
두 가지 생성 패턴을 알아볼텐데, 둘다 객체를 생성하는 부분을 분리해서 캡슐화 시켜서
OCP(변경-폐쇄 원칙)와DIP(의존성 역전 원칙)까지 지킬 수 있는 패턴이다.
1. 팩토리 패턴
- 객체 생성용 인터페이스 정의, 객체 생성 관련 패턴
- 한 제품을 생산하는데 필요한 추상 인터페이스를 제공한다.
- 상속을 통해 객체 생성을 서브 클래스에서 팩터리 메서드를 재정의함으로써 이루어진다.

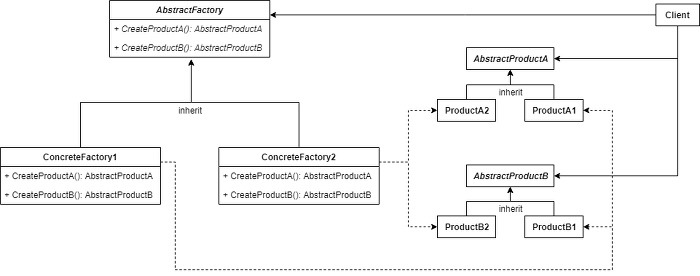
2. 추상 팩토리 패턴
- 제품 군, 즉 다양한 종류의 객체를 생성하는 추상 인터페이스를 제공한다.
- 구상(composition)을 통해 구체적인 클래스를 명시하지 않고, 관련된 혹은 의존적인 객체들을 생성 할 수 있는 인터페이스를 제공한다.
그렇다면 왜
new를 통해서 객체들을 생성하는 것이 문제가 될까?
☁️ new를 통한 객체 생성의 문제
new 키워드는, 인터페이스가 아닌 실제 클래스(Concrete Class)의 객체를 생성한다. 따라서, 생성해야할 객체가 늘어나는 등 조건이 바뀌면 클라이언트 측 코드까지 변경이 일어나 OCP 를 위반하게 된다. 아래 예시를 보자.
Pizza orderPizza(String type) {
Pizza pizza;
if (type.equals("cheese")) { //바뀌는 부분
pizza = new CheesePizza();
} else if (type.equals("greek") {
pizza = new GreekPizza();
} else if (type.equals("pepperoni") {
pizza = new PepperoniPizza();
}
prepareToBoxing(pizza); //바뀌지 않는 부분
return pizza;
}
void prepareToBoxing(Pizza pizza) {
pizza.prepare();
pizza.bake();
pizza.cut();
pizza.box();
}위 코드에서는, 피자 즉 객체의 종류가 바뀔 때마다 클라이언트 코드를 수정해주어야 하는 문제가 발생한다.
따라서 변경되어야 하는 부분은 수정이 용이하도록, 변경되지 않는 부분은 고정되도록 만들어야 한다. 즉, 객체 생성하는 부분을 따로 빼내서 인터페이스를 만들고 그것을 구현하여 다양한 실제 클래스들을 만드는 것이 더 융퉁성이 높다.
☁️ 팩토리 패턴을 도입해보자
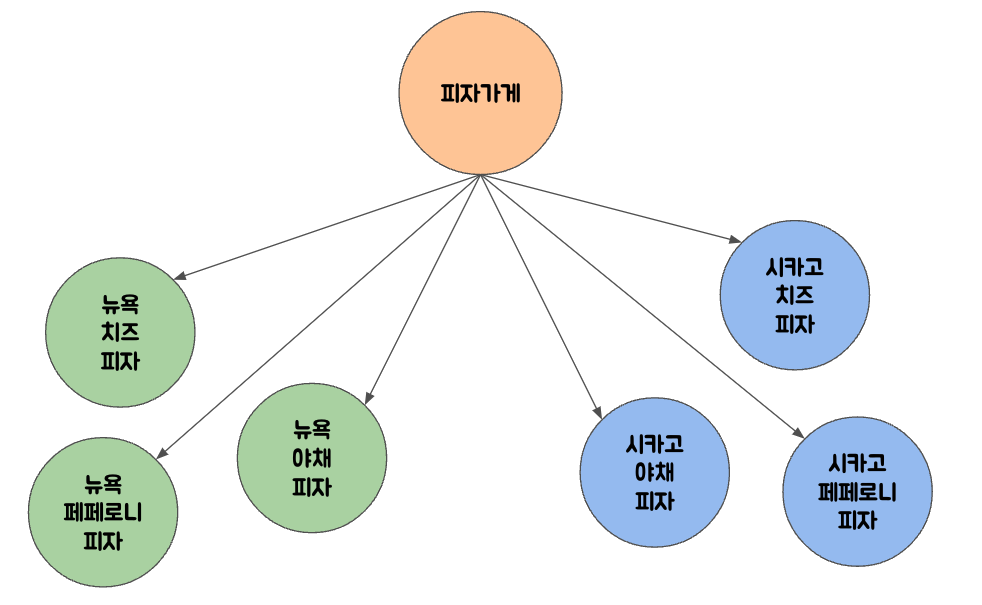
단순히 객체 생성하는 분기문을 Factory 라는 클래스를 만들어 옮겨도 된다. 하지만, 만약 기본 피자 팩토리가 아닌 여러 지점의 팩토리가 필요하다면?
NYPizzaFactory nyFactory = new NYPizzaFactory();
PizzaStore nyStore = new PizzaStore(nyFactory);
nyStore.order("veggie");피자 스토어마다 다른 처리 과정이 나타날 수 있다는 문제점, 그리고 피자 생성 과정과 피자 주문이 분리되어 있어, 일괄적인 처리가 어려울 수 있다는 단점이 존재한다.
추상 클래스와 상속을 활용

피자 가게와 피자 제작 과정 전체를 하나로 묶어주려면, 바뀌는 부분인 createPizza() 메소드를 추상 메소드로 선언하고 상속받아서 구현하도록 하면 된다.
당연한 얘기지만, 객체 생성 대상인 Pizza 역시 추상 클래스로 선언하고 상속받아서 서브 클래스들을 생성해야 한다.
public abstract class PizzaStore {
void prepareToBoxing(Pizza pizza) { //변하지 x
pizza.prepare();
pizza.bake();
pizza.cut();
pizza.box();
}
public Pizza orderPizza(String type) { //변하지 x
Pizza pizza = createPizza(type);
prepareToBoxing(pizza);
return pizza;
}
abstract Pizza createPizza(String type); // 팩토리 메소드!(변하는 객체 생성하는 부분)
}public class NYPizzaStore extends PizzaStore {
Pizza createPizza(String type) {
if type.equals("cheese")) {
pizza = new NYStyleCheesePizza(); //실제 클래스 생성
} else if (type.equals("pepperoni")) {
pizza = new NYStylePepperoniPizza();
} else if (type.equals("clam")) {
pizza = new NYStyleClamPizza();
} else if (type.equals("veggie")) {
pizza = new NYStyleVeggiePizza();
}
}
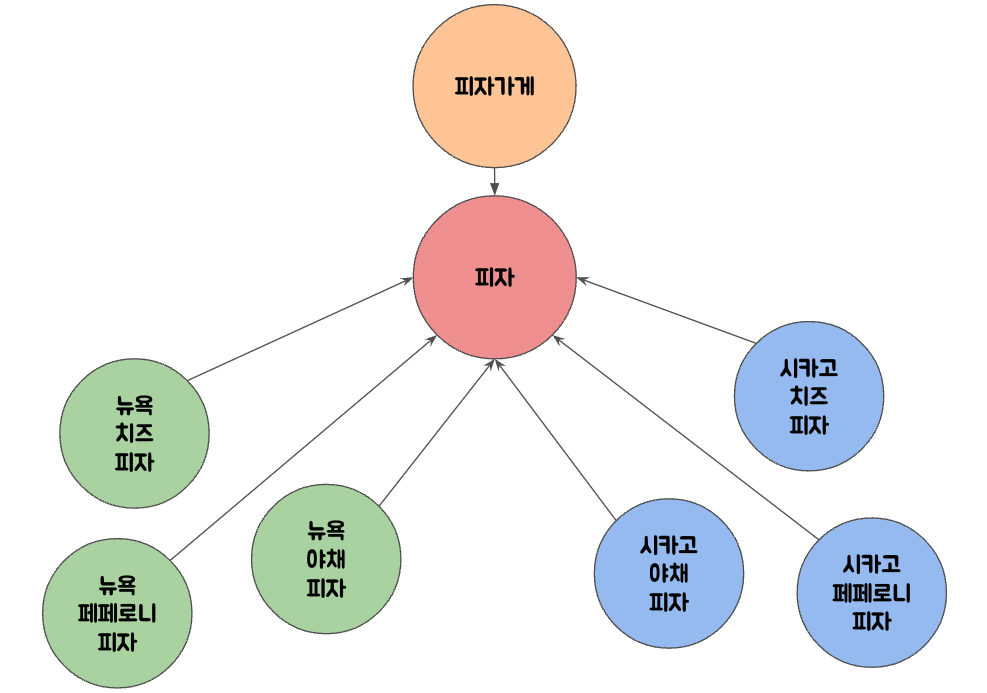
}앞에서와 달리 의존성이 역전된 것이 보이는가?
이전에는 피자 구상 클래스가 변경되면 PizzaStore 까지 변경이 일어났다. 즉, PizzaStore 가 구체 클래스 Pizza 에 의존했다. 하지만 이제는 아래 그림처럼 Pizza 인터페이스가 중간에 끼게 되면서, 의존성이 반대로 역전되었다.
이처럼 추상 클래스나 인터페이스와 같이 추상적인 것에 의존하는 코드를 만들어야 하는 것이 바로 의존성 역전 원칙이다.
https://velog.io/@ljo_0920/팩토리-패턴-팩토리-메서드
- 팩토리 메소드는 클라이언트(수퍼클래스의 orderPizza() 같은 코드)에서 실제로 생성되는 실제 객체가 무엇인지 알 수 없게 만드는 역할
팩토리 패턴 장점
팩토리 패턴 단점
☁️ 추상 팩토리 패턴을 도입해보자
추가적으로 각 분점에서 재료들을 일관되게 공급하고 싶어졌다고 가정해보자. 이번에는 객체 생성 대상이 피자 하나가 아닌, 재료들(제품군)이 된다. 그리고 이럴때 인터페이스를 활용하는 추상 팩토리 패턴을 사용할 수 있다.
public interface PizzaIngredientFactory {
public Dough createDough();
public Sauce createSauce();
public Cheese createCheese();
public Veggies[] createVeggies();
public Pepperoni createPepperoni();
public Clams createClam();
}이제 해당 인터페이스를 상속받아서 각 지점에 맞는 재료들을 준비할 수 있다. 그리고 이렇게 준비된 재료들을 Pizza 생성 전에 세팅만 해주면 된다.
public abstract class Pizza {
String name;
Dough dough;
Sauce sauce;
Veggies veggies[];
...
abstract void prepare(); //여기서 재료들을 다르게 factory에서 공급
void bake() {
System.out.println("Bake for 25 minutes at 350");
}
...
}public class CheesePizza extends Pizza {
PizzaIngredientFactory ingredientFactory;
public CheesePizza(PizzaIngredientFactory ingredientFactory) {
this.ingredientFactory = ingredientFactory;
}
void prepare() {
dough = ingredientFactory.createDough();
sauce = ingredientFactory.createSauce();
cheese = ingredientFactory.createCheese();
}
}그리고 각 지점의 PizzaStore 은 같은 지점의 IngredientFactory 를 내부 필드로 가지고 있어서, 피자를 생성할 때 인자로 넘겨주면 된다.
public class NYPizzaStore extends PizzaStore {
protected Pizza createPizza(String item) {
Pizza pizza = null;
PizzaIngredientFactory ingredientFactory = new NYPizzaIngredientFactory();
if (item.equals("cheese")) {
pizza = new CheesePizza(ingredientFactory);
pizza.setName("New York Style Cheese Pizza");
} else if (item.equals("veggie")) {
...
}
return pizza;
}
}이렇게 추상 팩토리를 통해서 제품군을 생성하기 위한 인터페이스 제공할 수 있다.
추상 팩터리 패턴 장점
추상 팩터리 패턴 단점
☁️ Java에서의 팩토리 패턴: Java.util

Product:Iterator가 생성 대상이다.ConcreteProduct:Itr,ListItr구체 클래스를 생성해야 하는 상황이다.Creator:Collection이 인터페이스로, 팩토리 메서드인iterator()를 가지고 있다.Concrete Creator:ArrayList,LinkedList는Collection을 상속받아 각자에 맞는Iterator를 만들어낸다.
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
public ListIterator<E> listIterator() {
return new ListItr(0);
}
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {
}
}☁️ Spring에서의 팩토리 패턴: BeanFactory
잠깐, DI 하면 스프링에서 바로 떠오르는게 있지 않는가?
그렇다. 바로 객체를 생성 및 관리하고, 의존관계 연결 까지 해주는 DI 컨테이너, 스프링 컨테이너가 떠오를 것이다.

스프링 컨테이너 객체인 ApplicationContext 은 BeanFactory 자식 인터페이스들을 상속받고 있다.
AnnotationConfigApplicationContext 와 같이 여러 클래스들이 ApplicationContext 클래스를 구현을 사용하여 BeanFactory 인터페이스에서 상속된 다양한 팩토리 메소드를 통해 빈을 생성하고 있다.
public interface BeanFactory {
getBean(Class<T> requiredType);
getBean(Class<T> requiredType, Object... args);
getBean(String name);
}그리고 getBean 메서드가, 바로 팩터리 메서드라 볼 수 있다. 빈 이름이나, 클래스와 같은 조건으로 ApplicationContext 에 존재하는 모든 빈들을 조회해 적절한 빈을 생성해주기 때문이다.
단지 위 예제와 차이점이라면 위에서는 if-else 를 통해 객체의 구성과 생성을 같이 하고 있지만, 스프링에서는 @Configuration 를 통해 외부에서도 설정 정보를 받아서 도입할 수 있기 때문에 구성 및 생성 부분과 실행 부분을 분리하고 있어 더 유연하게 동작한다.
@Configuration
@ComponentScan(basePackageClasses = ApplicationConfig.class)
public class ApplicationConfig {
@Bean
public MemberService memberService(){ // 인터페이스 형태로 등록
return new MemberServiceImpl(memberRepository());
}
}