
Java 비동기 프로그래밍의 핵심인 CompletableFuture이 어떻게 진화를 해왔는지, 그리고 ForkJoinPool이라는 내부 동작 원리에 대해 알아보자.
Runnable부터 CompletableFuture까지의 진화
비동기를 이해하려면 Java가 멀티스레딩을 어떻게 발전시켜왔는지를 먼저 살펴보는 것이 좋다. Runnable → Future → CompletableFuture로 이어지는 흐름을 따라가 보자.
0. Runnable : 가장 원시적인 비동기
public interface Runnable {
void run();
}Runnable은 Java 1.0부터 존재했던 가장 기본적인 비동기 실행 단위이다. 하지만 두 가지 치명적인 한계가 있다.
- 반환값이 없다.
void run()이므로 작업 결과를 직접 받아올 수 없다. 결과를 얻으려면 멤버 변수에 저장해두고join()으로 스레드 종료를 기다린 뒤 직접 꺼내와야 한다. - 체크 예외를 던질 수 없다.
run()메서드 시그니처에throws가 없기 때문에, 내부에서 발생하는 체크 예외를 try-catch로 감싸야만 한다.
Thread thread = new Thread(() -> {
// 결과를 반환할 방법이 없다
// IOException 같은 체크 예외도 던질 수 없다
System.out.println("작업 수행");
});
thread.start();
thread.join(); // 끝날 때까지 블로킹결국 Runnable은 "일단 스레드에서 뭔가를 실행시킬 수 있다"는 의미만 있을 뿐, 비동기 작업의 결과를 다루기에는 너무 원시적이었다. 이를 보완하기 위해 Java 5에서 Callable과 Future가 등장한다.
1. Future와 Callable : 결과를 약속하다
public interface Callable<V> {
V call() throws Exception;
}Callable은 Runnable의 두 가지 한계를 모두 해결했다. 반환값(V)을 가질 수 있고, 체크 예외(throws Exception)도 던질 수 있다. 그리고 이 Callable의 실행 결과를 담는 그릇이 바로 Future이다.
ExecutorService executor = Executors.newSingleThreadExecutor();
Future<String> future = executor.submit(() -> {
Thread.sleep(1000);
return "작업 완료!";
});
String result = future.get(); // 결과가 올 때까지 블로킹Future는 비동기 작업의 결과를 "미래에 받겠다"고 약속하는 객체이다. 하지만 이 약속에도 꽤 심각한 문제들이 있었다.
Future의 한계점
get()을 호출하는 순간 블로킹된다. 비동기로 작업을 제출했는데, 결과를 가져오려면 결국 호출 스레드가 멈춰서 기다려야 한다. 이러면 비동기의 의미가 반감된다.- 작업 조합이 불가능하다. 여러 개의 Future 결과를 조합하고 싶을 때(예: A의 결과를 받아서 B를 실행), 깔끔한 방법이 없다.
- 콜백을 등록할 수 없다. "작업이 끝나면 이걸 해줘"라는 콜백 체인을 만들 수 없어, 결국 get()으로 블로킹하거나 별도의 폴링 로직을 짜야 한다.
- 외부에서 완료 시킬 수 없다. 타임아웃 등으로 강제 완료하는 것 외에는, 외부에서 Future의 상태를 직접 제어할 방법이 없다.
정리하면 Future는 "결과를 줄게"라는 약속은 해주지만, 그 약속을 이행받는 과정이 너무 불편했다. 결국 Java 8에서 이 모든 한계를 해결한 CompletableFuture가 등장하게 된다.
2. CompletableFuture : 진정한 비동기의 시작
CompletableFuture는 Future뿐만 아니라 CompletionStage 인터페이스까지 구현한다. CompletionStage가 핵심인데, 이 인터페이스가 바로 메서드 체이닝을 통한 작업 조합과 완료 콜백 등록을 가능하게 해준다.
기본 실행 : runAsync vs supplyAsync
CompletableFuture의 비동기 실행은 두 가지로 나뉜다.
| 메서드 | 파라미터 | 반환 타입 | 설명 |
|---|---|---|---|
runAsync() | Runnable | CompletableFuture<Void> | 반환값 X + 비동기 실행 |
supplyAsync() | Supplier<T> | CompletableFuture<T> | 반환값 O + 비동기 실행 |
// 반환값이 필요 없을 때
CompletableFuture<Void> future1 = CompletableFuture.runAsync(() -> {
System.out.println("로그 전송 완료");
});
// 반환값이 필요할 때
CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() -> {
return fetchUserFromDB();
});콜백 체이닝 : thenApply, thenCompose, thenCombine
CompletableFuture의 진가는 콜백 체이닝에서 드러난다. 앞선 작업의 결과를 받아서 다음 작업을 이어가는 것이 자연스럽다.
CompletableFuture.supplyAsync(() -> fetchUser())
.thenApply(user -> user.getName()) // 결과 변환
.thenAccept(name -> System.out.println(name)) // 결과 소비
.exceptionally(ex -> { // 예외 처리
System.err.println("에러 발생: " + ex.getMessage());
return null;
});여기서 thenApply, thenCompose, thenCombine, exceptionally 네 가지 메서드를 잘 이해하는 것이 중요하다.
thenApply vs thenCompose : map vs flatMap
thenApply는 map 이고, 결과값을 변환(transform)할 때 사용한다.
T → UCompletableFuture<String> name = CompletableFuture
.supplyAsync(() -> fetchUser()) // CompletableFuture<User>
.thenApply(user -> user.getName()); // CompletableFuture<String>thenCompose는 flatMap 이다. 즉 변환 함수 자체가 CompletableFuture를 반환할 때 사용한다.
T → CompletableFuture<U>CompletableFuture<Order> order = CompletableFuture
.supplyAsync(() -> fetchUser()) // CompletableFuture<User>
.thenCompose(user -> fetchOrder(user.getId())); // CompletableFuture<Order>그런데 여기서 의문이 생길 수 있다. "thenApply로 해도 되지 않나?"
만약 fetchOrder()가 CompletableFuture<Order>를 반환하는 비동기 메서드라면 thenApply를 쓸 경우 반환 타입이 CompletableFuture<CompletableFuture<Order>>가 되어버린다. CompletableFuture가 이중으로 감싸지는 것이다. thenCompose는 이 중첩을 풀어(flatten) CompletableFuture<Order>로 만들어준다.
thenApply → CompletableFuture<CompletableFuture<T>> // 이중 래핑
thenCompose → CompletableFuture<T> // 깔끔하게 평탄화thenCombine : 두 비동기 작업의 결과를 합치기
두 개의 독립적인 비동기 작업이 모두 완료된 후 결과를 합쳐야 할 때 사용한다.
CompletableFuture<String> userFuture = CompletableFuture.supplyAsync(() -> fetchUser());
CompletableFuture<String> orderFuture = CompletableFuture.supplyAsync(() -> fetchOrder());
CompletableFuture<String> combined = userFuture.thenCombine(orderFuture,
(user, order) -> user + "님의 주문: " + order);thenApply/thenCompose가 순차적 체이닝이라면, thenCombine은 병렬 작업의 결합이다. 두 작업이 서로 의존하지 않는다면 thenCombine으로 병렬 실행하여 전체 처리 시간을 줄일 수 있다.
exceptionally : 예외 처리
CompletableFuture.supplyAsync(() -> {
if (true) throw new RuntimeException("API 호출 실패");
return "결과";
})
.exceptionally(ex -> {
log.error("에러 발생", ex);
return "기본값"; // 대체값 반환
});CompletableFuture는 어떻게 Thread를 관리하는가? : ForkJoinPool
여기서 한 가지 궁금증이 생길 수 있다. supplyAsync()나 runAsync()를 호출하면 별도의 스레드에서 작업이 실행된다는 건 알겠는데, 그 스레드는 대체 어디서 오는 걸까?
정답은 ForkJoinPool.commonPool() 이다. CompletableFuture는 별도의 Executor를 지정하지 않으면 기본적으로 JVM 전체에서 공유하는 ForkJoinPool의 common pool을 사용한다.
ForkJoinPool의 핵심 특징 : Work Stealing
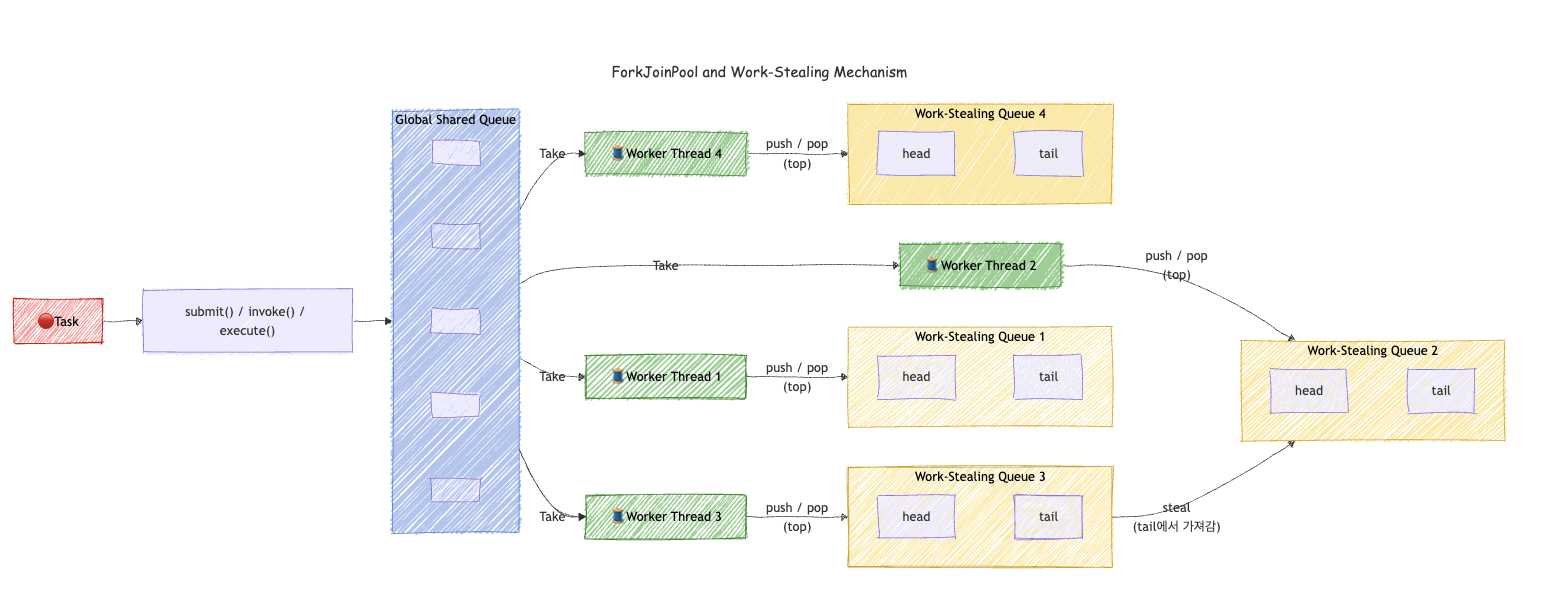
ForkJoinPool은 일반적인 ThreadPoolExecutor와 다르게 work stealing(작업 훔치기) 알고리즘을 사용한다. 각 워커 스레드가 자신만의 작업 큐(deque)를 가지고 있고, 자기 큐가 비면 다른 스레드의 큐에서 작업을 가져와 실행한다. 이 덕분에 CPU 바운드 작업에서 스레드 활용률이 극대화된다.
왜 blocking 작업에 ForkJoinPool을 쓰면 안 되는가?
문제는 ForkJoinPool의 common pool 스레드 수가 기본적으로 CPU 코어 수 - 1로 설정된다는 것이다. 만약 여기에 blocking 작업을 넣으면 어떻게 될까?
// 위험한 코드
CompletableFuture.supplyAsync(() -> {
Thread.sleep(1000); // I/O 대기, DB 호출 등
return result;
});common pool의 스레드가 고작 7개(8코어 기준)인데, 이 스레드들이 전부 Thread.sleep()이나 DB 호출 같은 블로킹 작업에 묶여버리면 다른 CompletableFuture 작업들이 실행되지 못하고 줄줄이 대기하게 된다. 이를 ForkJoinPool starvation(기아 현상) 이라고 한다.
더 무서운 건 ForkJoinPool.commonPool()이 JVM 전역에서 공유된다는 점이다. 내가 만든 코드뿐 아니라 같은 JVM 위에서 동작하는 다른 라이브러리, 프레임워크의 CompletableFuture 작업까지 모두 영향을 받는다.
실무에서의 해결법 : Custom Executor
따라서 I/O 바운드 작업이나 블로킹이 발생할 수 있는 작업에는 별도의 Executor를 지정하는 것이 실무에서의 표준이다.
ExecutorService customExecutor = Executors.newFixedThreadPool(20);
CompletableFuture.supplyAsync(() -> {
return callExternalAPI(); // blocking I/O
}, customExecutor); // common pool 대신 전용 스레드풀 사용정리하면 다음과 같다.
| 작업 유형 | 적합한 Executor | 이유 |
|---|---|---|
| CPU 바운드 (연산, 변환) | ForkJoinPool.commonPool() (기본) | work stealing으로 효율 극대화 |
| I/O 바운드 (DB, API 호출) | 별도 ThreadPoolExecutor | 블로킹으로 인한 starvation 방지 |
참고 자료
