종의 '힌트'를 의미합니다. -
KEYS에 비해 안전하기는 하지만, 사용하기에 따라서 완벽한 non-blocking이 아닐 수 있습니다. 이는 아래 내용에서 이어집니다.
COUNT option
위에서 언급했듯, 이 옵션은 매 순회마다 반환할 요소의 개수를 의미합니다. 기본값은 10인데, 이 수치가 커질 수록 Redis가 collection에서 key를 스캔하기 위해 수행해야 하는 작업량도 커지게 됩니다.
다시 말해, count를 크게 줄 수록 key를 한 번에 더 많이 조회해낼 수 있으므로 전체 순회에 소요되는 시간이 짧아지겠지만, 그만큼 대상이 되는 테이블의 범위도 커져 블로킹 시간은 증가하게 될 수 있습니다. KEYS 명령을 사용할 때와 비슷한 문제가 재현되는 셈입니다.
이는 count 수치가 경험적, 실증적인 사례를 근거로 데이터베이스의 규모를 고려해 적절히 설정되어야 함을 의미합니다. 아래는 key가 500만 개 존재하는 데이터베이스에서 SCAN 명령에 소요된 시간을 측정한 벤치마크 결과를 인용한 것입니다.
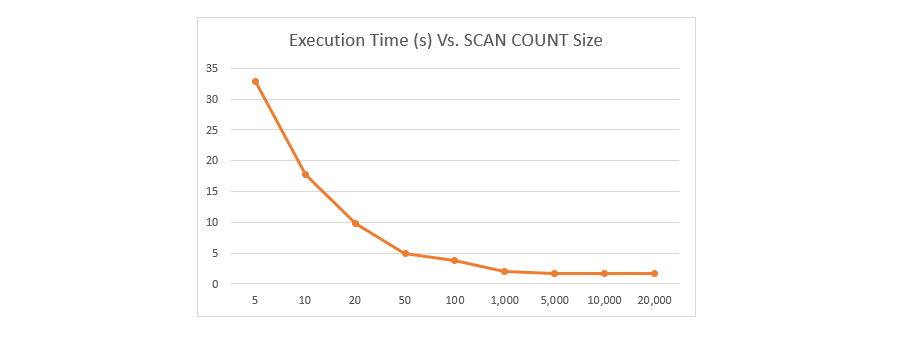
count가 커질 수록 소요 시간이 감소하지만 선형적이지는 않고, 그 폭이 일정 수치(위 그래프에서는 50)부터는 급감한다는 사실을 알 수 있습니다. 명령 실행에 너무 많은 시간이 소요되지 않으면서, 블로킹 문제를 유발하지 않을 정도로 적절히 스캔할 수 있는 '스윗 스팟(Sweet Spot)'을 찾는 것이 관건이라고 할 수 있습니다.
실제로 직접 운영 중인 서비스에서 검증해 보았을 때에도 비슷한 결과를 확인할 수 있었습니다. 약 80만 개의 key가 존재하는 상황에서 count를 10으로 주고 조회하면 전체 순회에 4~5초 가량 소요되었던 반면, 100을 주고 조회했을 때에는 1초 미만이 소요되었으며 그 이상으로는 의미 있는 수준의 개선 효과가 측정되지 않았습니다.
MATCH option
KEYS 명령어와 마찬가지로, SCAN 역시 glob pattern으로 key를 조회할 수 있습니다. 다만 key를 스캔한 후 클라이언트에 데이터를 반환하기 직전에 패턴이 적용된다는 점이 특기할 만한 점입니다. 때문에 아래와 같이 count 수치가 작으면 반환되는 요소가 적거나 없을 가능성도 커지게 됩니다.
redis 127.0.0.1:6379> scan 0 MATCH *11*
1) "288"
2) 1) "key:911"
redis 127.0.0.1:6379> scan 288 MATCH *11*
1) "224"
2) (empty list or set)
redis 127.0.0.1:6379> scan 224 MATCH *11*
1) "80"
2) (empty list or set)
redis 127.0.0.1:6379> scan 80 MATCH *11*
1) "176"
2) (empty list or set)
redis 127.0.0.1:6379> scan 176 MATCH *11* COUNT 1000
1) "0"
2) 1) "key:611"
2) "key:711"
3) "key:118"
4) "key:117"
5) "key:311"
6) "key:112"
7) "key:111"
8) "key:110"
9) "key:113"
10) "key:211"
11) "key:411"
12) "key:115"
13) "key:116"
14) "key:114"
15) "key:119"
16) "key:811"
17) "key:511"
18) "key:11"번외 : DEL vs UNLINK
key를 삭제하려는 경우에도 블로킹 이슈에서 비교적 자유로운 솔루션이 존재합니다. Redis 4.0.0 부터 지원하는 UNLINK 명령이 그것으로, 별도의 스레드에서 백그라운드로 삭제를 수행합니다.
명령 자체는 동기식으로 실행되는데, 일단은 key만 제거하여 단어 그대로 데이터의 연결을 해제(unlink)만 하고 추후 실질적인 삭제 작업과 메모리 회수는 비동기적으로 처리하는 식입니다.
KEYS 및 SCAN 때와 비슷하게, 삭제하려는 데이터가 너무 많으면 다른 명령의 실행이 오랜 시간 블로킹될 위험이 있어 구현된 명령이라고 할 수 있습니다. DEL 명령은 시간 복잡도가 O(N)(N은 제거할 key의 개수)인 반면, UNLINK는 규모와 관계없이 O(1)이고 다른 스레드에서 실제 삭제 작업을 수행할 때 O(N)입니다.
다만 특이한 점이 있는데, 삭제할 대상의 사이즈가 작은 때(64개 이하)에는 DEL 명령으로 동작한다는 점입니다. 이는 UNLINK가 DEL에 비해 스레드 동기화 등의 작업으로 인해 추가적인 비용이 발생하므로, 오히려 비효율적일 수 있기 때문입니다.
대신 삭제할 key의 개수가 100k, 1000k 이상 단위로 큰 경우에는 극적인 효과를 볼 수 있습니다. 타 벤치마크 결과를 인용해보자면 아래와 같습니다.
10만 개의 멤버가 저장된 Set 타입의 key를 삭제할 때의 소요 시간
DEL : 44,217ms
UNLINK : 25ms
마치며
새삼스럽지만, 이미 잘 만들어진 도구가 있다 한들 무작정 가져다 쓸 것이 아니라 탐구와 이해를 거쳐 사용하는 것이 중요하다는 사실을 체감하게 됩니다. 많은 경우, 출중한 공식 문서와 타인의 경험을 통해 정제된 지식을 어렵지 않게 얻을 수 있다는 점은 개발자가 누릴 수 있는 행운이 아닐까 합니다.



깔끔하네요