
데이터베이스 인덱스는 왜 B-Tree 자료 구조를 선택하였는가?
🧐 서론
앞에서 공부했듯이 인덱스는 데이터 저장, 수정, 삭제에 대한 성능을 희생시켜 탐색에 대한 성능을 대폭 상승하는 방식이라 볼 수 있다.
그런데, 인덱스는 많은 자료 구조 중에서 왜 'B-Tree' 를 사용할까?
우선 Tree 자료 구조에 대해서 짧게 이야기하자면,

일반적으로 Tree는 평균적으로 탐색에 대한 시간 복잡도로 O(logN)을 가진다. 하지만, 이는 평균적인 시간 복잡도로 아래 Tree와 같은 최악의 경우에는 시간복잡도가 O(N)이 된다.
.png)
이러한 경우를 방지하기 위해 밸런스 트리(Balanced Tree)를 이용한다.
🔎 밸런스 트리(Balanced Tree)란?
트리의 노드가 한 방향으로 쏠리지 않도록,
노드 삽입 및 삭제 시 특정 규칙에 맞게 재정렬되어 왼쪽과
오른쪽 자식 양쪽 수의 밸런스를 유지하는 트리이다.
항상 양쪽 자식의 밸런스를 유지하므로,
무조건 O(logN)의 시간 복잡도를 가지게 된다.
하지만, 노드 삽입 및 삭제 시 발생하는 재정렬 작업 때문에
탐색을 제외한 작업에서는 일반 Tree보다 성능이 좋지 않다.✍ 인덱스의 자료 구조
⭐ 해시 테이블을 사용 못하는 이유?
사실 탐색 시간이 빠른 것으로 인덱스 자료 구조를 선택한다면, 시간복잡도가 O(logN)인 다른 자료 구조를 사용하거나 시간복잡도가 O(1)인 해시 테이블을 사용하는 것이 더 빠를 수 있다.
[ 해시 테이블(Hash Table) ]
해시 테이블은 (Key, Value)로 데이터를 저장하는 자료구조 중 하나로 빠른 데이터 검색이 필요할 때 유용하다. 해시 테이블은 Key값을 이용해 고유한 index를 생성하여 그 index에 저장된 값을 꺼내오는 구조다.
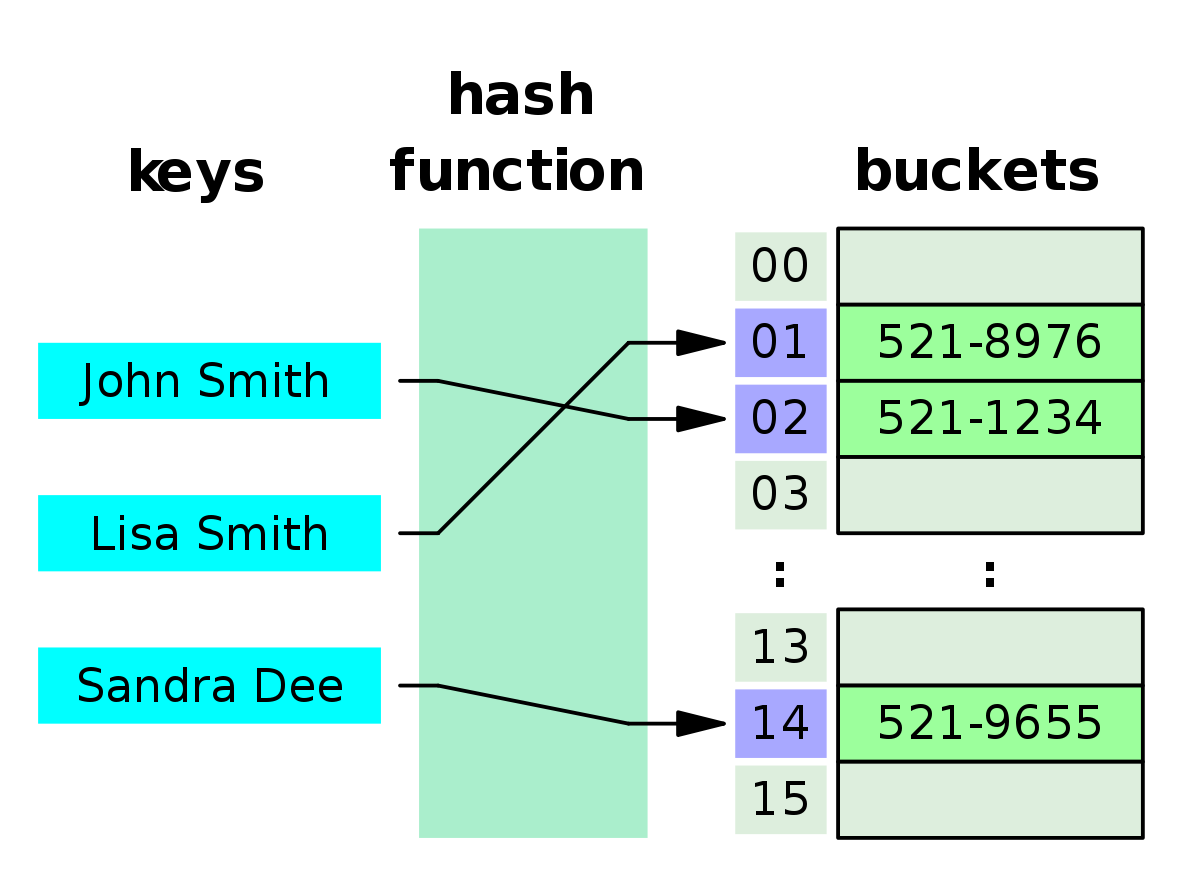
하지만 DB 인덱스에서 해시 테이블이 사용되는 경우는 제한적인데, 그러한 이유는 해시가 등호(=) 연산에만 특화되었기 때문이다. 해시 함수는 값이 1이라도 달라지면 완전히 다른 해시 값을 생성하는데, 이러한 특성에 의해 부등호 연산(>, <)이 자주 사용되는 데이터베이스 검색을 위해서는 해시 테이블이 적합하지 않다.
⭐ B-Tree가 선택된 이유?

-
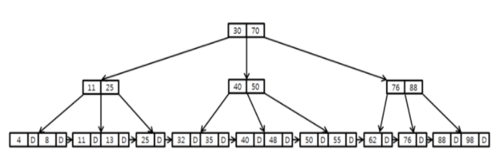
B-Tree는 위처럼 노드 하나에 여러 데이터가 저장될 수 있다.
-
각 노드 내 데이터들은 항상 정렬된 상태이며, 데이터와 데이터 사이의 범위를 이용하여 자식 노드를 가진다.
그러므로 자식 노드 개수는 (n+1)을 가진다. -
각 노드에는 여러 개의 Key를 가지고 있고 각 Key에 대응하는 Data도 함께 갖고 있다.
빨간색으로 상자 친 부분을 보면 마치 배열처럼 정렬이 되어있다.
맞다. 배열이다. 실제 메모리 상에 차례대로 저장이 되어있는 것이다.
- 같은 노드 공간의 데이터들끼리 굳이 자식 노드처럼 참조 포인터 값으로 접근할 필요가 없다.
이는 즉, 같은 노드 상에서 데이터를 탐색할 때는 포인터 접근을 하는 것이 아니라 실제 메모리 디스크에서 바로 다음 인덱스의 접근을 하는 것이다.
결론적으로 DB 인덱스로 B-Tree를 사용하는 이유는 다음과 같다.
- 항상 정렬된 상태로 특정 값보다 크고 작은 부등호 연산에 문제가 없다.
- 참조 포인터가 적어 방대한 데이터 양에도 빠른 메모리 접근이 가능하다.
- 데이터 탐색뿐 아니라, 저장, 수정, 삭제에도 항상 O(logN)의 시간 복잡도를 가진다.
⭐ B+-Tree란?
B+Tree는 모든 노드에 데이터(Value)를 저장했던 B-Tree와 다른 특성을 가지고 있다.
-
Leaf Node만 인덱스와 함께 데이터를 가지고 있고, 나머지 노드(Inner Node)들은 데이터를 위한 인덱스(Key)만을 갖는다.
-
Leaf Node들은 LinkedList로 연결되어 있다.
BTree의 리프노드들을 LinkedList로 연결하여 순차검색을 용이하게 하는 등 B-Tree를 인덱스에 맞게 최적화하였다. (물론 Best Case에 대해 리프노드까지 가지 않아도 탐색할 수 있는 B-Tree에 비해 무조건 리프노드까지 가야한다는 단점도 있다.)
⭐ B-Tree와 B+-Tree 비교
| 구분 | B-tree | B+tree |
|---|---|---|
| 데이터 저장 | 리프 노드, 브랜치 노드 모두 데이터 저장 가능 | 오직 리프 노드에만 데이터 저장 가능 |
| 트리의 높이 | 높음 | 낮음(한 노드 당 key를 많이 담을 수 있음) |
| 풀 스캔 시, 검색 속도 | 모든 노드 탐색 | 리프 노드에서 선형 탐색 |
| 키 중복 | 없음 | 있음(리프 노드에 모든 데이터가 있기 때문) |
| 검색 | 자주 access 되는 노드를 루트 노드 가까이 배치할 수 있고, 루트 노드에서 가까울 경우, 브랜치 노드에도 데이터가 존재하기 때문에 빠름 | 리프 노드까지 가야 데이터 존재 |
| 링크드 리스트 | 없음 | 리프 노드끼리 링크드리스트로 연결 |
🙏 참고 자료
https://helloinyong.tistory.com/296
https://zorba91.tistory.com/293
https://mangkyu.tistory.com/96
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=bsww201&logNo=221906066898
