데이터베이스 시스템
데이터 베이스는 왜 필요할까?
<교통 앱>
단순해 보이는 서비스지만, 방대한 양의 데이터가 계산되어서 사용자에게 정보를 제공한다.
길이 막히는지, 버스 도착 시간과 배차 간격은 어떠한지를 모두 계산하여 최선의 결과를 찾아 앱 사용자에게 제시하기 때문이다.
데이터의 단위

사진상에 보이는 iPad 제품의 경우 128GB의 데이터를 보관할 수 있는데, 이 아이패드를 쌓아 올려 44 제타바이트를 저장하려면, 지구에서 달까지 3번을 왕복할 수 있는 양이다.
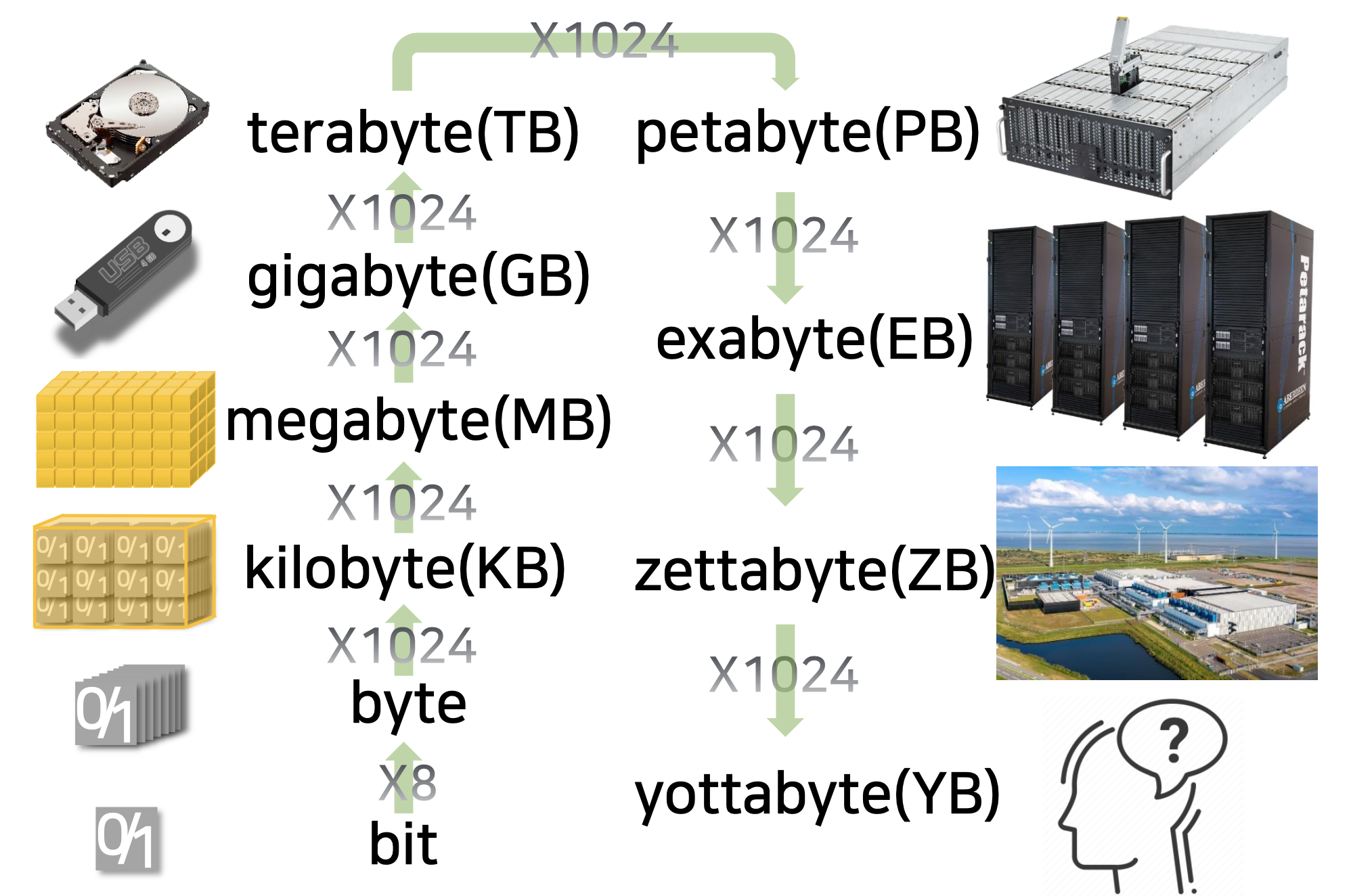
bit는 정보까지는 아니나, 데이터를 나타내는 가장 작은 단위이다.
비트가 8개가 모이면 <정보> 를 저장하는 가장 작은 형태인 byte가 되고
이러한 byte가 1024개가 모이면 킬로바이트가 되며, 1024 배율로 데이터의 단위가 바뀌게 된다.
구글의 메일 Gmail의 하루 이동 데이터 용량은 6 페타바이트이다.
아직까진 지구에서 1 요타 바이트를 저장할 수 있는 방법은 없다.
이렇게 많고 큰 데이터를 어디에 사용할까?

여러 스마트 디바이스, Legacy media, IoT sensor로 부터 만들어지는 데이터를 빅 데이터라고 칭하며,
이 빅 데이터를 통하여 새로운 정보 또는 데이터를 뽑아내어 만든 것을 AI(Artifical intelligence)라고 한다.
인공지능이 가능해진 이유 역시 많은 데이터가 쌓였기 때문이다.
데이터 관리의 역사
1960년도 초, 파일 처리 시스템
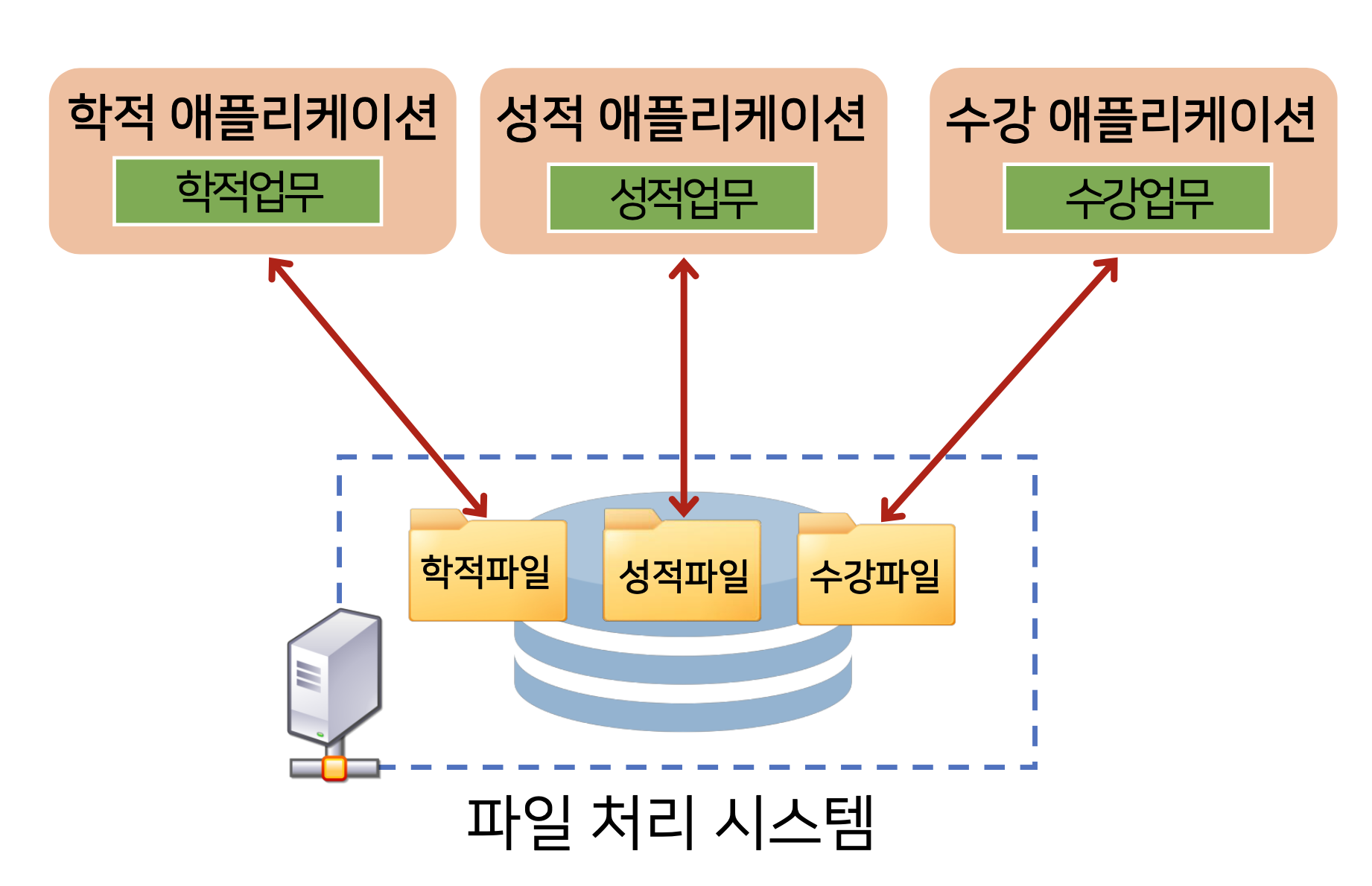
DB가 개발되기 전에 데이터 관리에 사용했던 방식으로, 업무 별 애플리케이션이 개별 데이터를 데이터 파일에 저장, 관리하는 시스템이었다.
각각의 애플리케이션이 개별적으로 파일을 만들어서 사용했는데, 이에 따라 발생한 문제는 크게 4가지로
- 데이터 종속의 문제
- 데이터 중복의 문제
- 무결성 훼손의 문제
- 동시 접근의 문제
등이 있었다.
데이터 종속의 문제
1. 저장된 데이터가 특정 하드웨어 및 사용자 / 소프트웨어에만 사용될 수 있도록 제한하는 문제
ex) 학적 업무를 수행하다가, 학생들과 데이터가 너무 많아져서 다른 디스크를 추가하고 학적 업무 디스크를 추가해야 하는 경우
여러가지 하드웨어가 추가되고, 정보가 추가될 때마다 유지보수 및 수정이 되어야 하는데, 이러한 문제를 곧바로 고칠 수 없었다.
ex2) 학적에 기록된 데이터의 논리적 구조를 조금이라도 바꾼다면? (성별 추가, 주소 추가 등)
수정, 개발 후 이를 다시 업무 환경에 배포하기까지의 시간이 너무 오래 걸렸고, 따라서 업무 현장에서 사용하기엔 너무 힘들었다.
데이터 중복의 문제
1. 동일한 사항에 대한 중복된 데이터는 일관성, 보안성, 경제성 측면에서 문제 발생
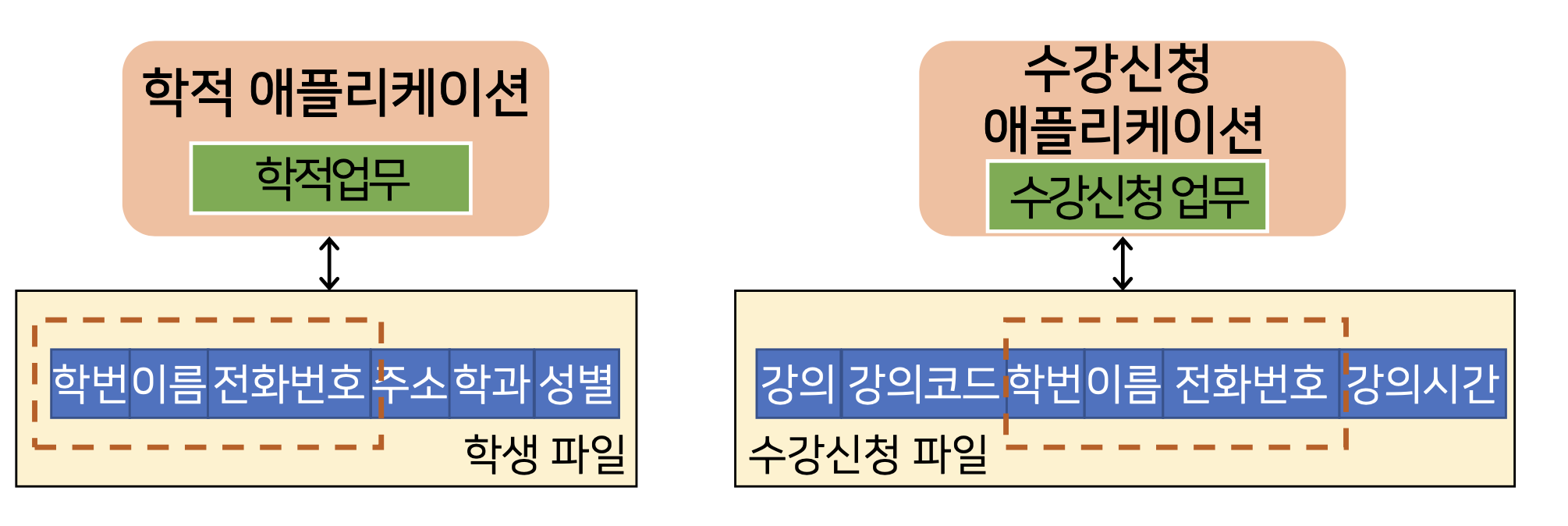
ex) 학적 업무에 학번이 잘못되어 수정을 해야 하는데, 과연 학적 어플리케이션의 데이터만 수정하면 될까?
당연히 안 된다, 한 학생의 학번이 XX라는 한 가지 사실에 대하여 2가지 값을 갖고 있게 된다.
이를 데이터의 일관성이 훼손되었다고 표현하며, <데이터의 정확성이 떨어진다.> 로 표현할 수 있으며, 쓸모 없는 데이터로 귀결된다.
일관성 : 한 사실에 대해 한 개의 데이터 값을 유지
보안성 : 같은 데이터에 같은 수준의 보안 유지
경제성 : 데이터에 대해 최소한의 저장 공간만을 점유
무결성 훼손의 문제
1. 실세계의 데이터는 데이터가 가질 수 있는 가능 범위 (제약조건)을 포함
현상에 대한 값의 예 : '홍길동'의 수강 과목
가능 범위의 예 : 1학기 최대 수강학점 18학점
- 데이터의 무결성
데이터의 정확성 보장
데이터의 값과 값에 대한 제약조건을 동시에 만족
- 파일 시스템은 데이터 무결성을 보장하기 위한 기능을 제공하지 않음
동시 접근의 문제
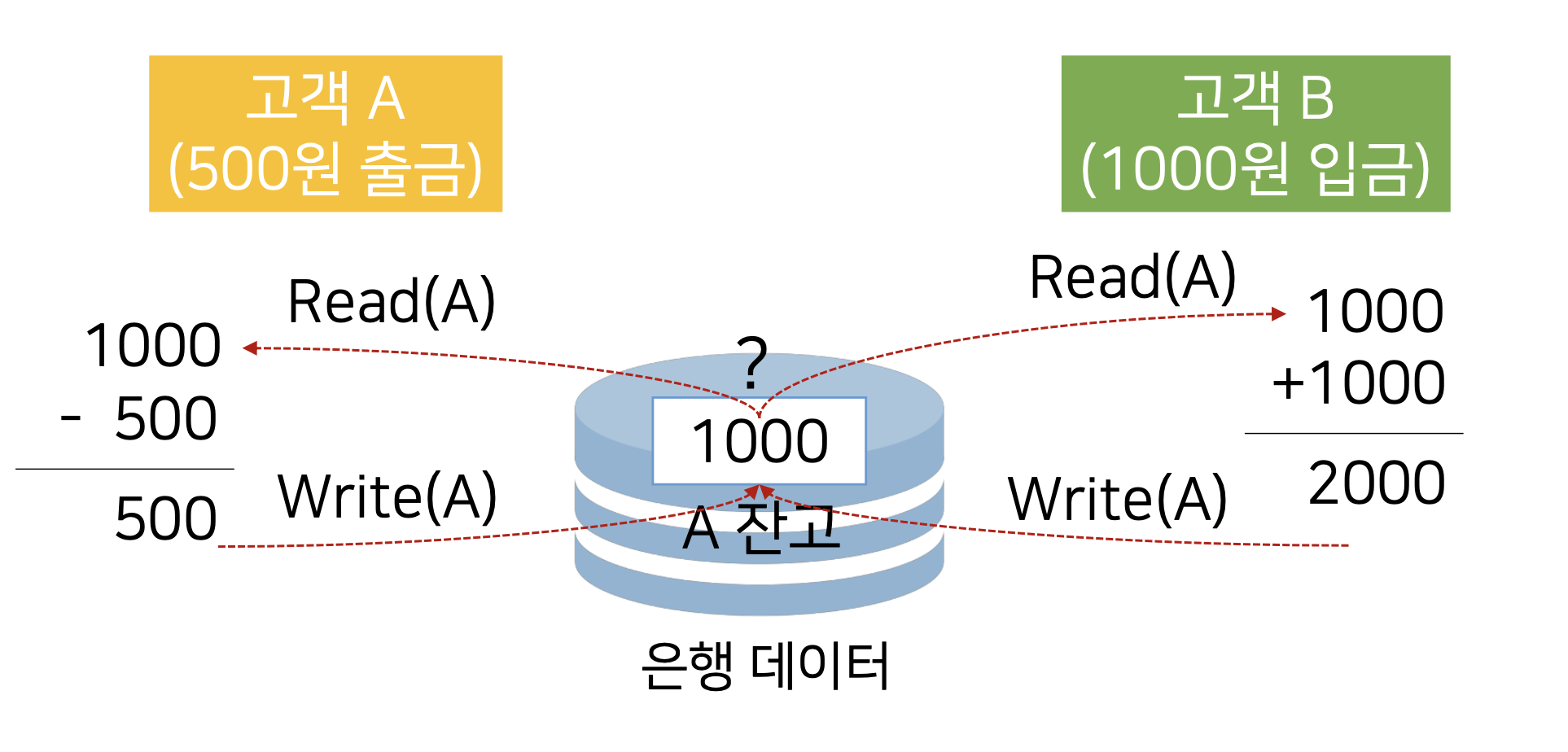
A라는 고객에게 1,000원의 잔고가 있다고 가정한다.
고객 A가 본인의 돈 500원을 출금하고자 하고, 은행의 중앙 서버는 A 고객의 잔고 데이터를 Read한다.
그러던 중, A에게 돈을 빌려갔던 B가 1,000원을 또 다른 ATM기계에서 입금을 하고자 하면, 다시 한 번 은행의 중앙 서버는 A의 잔고를 읽어야 할 것이다.
하나의 데이터에 대해서, 여러 사용자가 동시에 그 데이터에 접근하면 데이터의 무결성을 해친다.
파일 처리 시스템은 동일 데이터에 다수 사용자의 접근을 허용함으로서, 일관성이 훼손되는 문제를 낳을 수 있다.
데이터 베이스 사용의 의미
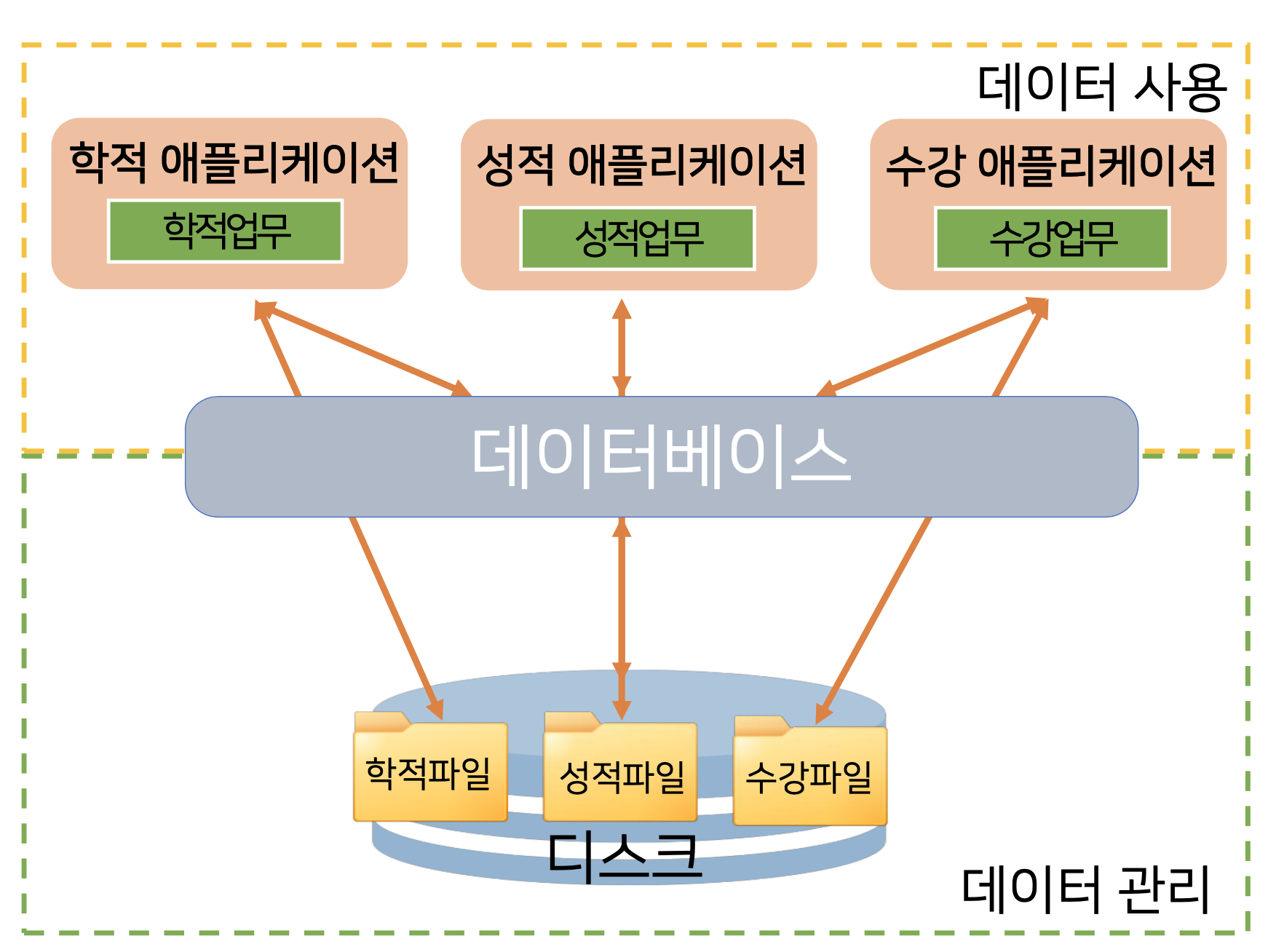
파일 처리 시스템과 달리, 학적 어플리케이션, 성적 애플리케이션, 수강 애플리케이션 (데이터 사용자)이
직접적으로 데이터를 저장, 관리하는 곳으로 직접 접근하지 않고 모든 것을 데이터베이스에 일임하여, 데이터에 접근할 수 있는 것은 데이터베이스만 가능하도록 만든 것이 데이터베이스의 사용의 의미이다.
데이터 사용과 관리를 분리하여, 곧바로 사용할 수 없도록 만든다.
데이터베이스의 특징
- 데이터베이스 시스템의 자기 기술성
- 데이터의 데이터의 정의 및 설명(메타 데이터)를 포함
- 프로그램과 데이터의 격리 및 추상화
- 사용자에게 데이터에 대한 개념적인 표현을 제공하여 접근성을 향상
- 다중 뷰 제공
- 각 사용자가 관심을 갖는 데이터베이스의 일부만을 표현할 수 있는 기능
- 데이터 공유와 다수 사용자 트랜잭션 처리
- 다수의 데이터 조작 요청을 동시성 제어 기능을 통해 데이터의 일관성을 보장하면서 동시에 작업을 수행
데이터베이스 시스템의 구성
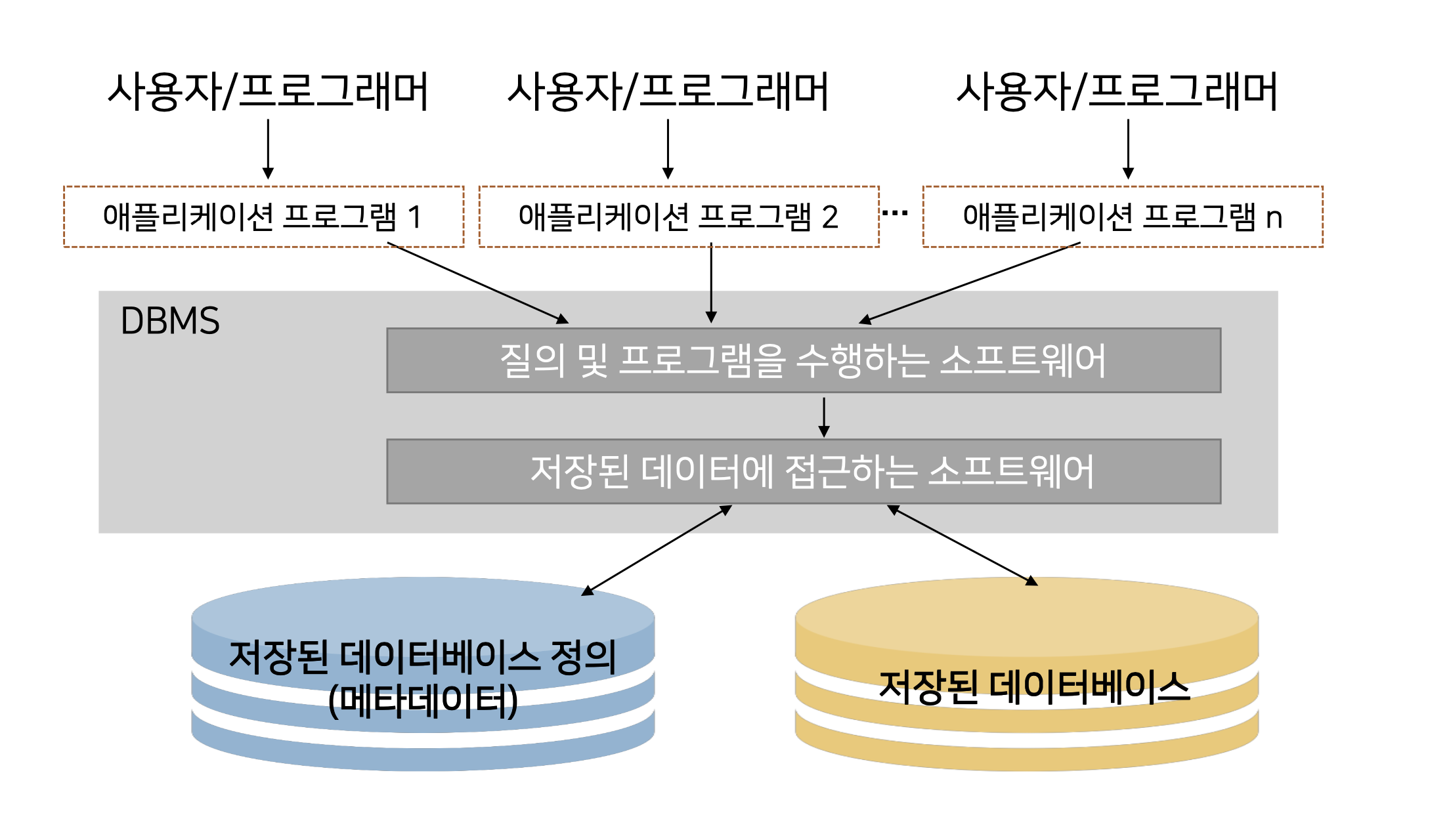
애플리케이션을 통해 DBMS에 접근, DBMS는 소프트웨어 모듈에 접근, 사용자가 요구하는 데이터를 DBMS가 가져온다.
메타 데이터?
예를 들어, 12라는 숫자가 있다고 가정한다.
12라는 데이터는 무엇일까? 12시? 온도 12도? 12분? 12월? 너무나도 다양하게 해석되기 때문에, 이를 데이터라고 하지 않는다. 이는 Value이다.
이 때, 이 12라는 Value에 <오늘><최고기온> 이라는 태그가 붙으면 어떨까?
이처럼, 하나의 Value에 2개 이상의 설명 태그가 붙으면 이것을 데이터라고 한다.
이 때, 값에 의미를 부여하는 2가지의 부연설명을 <메타 데이터> 라고 한다.
그렇다면, 해당 그림에서 메타 데이터는 무엇을 이야기 하는 걸까?
데이터가 무엇을 의미하는지, 그 의미를 알아야 사용자가 요청하는 데이터를 꺼내어 줄 수 있기 때문에, 데이터와 데이터의 의미를 모두 상세하게 저장해야 한다.
- 즉, 자기기술성이란 데이터와 데이터의 의미를 같이 저장한다는 뜻이다.
⭐️ DBMS의 3중 구조
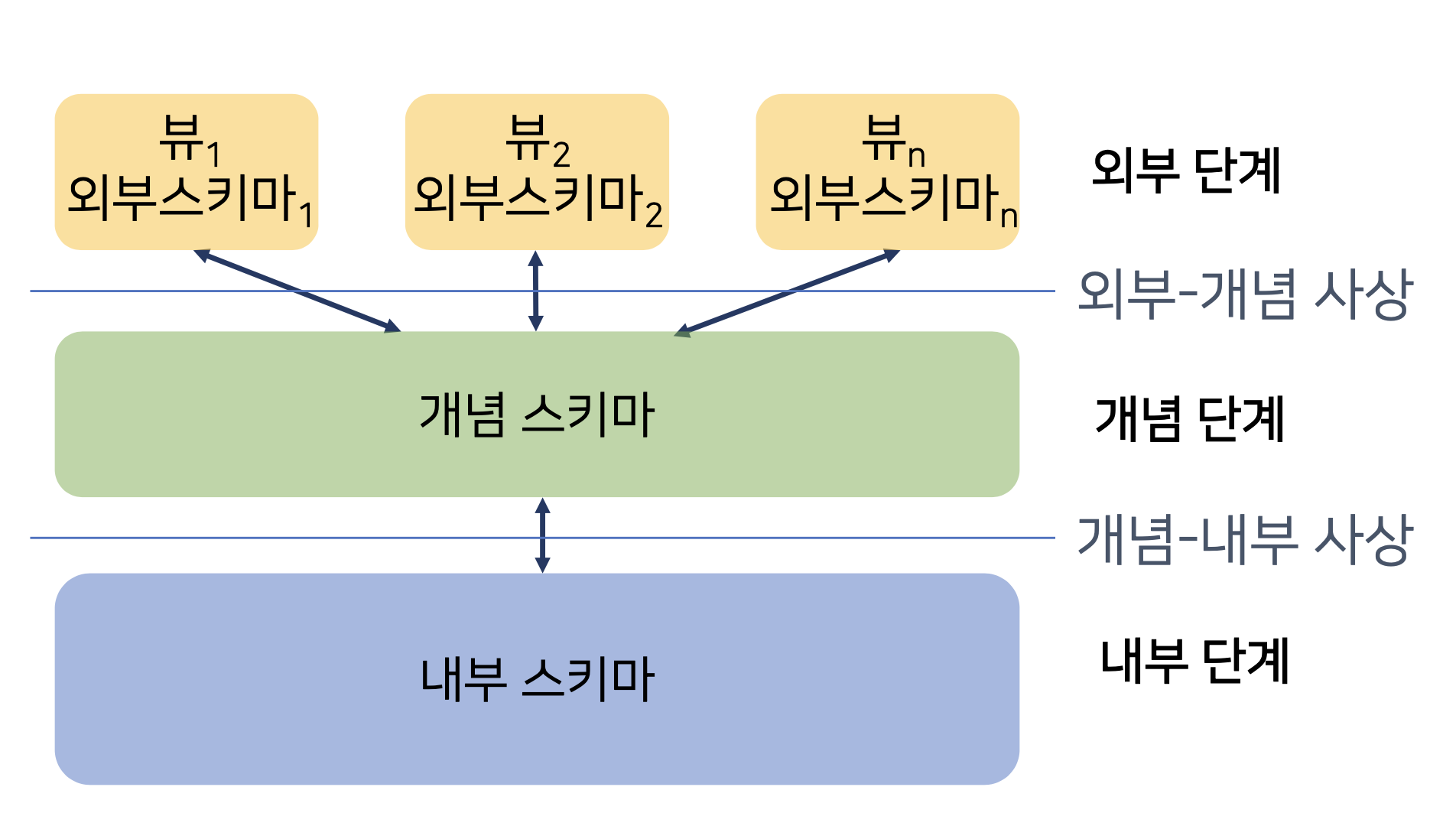
내부 단계
물리적인 표현으로, 어떤 파일이 어떤 디스크 어떤 파일 안에 몇 Kb로 저장되어있다. 를 뜻함
개념 단계
메타 데이터를 활용하는 것과 같이, 어떠한 의미로 저장된 것이다. 데이터의 의미 / 구조 / 규모 등을 뜻한다.
외부 데이터
실제 사용자가 업무 처리를 위해 요구한 데이터를 보여주는 창, 실제 사용자는 뷰를 통해서만 데이터를 볼 수 있다.
- 즉, 실 사용자는 개념 단계와 내부 단계를 볼 수 없다.
우리가 ATM기기에서 돈을 인출할 때에도, 우리의 데이터가 은행 중앙 몇 번 디스크에 저장되어 있는지 알 수 없지 않은가?
⭐️ DBMS의 3중 구조 예시
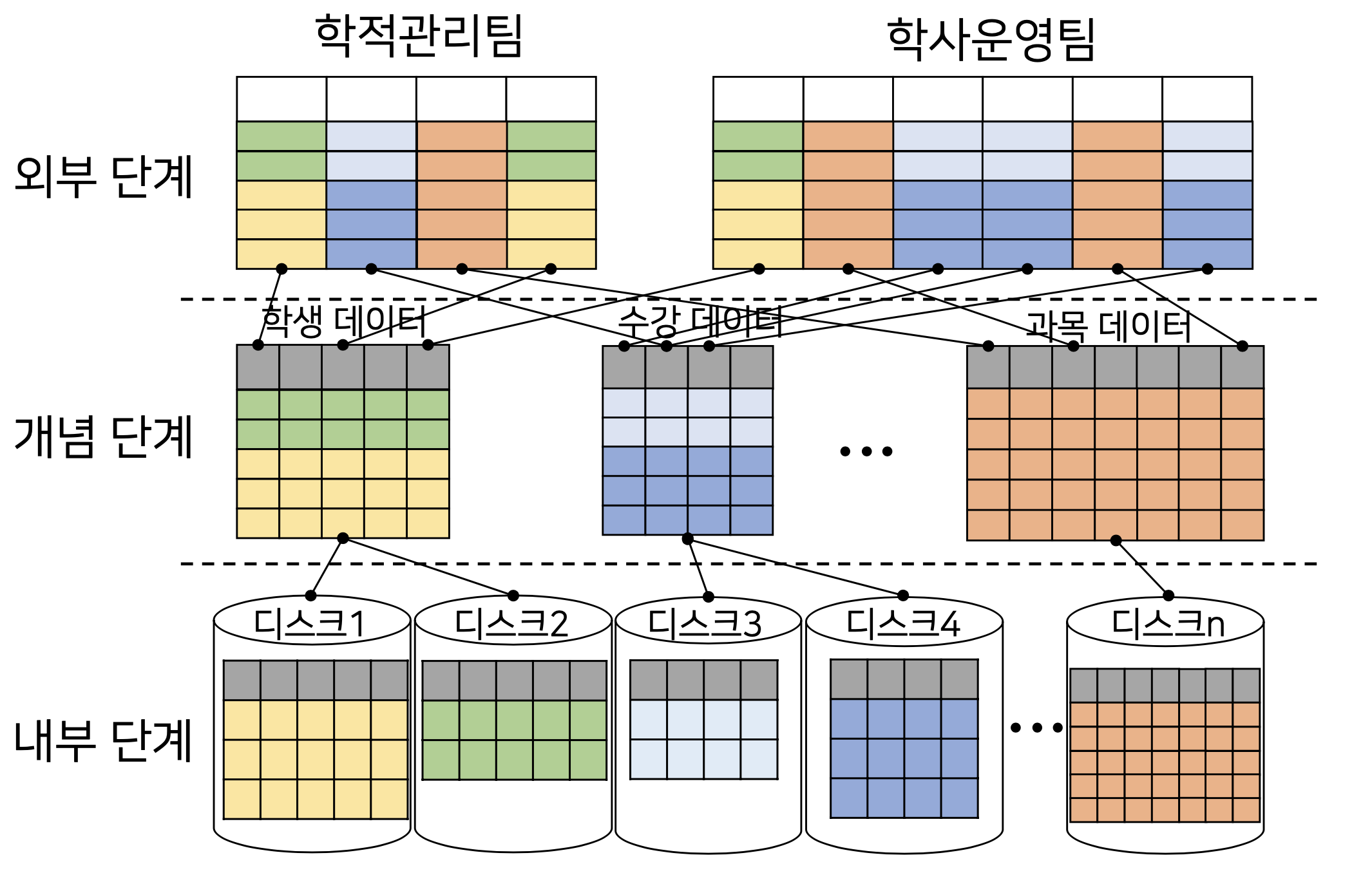
학생 데이터가 10만명일 때, 학생 데이터를 모두 한 디스크에 저장할 수 없다.
따라서, 디스크를 2개로 나누어 데이터를 저장한다고 했을 때, 개발자는 굳이 학생 데이터가 몇 번 디스크에 저장되어있는지 알 필요 없다.
내부 단계는, 개념 단계에 있는 데이터를 어떻게 물리적으로 보관하는가? 에 대해 다룬다.
개념 단계에 나와있는 학생 데이터, 수강 데이터, 과목 데이터를 토대로 실제 업무를 처리하는 사람에게 필요한 데이터를 매핑시켜 보여줄 수 있게 한다.
개념 단계 : 어떤 의미의, 어떤 구조의 데이터가 있는지만을 표시해준다.
내부 단계 : 어떤 데이터가 어떤 장치에 저장되는지 표시한다.
외부 단계 : 실제 데이터를 사용할 수 있게끔 알려준다.
다수 사용자의 트랜잭션 처리
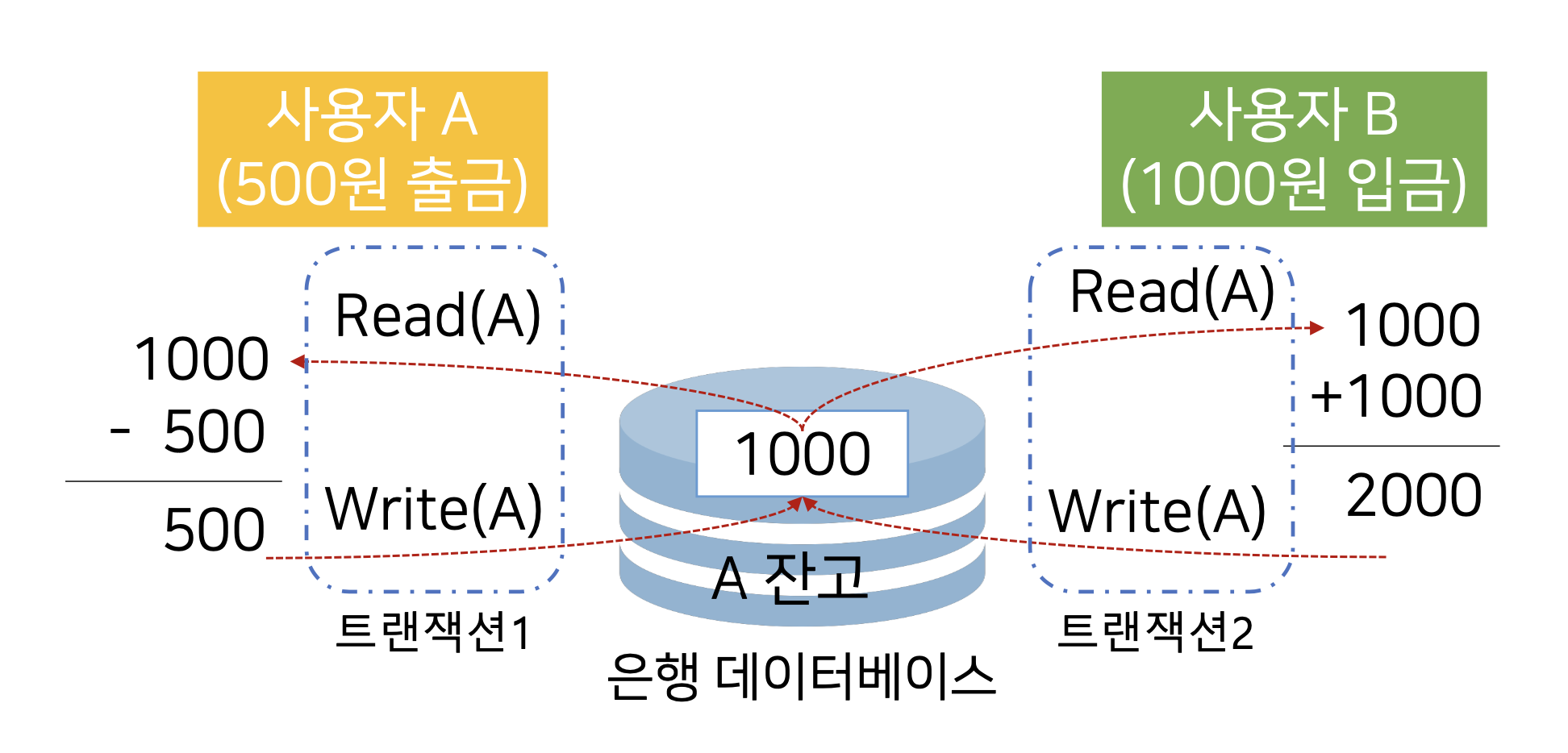
하나의 논리적 작업을 처리하기 위한 일련의 데이터베이스 명령의 집합
사용자 A의 500원 출금을 처리하는 과정에서, 사용자 B가 A에게 1,000원을 입금할 때 생기는 문제를 위에서 다뤘다.
이 때, 사용자 A가 500원을 출금하는 과정을 하나로 묶은 후 그 작업이 완전히 수행될 때까지 데이터에 접근을 막으면, 이 트랜잭션 내부의 모든 작업 (잔고 보기, 500원 뺴내기)이 끝나기 전까지 B가 데이터에 접근할 수 없어, 묶음 단위로 데이터를 처리할 수 있게 된다.
⭐️ 데이터 베이스 관련 용어
-
데이터 : 어떠한 사실에 대한 정량적, 정성적 특징을 나타낼 수 있는 값과 값에 대한 설명
-
데이터베이스(Database) : 특정 기관의 애플리케이션 시스템에서 사용되는 데이터의 집합
-
데이터베이스 관리 시스템(DBMS) : 데이터베이스에 저장된 데이터의 구성, 저장, 관리, 사용을 위한 소프트웨어 패키지
데이터베이스와 데이터베이스 관리 시스템은 일반적으로 통용하여 사용하나, 우리는 구분해서 사용하여야 한다.
- 데이터베이스 시스템 (Database system) : 정보를 데이터베이스에 저장, 관리하여 사용자에게 요구된 형태의 정보로 제공하는 컴퓨터 기반 시스템
! 혼용하지 않고 정확히 사용할 것.
데이터베이스의 구성 요소
데이터베이스 언어
-
DBMS는 사용자가 데이터베이스를 쉽게 사용하고 다룰 수 있도록 언어 형태의 인터페이스를 제공
-
역할에 따라 종류의 언어로 구분
-
데이터 정의 언어(DDL)
데이터베이스 객체를 생성, 수정, 삭제하기 위한 언어.
-
데이터 조작 언어(DML)
구조화된 데이터에 사용자가 접근 및 조작할 수 있도록 지원하는 언어(검색, 삽입, 삭제, 수정)
DML의 요구 조건 3가지
- 데이터 조작이 쉽고 간편할 것
- 데이터 조작 기능이 정확하고 완전할 것
- 사용자의 요청을 시스템 내부에서 효율적으로 처리 가능할 것
- 현대 데이터베이스 언어는 자연어와 유사한 형태의 SQL로 표준화
데이터베이스 시스템 아키텍처
- 중앙집중식 방식
- 단일 서버가 다수의 클라이언트 장치를 대신하여 작동
- 중앙 컴퓨터의 과부하로 전체적인 성능 저하
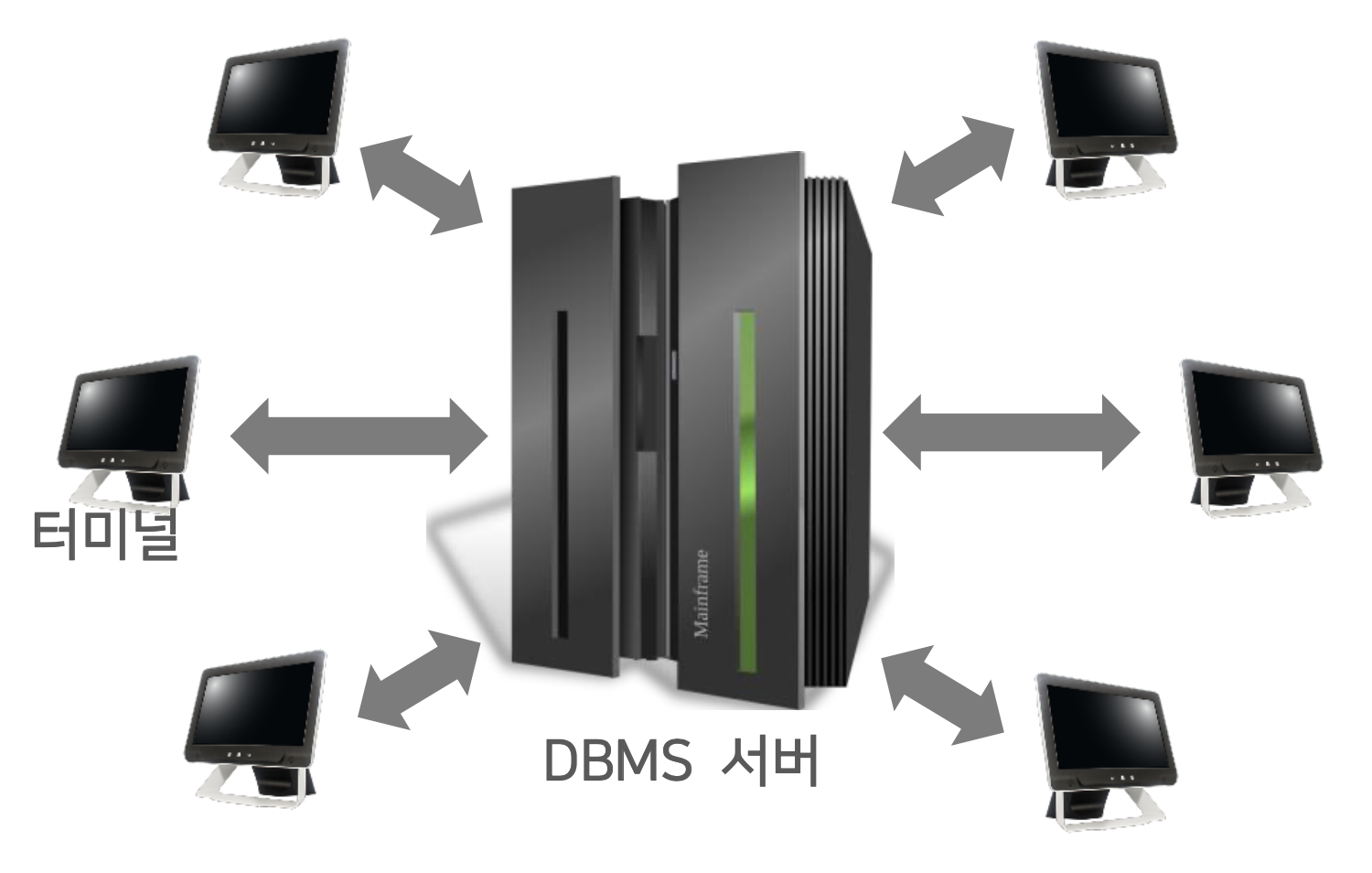
모든 업무를 DBMS서버에서 진행했고, 다른 클라이언트는 터미널이라는 입력 출력만 가능한 컴퓨터를 사용했다.
구축을 하기는 쉬웠으나, 중앙에서 모든 업무를 수행하므로 성능이 나빴다. 과거 은행에서 사용하던 방식.
- 분산 시스템 방식
- 클라이언트 장치의 성능 향상으로(터미널만 되는 것이 아닌)자체적인 처리 능력을 보유
- 클라이언트-서버 데이터베이스 시스템
애플리케이션 프로그램의 부하를 분산하고, 소프트웨어 유지보수의 비용을 절감 및 이식성 증가
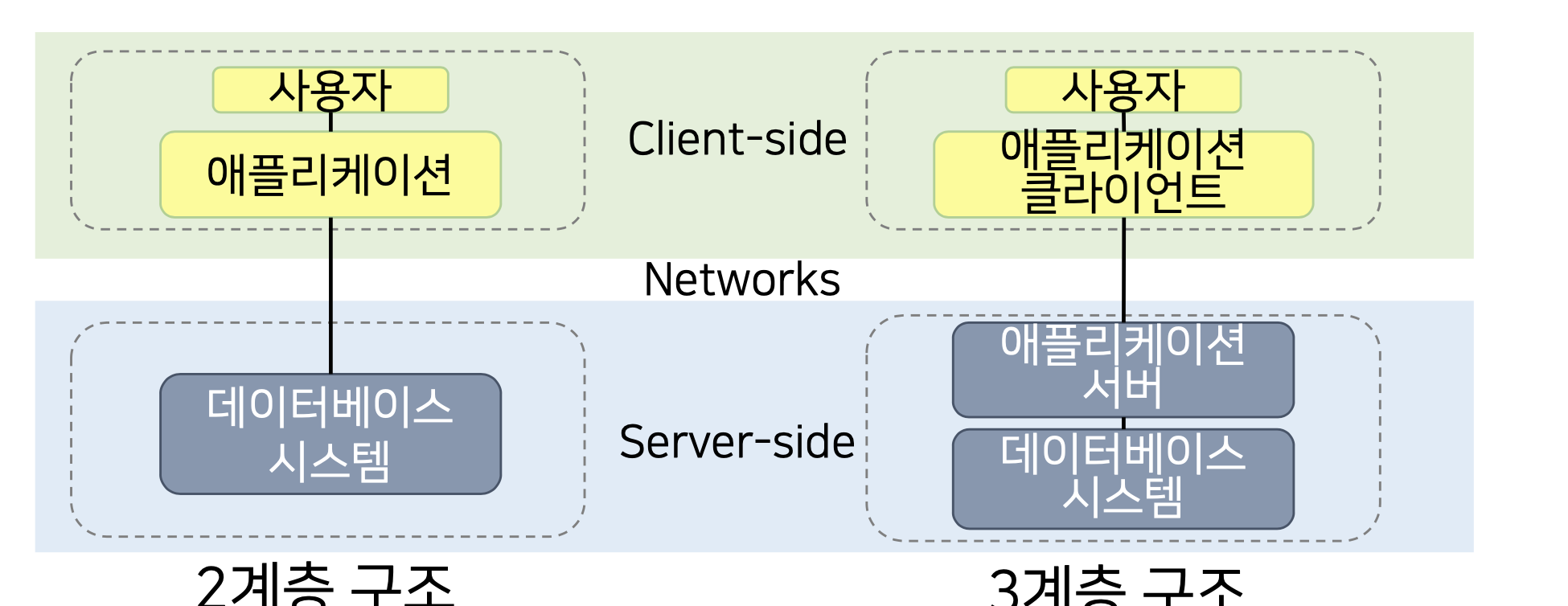
이러한 3계층 구조에는 개발하는데에 많은 비용과 시간이 소모되지만, 업무처리 프로세스가 변경되었을 떄, 모든 어플리케이션을 수정할 필요 없이
애플리케이션 서버에서 알고리즘만 살짝 바꿔주어도, 업무처리를 유지할 수 있는 구조로 각광 받고 있다.
항상 2계층 구조가 좋다, 항상 3계층 구조가 좋다, 항상 중앙 집중 구조가 좋다 라고 할 수 없다.
심지어, DBMS를 사용하지 않고 1960년대에 사용했던 파일 처리 시스템을 사용하는 것이 좋을 수도 있다.
