
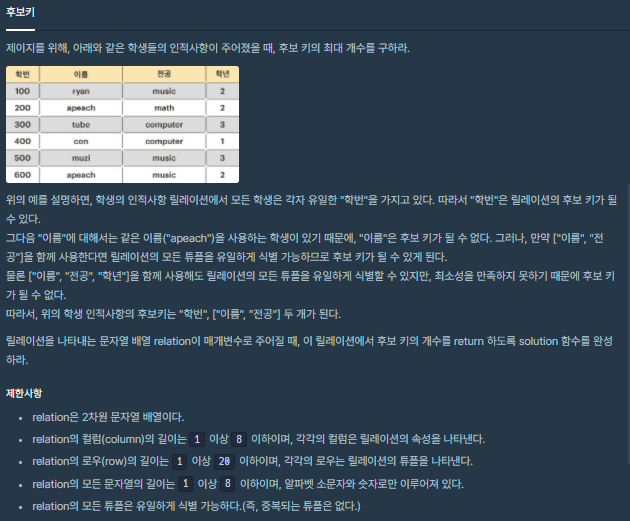
🧐 문제 설명
😍 나의 풀이
제한 조건에서 column의 길이가 1이상 8이하여서 combinations를 이용해 columns의 가능한 모든 인덱스 조합을 구했다. 그렇게 나온 조합들을 대상으로 유일성을 먼저 검사 → 최소성을 검사 해서 나온 값들을 unique라는 리스트에 넣어 그 길이를 출력했다.
-
유일성을 검사하는 아이디어는 조합의 인덱스 조합을 릴레이션 item에 해당하는 속성 값을 추출해서 tuple에 담아 리스트로 모아둔 값이 row의 길이와 같은지 체크했다.(중복성 체크)
-
최소성을 검사하는 아이디어는 유일성을 검사하고 나온 튜플 set들을 set의 부분집합인지 찾는 메소드인 issubset()을 사용해서 아닌 경우들만 unique 리스트에 넣었다.
이 과정에서 발생한 문제점은 최소성을 검사할 때 issubset()을 사용하려고 하니까 자료형이 set이어야 했다. 또, 원래 코드는 유일성 검사된 인덱스 조합만 리스트에 먼저 넣어놓고 리스트를 이중 for문으로 검사하면서 issubset()을 사용하려고 했는데 set()에서는 subscriptable이 허용되지 않았다. 즉, set은 각각의 요소에 접근이 불가능했다. 그렇다고 tuple, list형태에서는 set의 메소드 issubset()을 사용 못해서 어려웠다.
from itertools import combinations
def solution(relation):
row = len(relation)
col = len(relation[0])
#가능한 속성의 모든 인덱스 조합
combi = []
for i in range(1, col+1):
combi.extend(combinations(range(col), i))
#유일성
unique = []
for i in combi:
tmp = [tuple([item[key] for key in i]) for item in relation]
if len(set(tmp)) == row: # 유일성
put = True
for x in unique:
if set(x).issubset(set(i)): # 최소성
put = False
break
if put: unique.append(i)
return len(unique)👏 다른 사람의 풀이
비트 연산을 이용한 풀이. 이 풀이는 4개의 컬럼을 조합하는 모든 경우의 수는 4비트로 표현 가능하다는 점에서 조합부터 비트를 이용했다. 예를 들어 학번만 포함하는 경우 0001, 학번과 이름을 포함하는 경우 0011 이런식... 어떻게 생각하지 이걸
def solution(relation):
answer_list = list()
for i in range(1, 1 << len(relation[0])):
tmp_set = set()
for j in range(len(relation)):
tmp = ''
for k in range(len(relation[0])):
if i & (1 << k):
tmp += str(relation[j][k])
tmp_set.add(tmp)
if len(tmp_set) == len(relation):
not_duplicate = True
for num in answer_list:
if (num & i) == num:
not_duplicate = False
break
if not_duplicate:
answer_list.append(i)
return len(answer_list)🥇 Today I Learn
append()와 extend() 차이
- append()는 리스트에 요소 추가
x = [1, 2, 3]
x.append([4, 5])
-------------------
x = [1, 2, 3, [4, 5]]- extend()는 리스트에 같은 배열로 추가(확장)
x = [1, 2, 3]
x.extend([4, 5])
------------------
x = [1, 2, 3, 4, 5] # extend는 object의 element들을 추가Tuple
- 요소를 삭제하거나 변경할 수 없다(immutable, 불변성)
→ 일단 정의되고 나면 값을 추가, 변경할 수 없음.추가하려면 리스트로 변경해서 append()하고 다시 튜플로 변환하는 것뿐... - indexing 가능(iterable)
- 다른 타입의 데이터를 같이 담을 수 있음 ex) ('abc', 1, 2, 3)
Set
- 순서가 없고 중복이 불가능한 자료형
- 요소들 간 순서가 없어서 indexing이 불가능(Not iterable)
- 가변성(mutable)
Set에서 사용하는 함수
-
add(값) - 집합에 새로운 값을 추가한다. (중복된 값은 무시)
-
remove(값) - 전달받은 값을 삭제 (없을 때 에러 메시지를 출력)
-
discard(값) - 전달받은 값을 삭제 (없을 때 그냥 무시)
-
clear() - 집합에 있는 모든 값을 삭제
s = {1, 2, 3, 4, 5}
s.add(6)
-------------------
s = {1, 2, 3, 4, 5, 6} # 결과
s.remove(7) # Error
s.discard(6)
-------------------
s = {1, 2, 3, 4, 5} # 결과
s.clear()
-------------------
s = {} # 결과-
isdisjoint() - 두 집합이 공통 원소를 갖지 않는가?
-
issubset() - 부분집합(subset)인가?
-
issuperset() - 확대집합(superset)인가?
→ True or False 출력함
-
union() - 합집합을 만들어 리턴
-
update() - 합집합을 만들어 원본 데이터를 갱신(수정)
-
difference() - 차집합을 만들어 리턴
-
intersection() - 교집합을 만들어 리턴
s1 = {1, 2, 3, 4, 5}
s2 = {2, 3, 4}
s1.intersection(s2)
--------------------
{2, 3, 4} # 결과