
프로젝트에서 외부 API를 호출해서 열차 정보들을 받아오고 있는데, 만약 외부 API 서버가 장애가 발생해서 응답이 지연된다면 우리 서버에는 어떤 상황이 발생하고, 어떻게 해결할 수 있을까? 라는 궁금증이 생겨 작성한 글이다.
현재 서버에서는 Blocking I/O 방식인 RestTemplate 을 활용해 외부 API를 호출하고 있다.
val response = restTemplate.exchange(url, HttpMethod.GET, null, TrainRealTimeDto::class.java).body!!그러다 보니 만약 외부 API가 느려진다면? 이론적으로 생각해보면 톰캣은 미리 스레드를 생성해놓는 스레드 풀 방식을 사용하니 대규모 트래픽이 들어오는 상황에서 maxThreads 만큼 스레드가 모두 사용 중이면 그 이후의 요청은 큐에서 대기하게 된다. 즉 전체 처리량이 매우 낮아지게 되는 문제가 발생할 것이다.
따라서 이런 현상을 정상/장애 상황에서 직접 부하테스트를 통해 TPS 값을 측정해보고 스레드 덤프로 스레드 상태를 확인해보며, 서버 안전성을 보장하기 위한 방법(서킷 브레이커 도입 등)에 대해 알아보자.
테스트 환경 세팅
1. WireMock을 통해 외부 API 지연시키기
우선 외부 API 응답을 인위적으로 늦추기 위해, HTTP 요청을 가로채고 원하는 응답을 조작할 수 있는 가짜 서버인 WireMock을 사용해볼 수 있다.
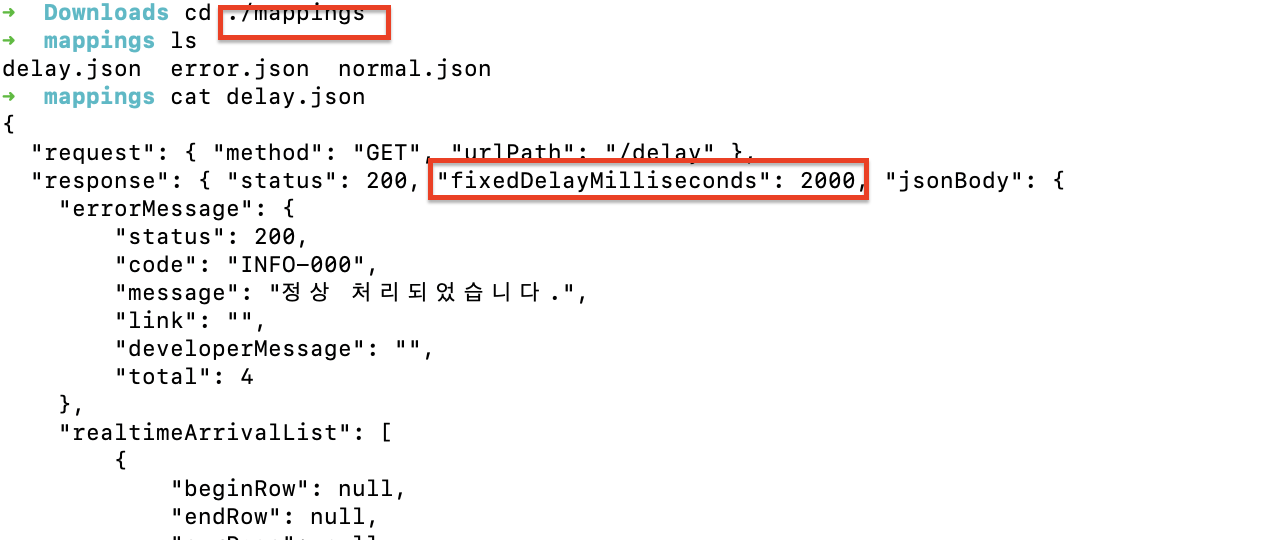
해당 링크에서 JAR 파일을 다운 받고, 다운받은 폴더로 들어가서 아래 명령어를 통해 실행시키면 된다.
java -jar wiremock-standalone-4.0.0-beta.15.jar --port 9090 처음 실행시키면 mappings 란 폴더가 자동으로 생성되는데, 해당 폴더 내부에 .json 형식의 stub 파일을 생성해두면 된다. 예를 들어 1) 정상 상태, 2) 응답 지연 2초, 3) 응답 지연 5초 + 500 에러 상황별로 총 세개의 상황을 테스트하기 위한 파일을 생성해둘 수 있다.
이후 스프링 서버에서 해당 임시 경로를 호출하도록 수정해주면 설정은 완료된다.
주의사항
WireMock 응답의 Content-Type이 application/octet-stream 이기 때문에, HttpMessageConverter 가 제대로 동작하기 위해서는 응답 헤더에 Content-Type을 application/json 으로 명시 해줘야 한다.
2. 스레드 덤프로 스레드 상태 확인하기
다음으로 스레드의 상태를 확인해보자. 시각적으로 빠르게 파악하려면 Java VisualVM 프로그램을 활용해볼 수 있고, 혹은 직접 스레드 덤프 명령어를 활용해볼 수 있다. 실제 스프링 부트 서버를 켜서 해당 스레드 정보들을 확인해보면, 아래처럼 다양한 스레드가 존재하는 것을 볼 수 있다.
우리가 집중적으로 확인해야 하는 것은 톰캣에서 요청을 처리하는 http-nio 로 시작하는 스레드이기 때문에 해당 정보 위주로 파악을 해보자.

톰캣의 NIO 커넥터 구조
http-nio-8080-Acceptor, http-nio-8080-Poller 같은 소수의 셀렉터 스레드가 연결과 이벤트를 처리하며, 실제 요청을 실행하는 워커 스레드는 http-nio-8080-exec-# 이다.
초기에는 기본값인 minSpareThreads(기본 10) 를 생성해두고, 부하가 증가할 때 exec 스레드를 늘려나가면서 최대 maxThreads(기본 200) 개까지 확장시킨다.
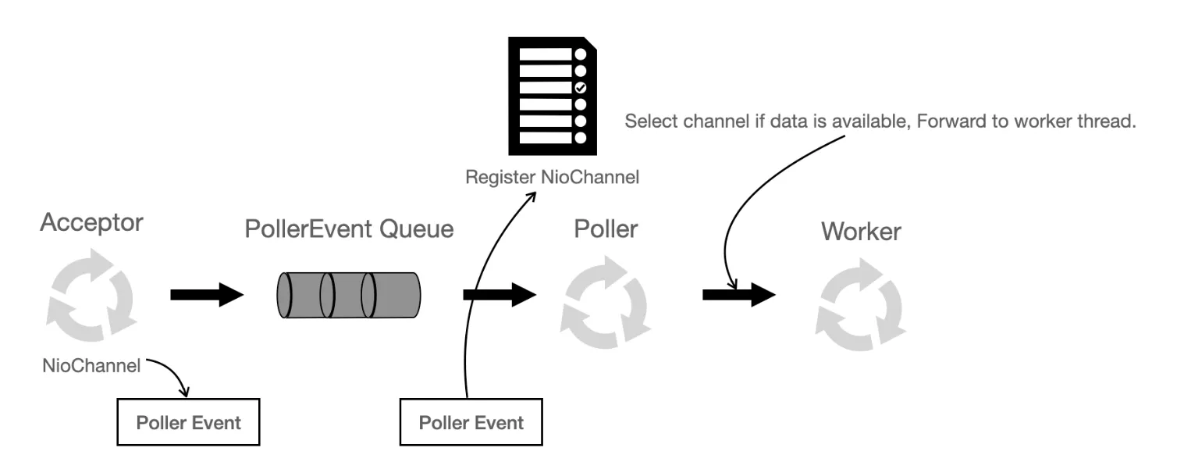
Acceptor: 소켓 요청을 받고, Poller Event 를 발생키셔 PollerEvent 큐에 저장한다.Poller: 하나의 스레드로, 내부에서 유지되는 셀렉터에 Poller Event의NIO 채널을 등록한다. 셀렉터에 등록되어 있는 다수의 채널 중select()를 통해 요청이 온(읽을 데이터가 있는) 소켓을 얻고, 해당 요청에 대한 처리를 워커 스레드풀에서 가져온워커 스레드에 할당시킨다.
BIO 커넥터와 다른 점은, 요청이 들어오면 바로 워커 스레드에 할당시키지 않고, 셀렉터에 등록해두었다가 실제 데이터 처리가 가능한 경우일 때 워커 스레드를 할당시킨다는 점이다. 즉 연결은 많지만 실제 요청은 드문 상황에서 발생하는 스레드 낭비(idle)를 줄여준다는 장점이 있다.
Thread Dump를 통해 스레드 상태 파악하기
스레드 상태를 파악하려면, 우선 스레드 덤프를 통해 자세한 정보를 추출해내야 한다. 아래와 같은 명령어를 직접 사용하거나 Java VisualVM 내부 기능을 활용하면 편하다.
# spring boot server의 port인 8080을 사용하고 있는 프로세스를 찾아서 스레드 덤프를 뜬다.
jstack $(lsof -t -iTCP:8080 -sTCP:LISTEN) > thread_dump.txtJava VisualVM 스레드 탭을 보면 다음과 같은 상태들을 확인할 수 있는데, 실제 자바 공식 문서에도 나와있듯이 스레드는 아래와 같은 총 5가지의 상태를 가진다.

-
NEW: 스레드가 생성되었으나 아직 시작되지 않은 상태로,Thread.start()를 호출해야 OS가 실제로 스레드를 생성하도록 신호를 보냄 -
RUNNABLE(RUNNING): 스레드가 실행 가능하여 운영 체제의 자원(ex) CPU)을 기다리고 있거나 스케줄러에 의해 선택되어 JVM 내에서 실행중인 상태 -
BLOCKED(MONITOR): 스레드가 모니터 락을 기다리며 블록된 상태로, synchronized 블록/메서드에 들어가기 위해 또는Object.wait호출 시 해당 상태가 됌 -
WAITING(WAIT/PARK): 무한정 대기 중인 상태로,Object.wait(타임아웃 X),Thread.join(타임아웃 X),LockSupport.park호출 시 해당 상태가 됌 -
TIMED_WAITING(SLEEPING/PARK): 스레드가 지정된 시간 동안 대기하는 상태로,
Thread.sleep,Object.wait (타임아웃 O),Thread.join (타임아웃 O),LockSupport.parkNanos,LockSupport.parkUntil호출 시 해당 상태가 됌 -
TERMINATED: 실행 완료되었거나 예외가 발생하여 종료된 스레드의 상태
그러면 이중에 Blocking I/O 가 발생한 스레드는 어떤 상태를 가지게 될까?
우선 요청을 받고 있지 않는 초기 상태의 스레드는 아래 사진에서 보면 알 수 있듯이 LockSupport.park 메서드 호출로 인해 WAITING 상태가 된다.
사실 로그를 자세히 보면 Thread.run 시 어떤 일들이 발생하고 어떤 스레드 풀 모델을 사용하는지 등을 알 수 있는데, ForkJoinPool 이나 LockSupport 개념 관련해서는 너무 길어지는 관계로 추후 따로 공부해서 포스팅해보겠다.
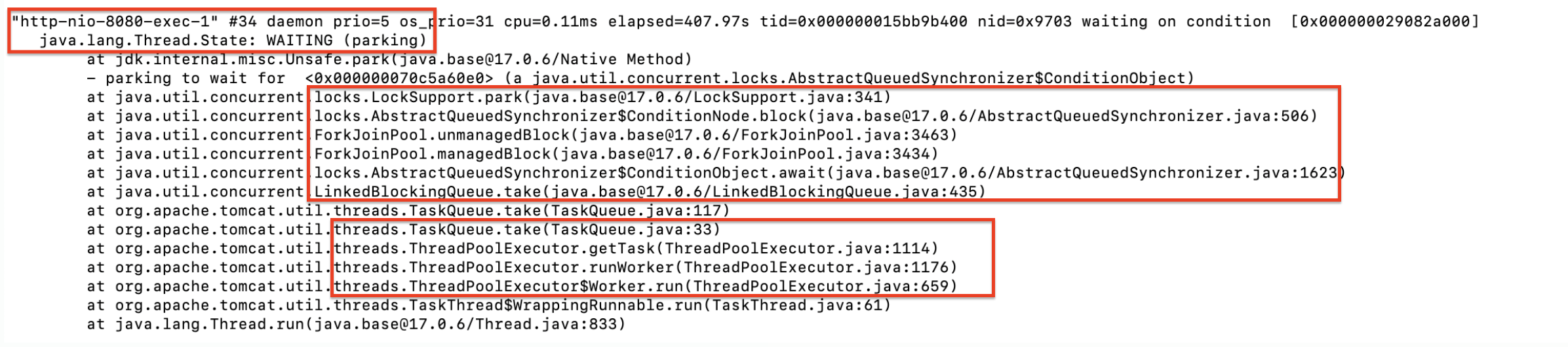
따라서 Blocking I/O 가 발생한 스레드는 모니터 락이랑은 관련이 없기 때문에, 스레드 상태는 Runnable 이며 스택 트레이스를 확인해보면 socketRead 에서 멈춰 있는 것을 볼 수 있다.
"http-nio-8080-exec-97" #271 prio=5 tid=0x00007fcb7c123000 nid=0x6628 runnable [0x00007fcb64f9d000]
java.lang.Thread.State: RUNNABLE
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.read(SocketInputStream.java:150)
at org.apache.http.impl.io.AbstractSessionInputBuffer.fillBuffer(AbstractSessionInputBuffer.java:160)
at ...3. Jmeter로 부하 테스트하기
부하 테스트를 수행할 때는 별도 테스트 서버가 존재하는 Ngrinder를 사용할 수도 있지만, Jmeter가 이미 깔려있었고 러닝커브가 낮은 터라 선택했다. 단 로컬에서 테스트가 되기 때문에 서버 환경에 따라 결과가 영향을 받을 수 있다는 점을 주의하자.
Thread group을 생성할 때 다음과 같은 값들을 설정해서 부하를 생성하면 된다.

Number of Threads (users): 스레드수 - 유저 수Ramp-up period (seconds): 지정된 유저가 모두 로딩될 시간Loop Count: 반복 횟수
동시 요청 상황
Number of Threads 을 증가시키고, Ramp-up period 을 0으로 하면 1초 동안 트래픽이 몰리는 상황을 만들 수 있다.
요청이 천천히 증가하는 상황
Ram-up period를 설정하면 서버가 실제로 부하를 점진적으로 받는 상황을 시뮬레이션할 수 있다. 즉, 해당 시간동안 Jmeter가 총 요청을 분산시켜 점점 증가하는 형태로 요청을 보내므로 TPS 그래프는 보통 아래와 같이 나온다.
TPS
│
│
│ /‾‾‾‾‾‾‾‾‾‾‾
│ /
│ /
│ /
│ /
│__/____________________→ 시간참고로 아래에서 다시 언급하겠지만, 외부 API가 지연되는 상황에서 서킷 브레이커를 제대로 테스트 하려면 Ramp-up period 을 늘려야 한다.
왜냐하면 Resilience4j는 호출이 완료될 때 통계를 갱신하고 상태를 전이하는데, 만약 외부 API ReadTimeout이 3초라면 첫 실패들이 최소 3초 뒤에야 완료되고 실패로 기록되어 서킷이 OPEN 되기 때문이다.
문제는 OPEN 되기까지 이미 CLOSED 상태에서 외부 API로 요청이 출발해버리기 때문에, 추후 OPEN 되더라도 이미 출발한 요청을 막을 수 없어 fallback 메서드가 수행되지 않는다. 따라서 OPEN 이전에 이미 출발한 요청을 최대한 줄이려면 요청을 나눠서 요청하는 것이 좋다.
자 그러면 여기까지 테스트를 하기 위한 사전 지식과 준비는 완료되었다.
✅ 시나리오 1 : 외부 API 정상 호출
우선 외부 API가 지연 없이 정상적으로 호출되며, 1초에 400건(총 4000)씩 10초간 요청이 들어오는 상황을 테스트해보았다.

1) RestTemplate 커넥션 풀 X 타임아웃 설정 X
기본적으로 아무 설정을 해주지 않으면 RestTemplate은 SimpleClientHttpRequestFactory 를 사용해서 매 요청마다 새로운 HTTP 연결을 수립하고, 응답이 오지 않아도 계속 대기(timeout 기본값 무제한)를 한다.
@Configuration
class RestTemplateConfig {
@Bean
fun restTemplate(): RestTemplate {
return RestTemplate()
}
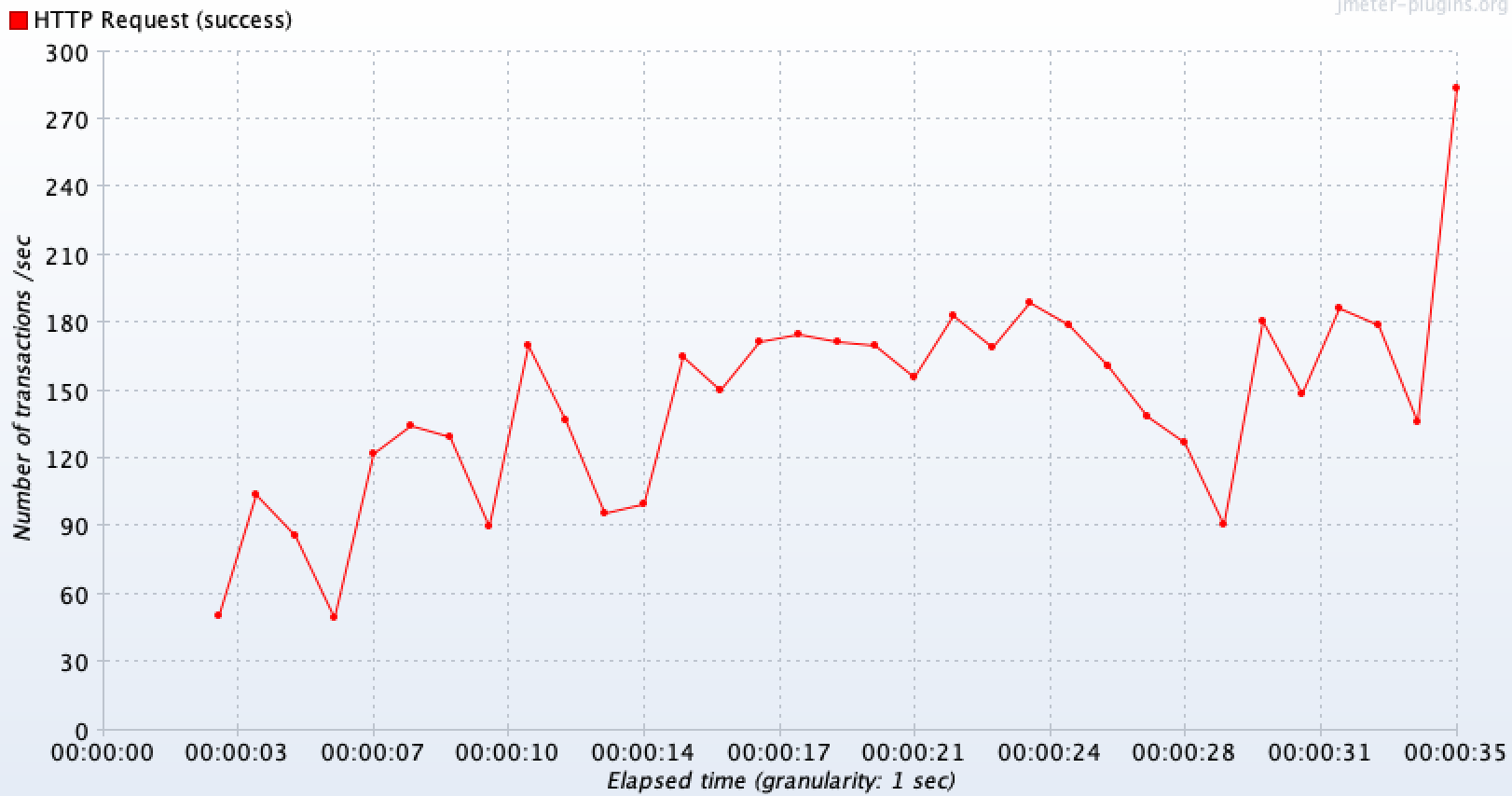
}TPS 결과
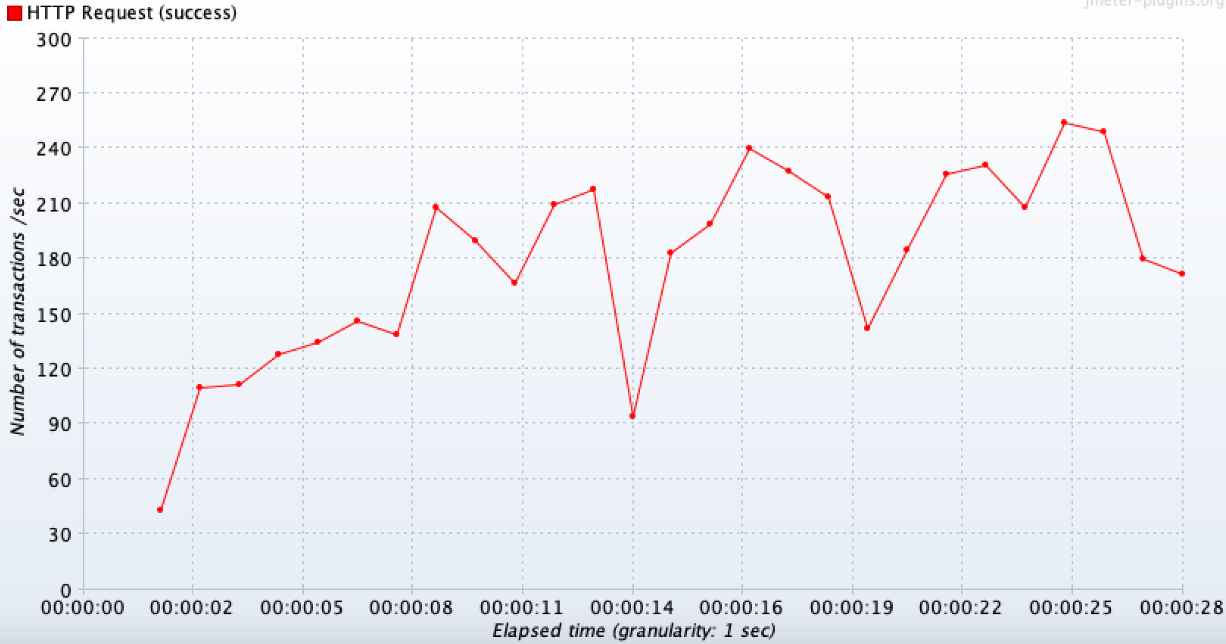
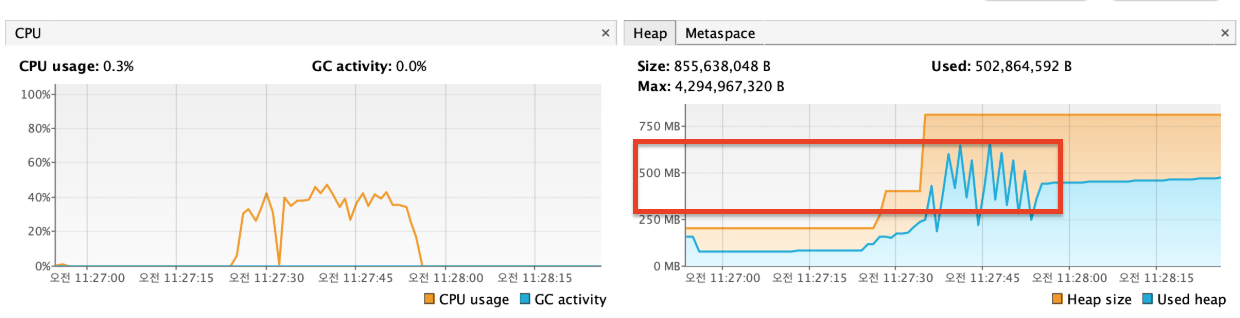
외부 API의 영향으로 인해 특정 지점 이후 일정하기보다 그래프가 요동치는 형태를 보인다. 평균적으로 180~200(평균 184) TPS가 나오며, 최대 250TPS가 나오는 것을 볼 수 있다. 초당 400 TPS 수준의 요청을 보냈지만 실제 처리율은 어플리케이션(스레드), 네트워크 I/O, DB(커넥션)단의 병목으로 인해 전체 요청 대비 대략 50%인 것을 볼 수 있다.
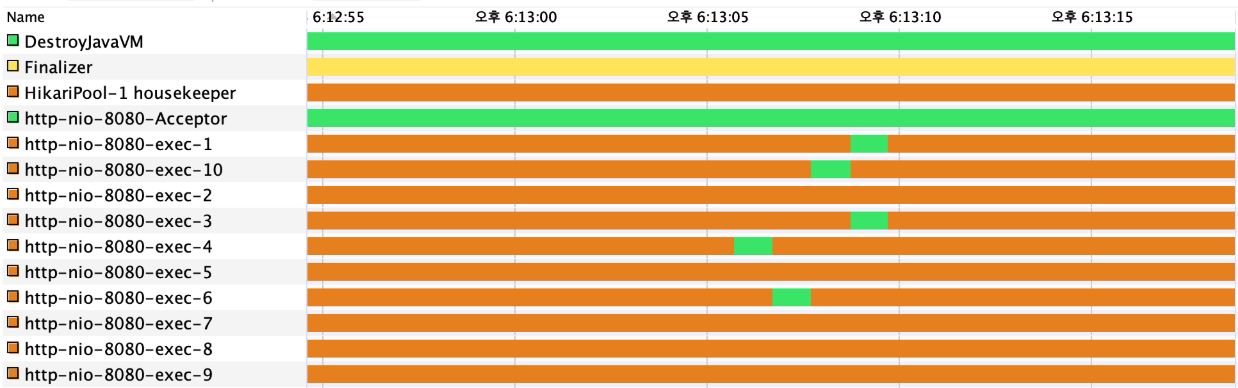
스레드 상태
스레드 상태를 확인해보면 기본 개수를 넘어 증가한 것을 볼 수 있으며, 요청을 처리한 이후 나머지 스레드들은 Keep-alive time 만큼의 시간이 지나면 자연스럽게 사라진다.
 |  |
|---|
2. RestTemplate 커넥션 풀 + 외부 타임아웃 설정에서 테스트
이제 커넥션 풀을 사용해서 미리 커넥션을 맺어두고, 3초 타임아웃을 지정해보자.
@Configuration
class RestTemplateConfig {
@Bean
fun poolingHttpClientConnectionManager(): PoolingHttpClientConnectionManager {
// 커넥션 풀 설정
val connectionManager = PoolingHttpClientConnectionManager().apply {
maxTotal = 200 // 전체 커넥션 최대 수
defaultMaxPerRoute = 50 // 라우트(target host)당 최대 커넥션 수
}
return connectionManager
}
@Bean
fun restTemplate(
connectionManager: PoolingHttpClientConnectionManager
): RestTemplate {
// 타임아웃 설정
val requestConfig = RequestConfig.custom()
.setConnectionRequestTimeout(Timeout.of(3000, TimeUnit.MILLISECONDS)) // 커넥션 풀에서 커넥션을 가져올 때 타임아웃
.setResponseTimeout(Timeout.of(3000, TimeUnit.MILLISECONDS)) // 응답 대기 시간 (소켓 읽기)
.build()
val httpClient = HttpClients.custom()
.setConnectionManager(connectionManager)
.setDefaultRequestConfig(requestConfig)
.build()
val requestFactory = HttpComponentsClientHttpRequestFactory(httpClient)
return RestTemplate(requestFactory)
}
}TPS 확인
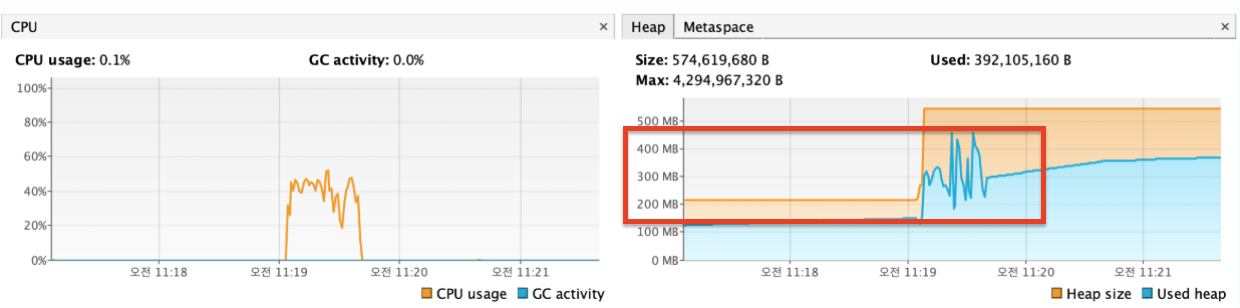
매번 외부 서버와 3-way handshaking으로 연결을 맺고,4-way handshaking으로 연결을 끊으며 발생하는 Timeout 오버헤드가 없어져서 그런지 평균 214TPS 로 처리량이 증가한 것을 볼 수 있다.
힙 메모리를 보면 커넥션 자원 사용량 측면에서도 유의미한 변화가 있는 것으로 보이며(600~700MB -> 400MB), 추후 응답이 딜레이 되는 상황에서 timeout 설정도 굉장히 큰 역할을 하게 될 것이다. 따라서 웬만하면 커넥션 풀과 타임아웃을 설정해주자.
외부 API에 캐싱 도입하기
만약 일정 시간 동안 같은 결과 값을 조회해도 괜찮거나, 클라이언트 단에서 값 조정이 가능한 경우에는 외부 API 결과값을 캐싱해서 전반적인 TPS를 향상시킬 수 있다.
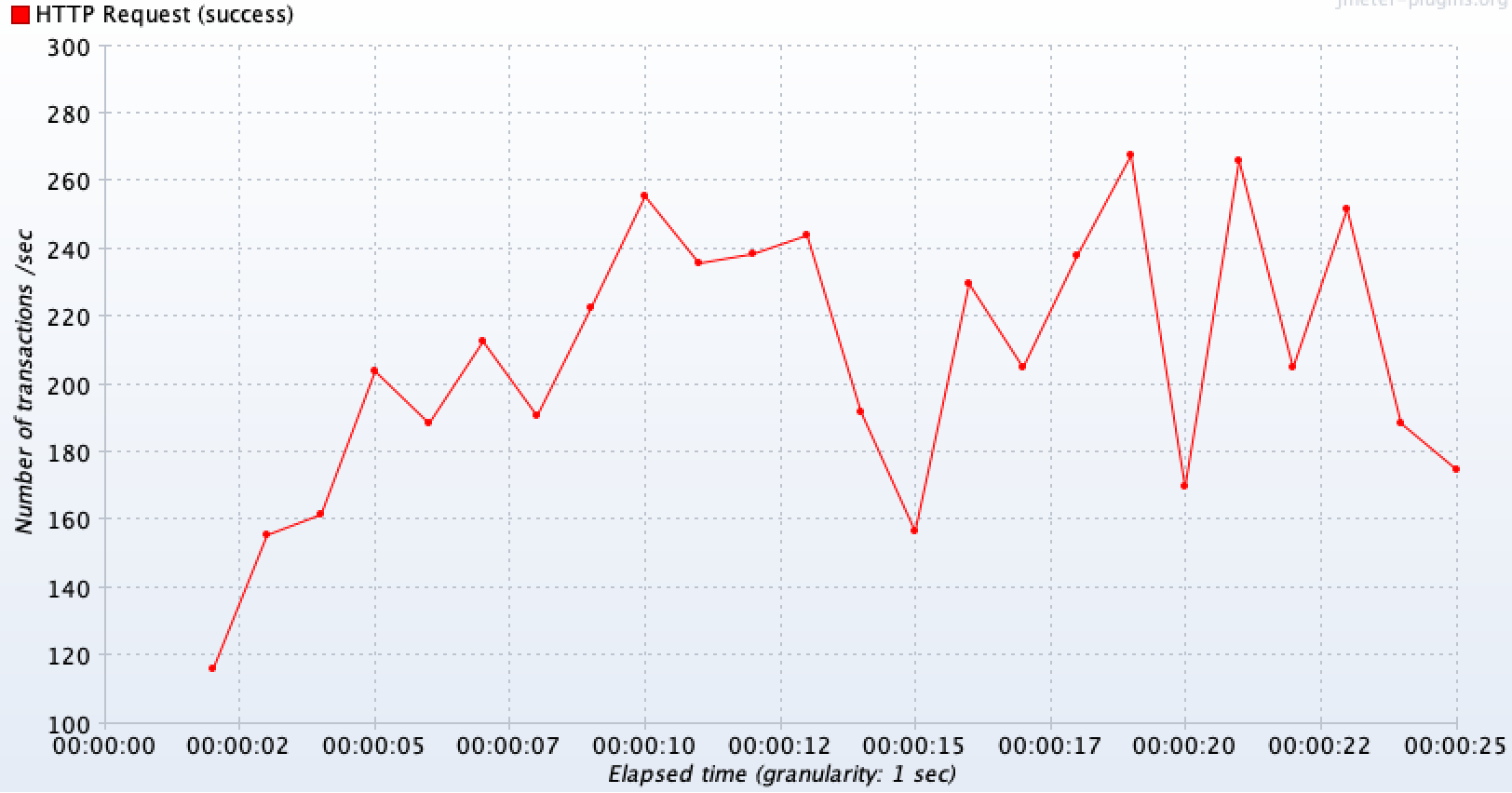
테스트 상황 : 1초에 200개씩 요청(총 4000개)
왼쪽이 캐싱을 도입했을때, 오른쪽이 같은 상황에서 캐싱을 제거했을 때이다.
초반 구간을 제외하면 외부 API를 호출하지 않고 캐시 데이터를 바로 반환하므로 요청이 들어온 만큼 안정적으로 모두 처리(약 200TPS)를 하고 있는 것을 볼 수 있다.
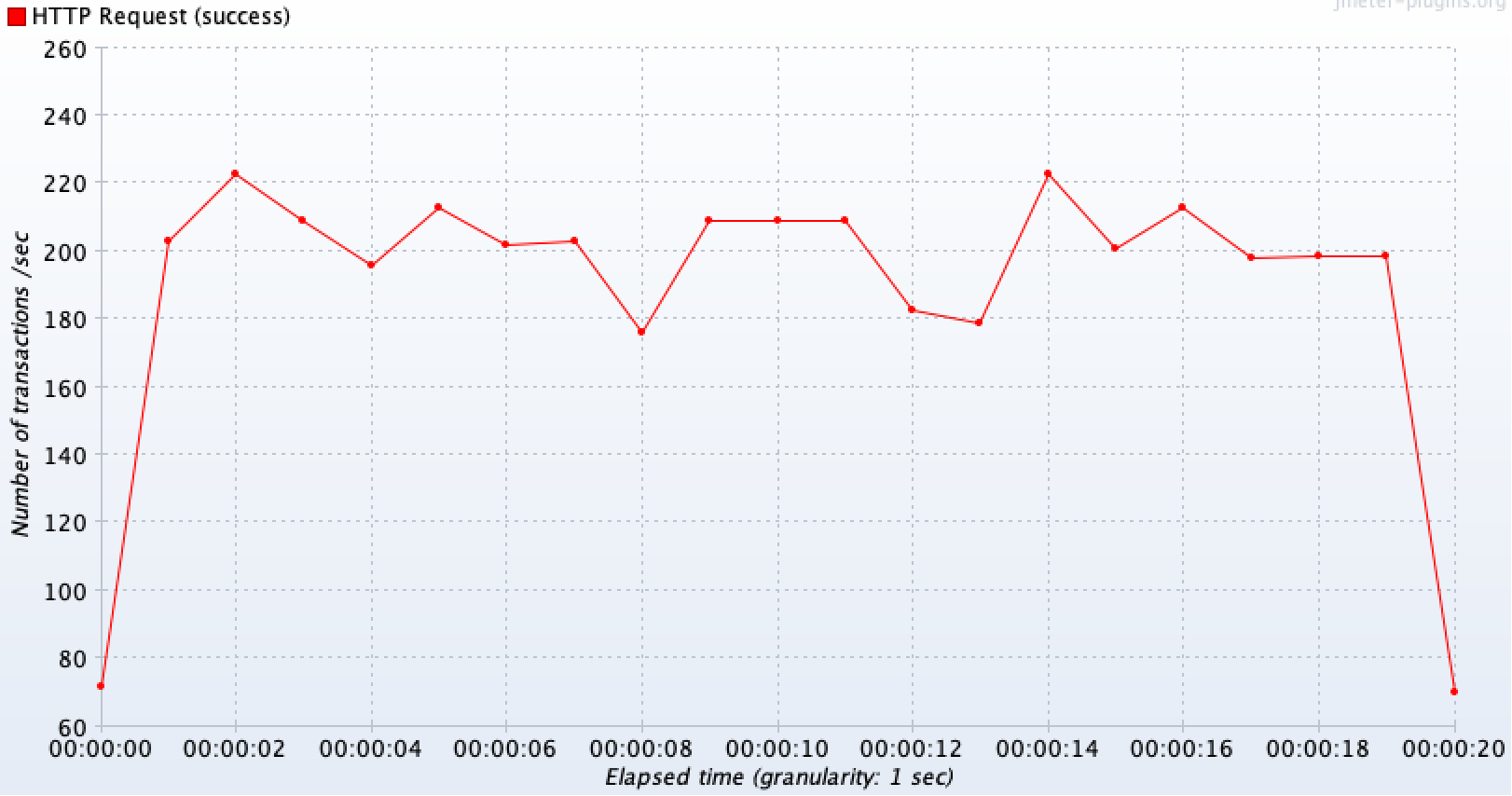 | 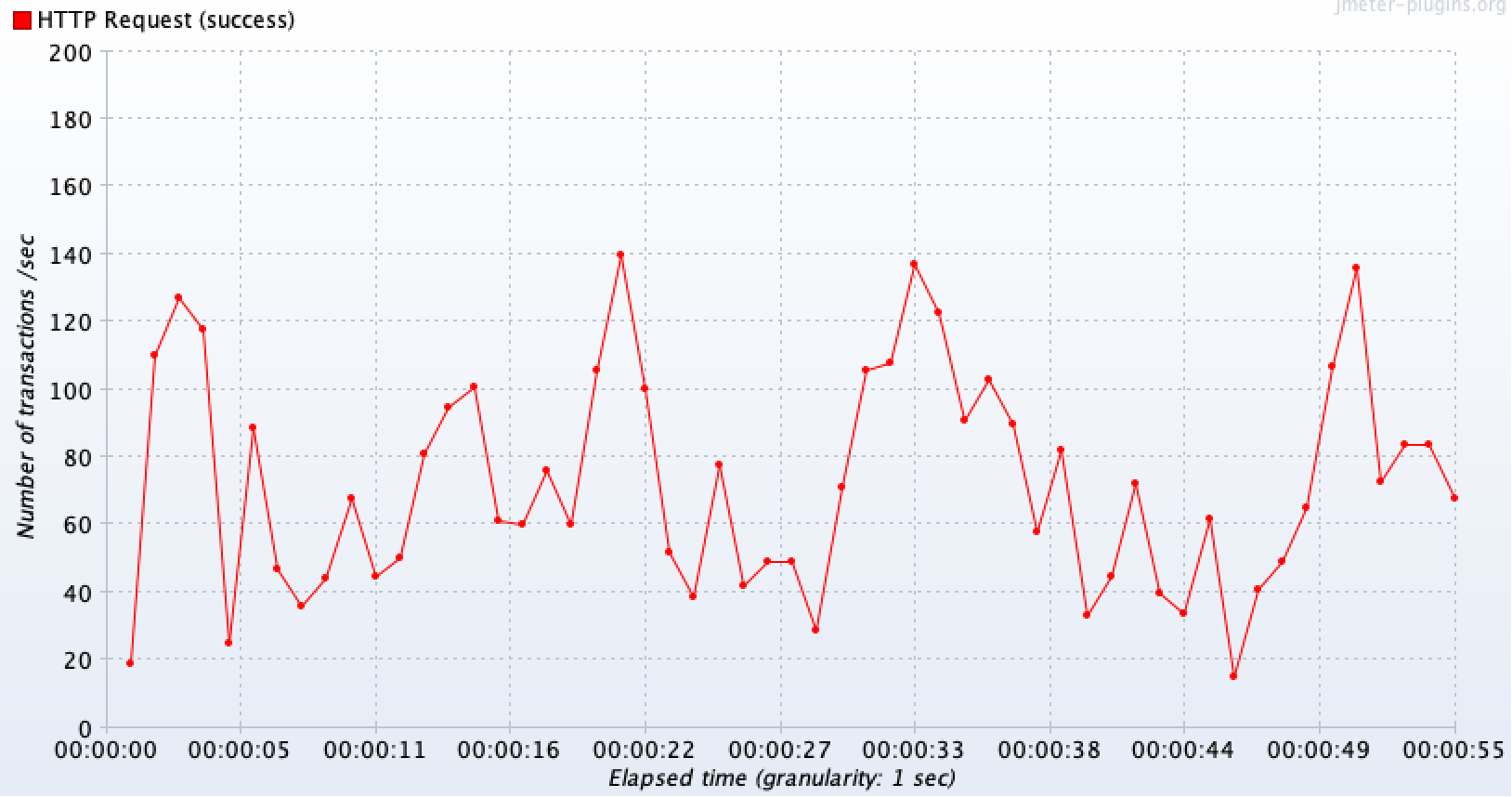 |
|---|
🔥 시나리오 2 : 외부 API 5초 지연/장애 상황
이번에는 외부 API 응답이 5초가 되는 경우를 테스트해보자. 요청은 똑같이 1초에 400개씩 총 10초간 4000개의 요청을 보내도록 했다.
1. RestTemplate 커넥션 풀 X 외부 타임아웃 설정 X
앞서서 말했듯이 아무런 설정을 해주지 않았기에, 외부 API 응답이 늦어지면 다양한 문제 상황이 발생하는 것을 볼 수 있다.
🔗 HikariPool(DB 커넥션 풀) 자원 고갈 문제 발생
우선 첫번재 문제로는 타임 아웃 시간인 30초 동안 DB 커넥션을 얻지 못하는 문제가 발생한다.
왜냐하면 외부 API 호출 이전에 DB에 값을 조회해오는 부분 때문에 커넥션이 필요하지만, 한 트랜잭션이 너무 길어지게 되면서 커넥션 풀에 빠르게 자원을 반납하지 못하게 되고, 따라서 다른 요청들이 커넥션을 얻지 못하는 상황이 나타나기 때문이다.
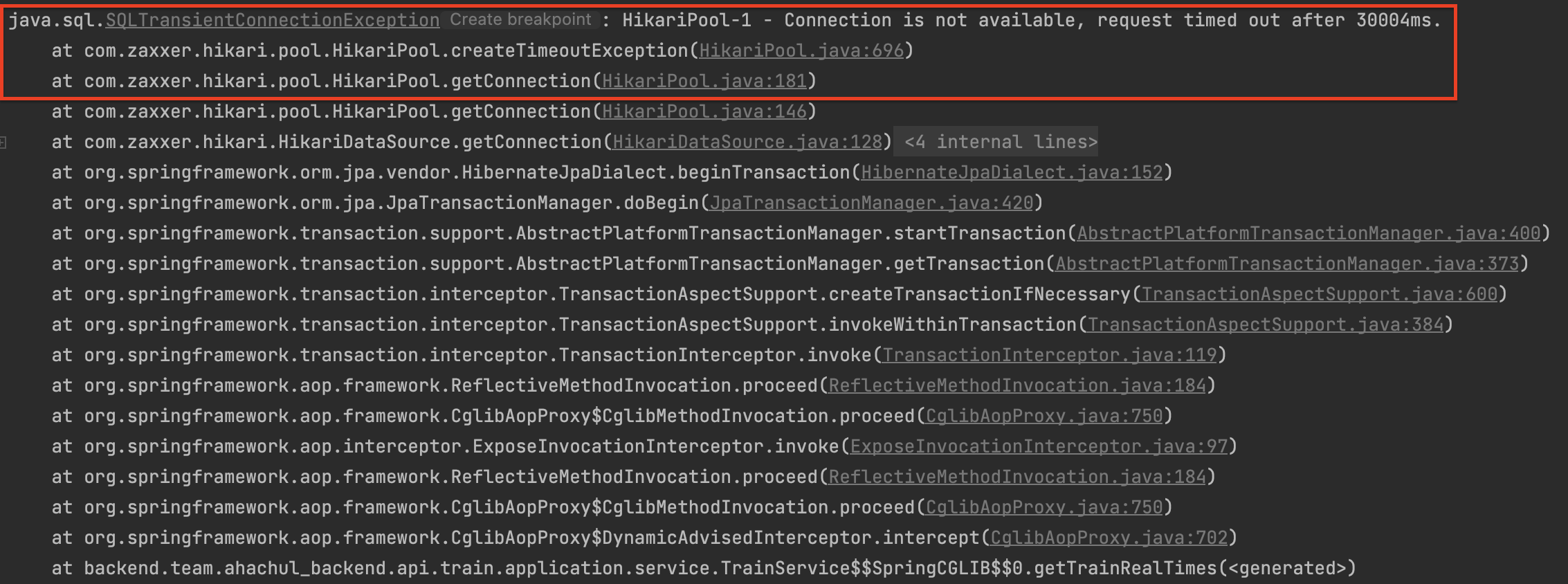
위에 테스트 결과를 참고해서 현재 서버가 평균 200TPS를 처리한다고 하면 아래와 같이 계산할 수 있는데, HikariCP의 minimumIdle 과 maximumPoolSize 기본값이 10이기 때문에 장애가 난 것으로 판단이 된다.
DB 커넥션 필요량 ≈ TPS × 커넥션 보유시간- 트랜잭션 구간이 50ms: 200 TPS × 0.05s ≈ 10개의 작은 풀로도 버틸 수 있음
- 트랜잭션 구간이 5초: 200 TPS × 5s ≈ 1,000개가 필요해 웬만한 풀(20~50)은 바로 고갈
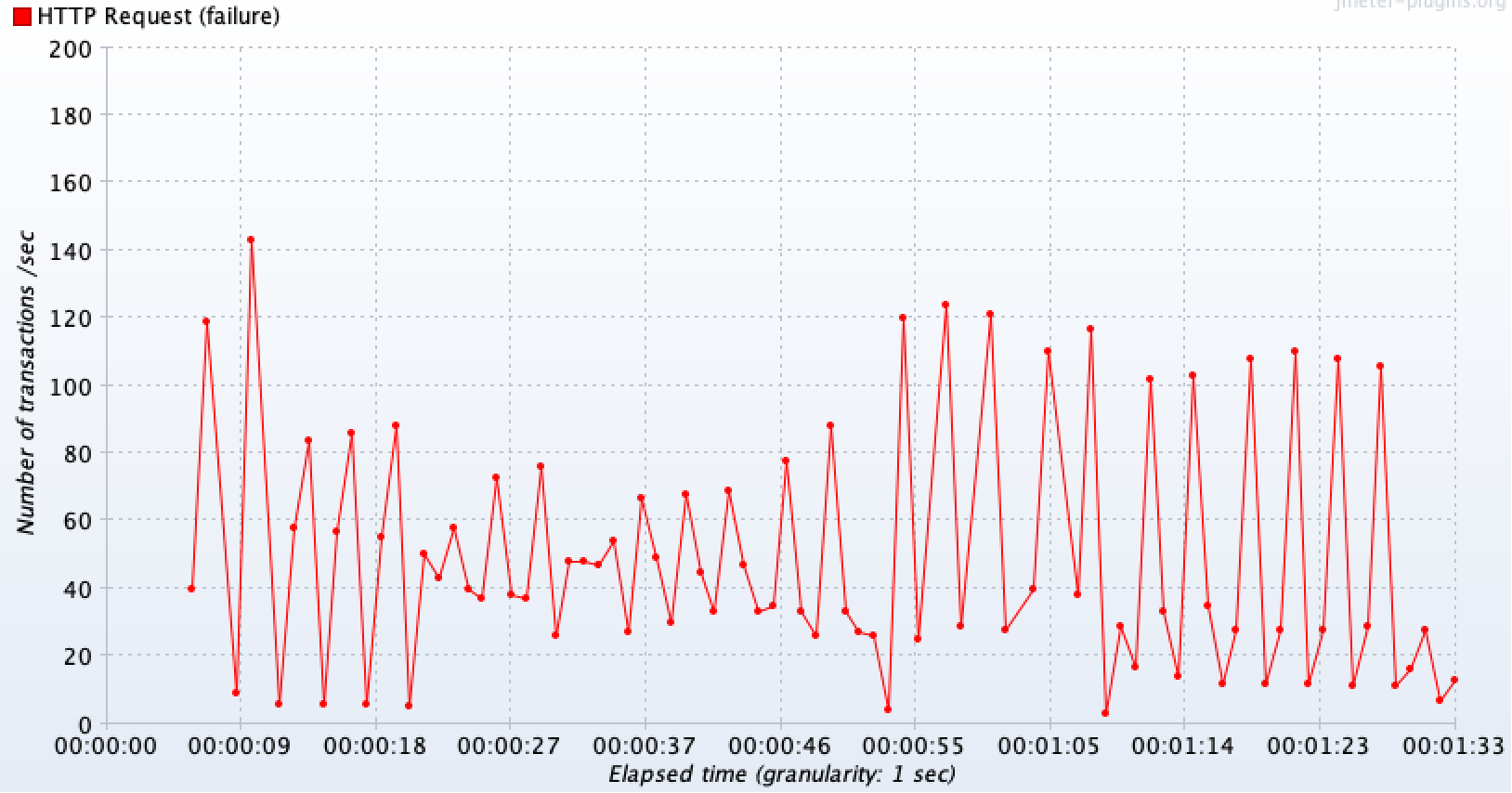
🔗 TPS가 급격히 떨어지는 문제 발생
당연히 처리량도 급격히 떨어진 것을 볼 수 있다. DB 커넥션 타임아웃으로 500 에러가 발생하면서 실패되는 요청이 30초 이후부터 급격히 발생하고 있는 것을 볼 수 있고, 정상 요청은 커넥션 풀 개수에 맞추어서 10TPS의 처리량을 보이고 있다.
-
확대본
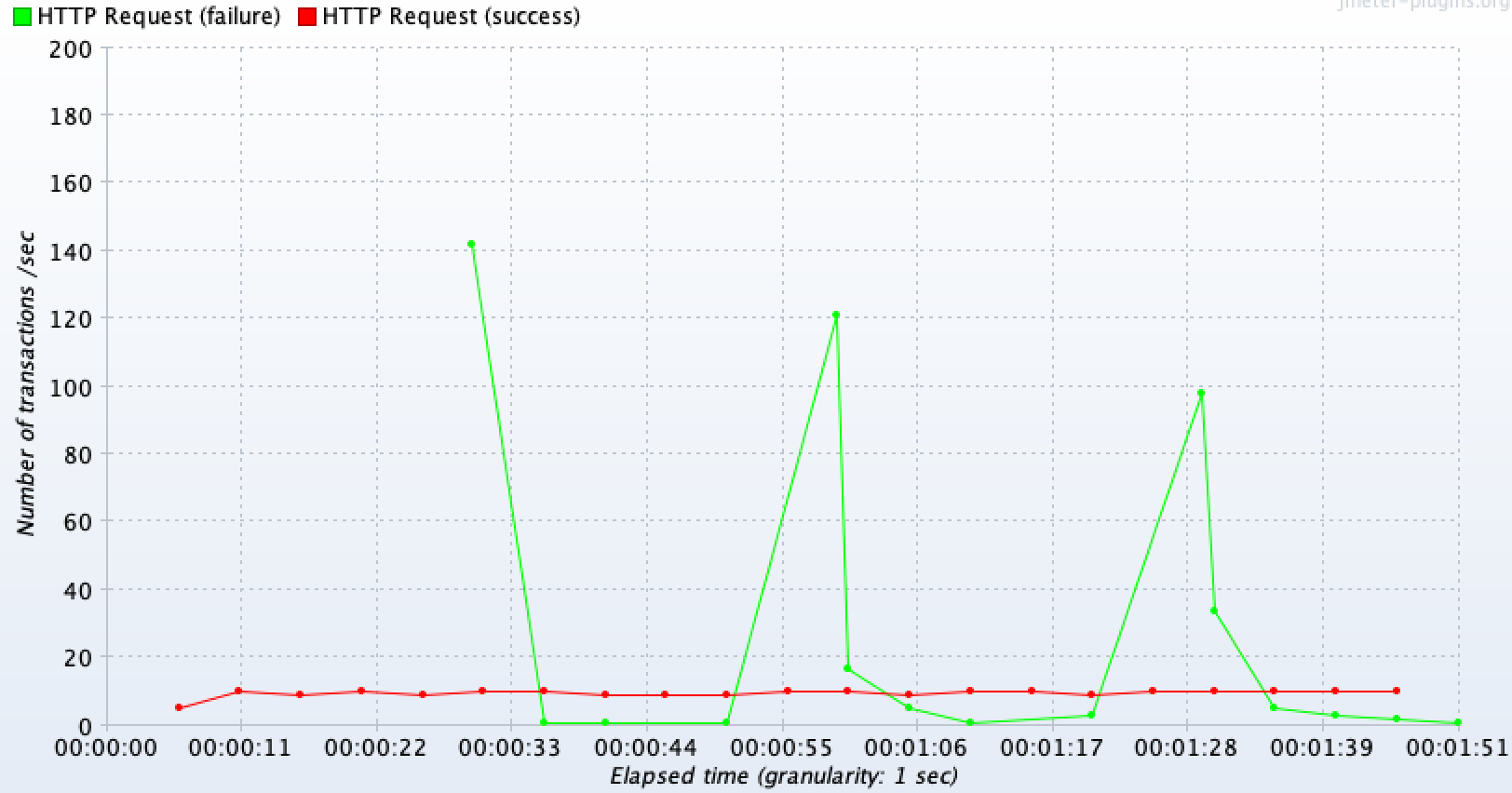
-
전체 결과본
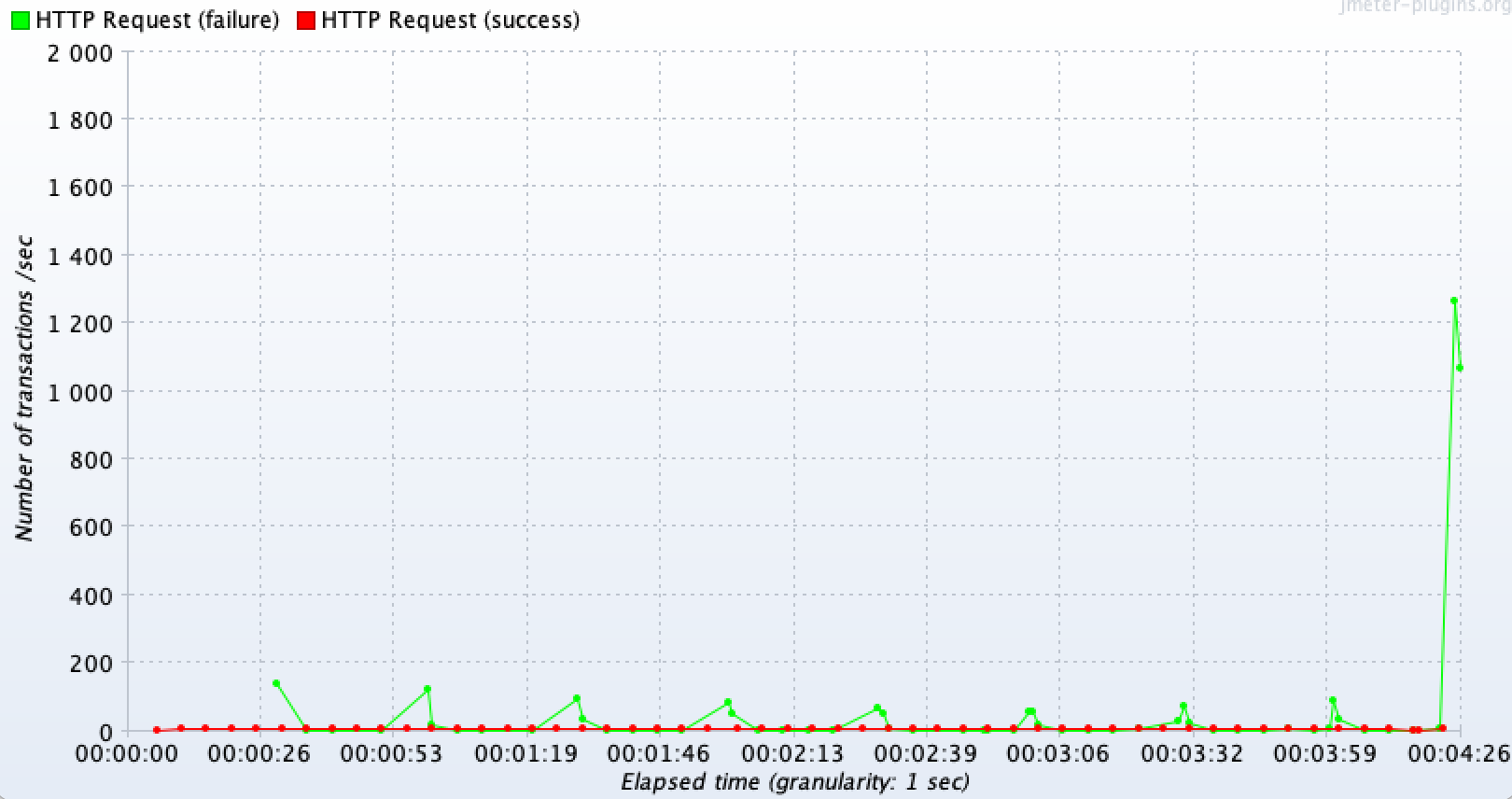
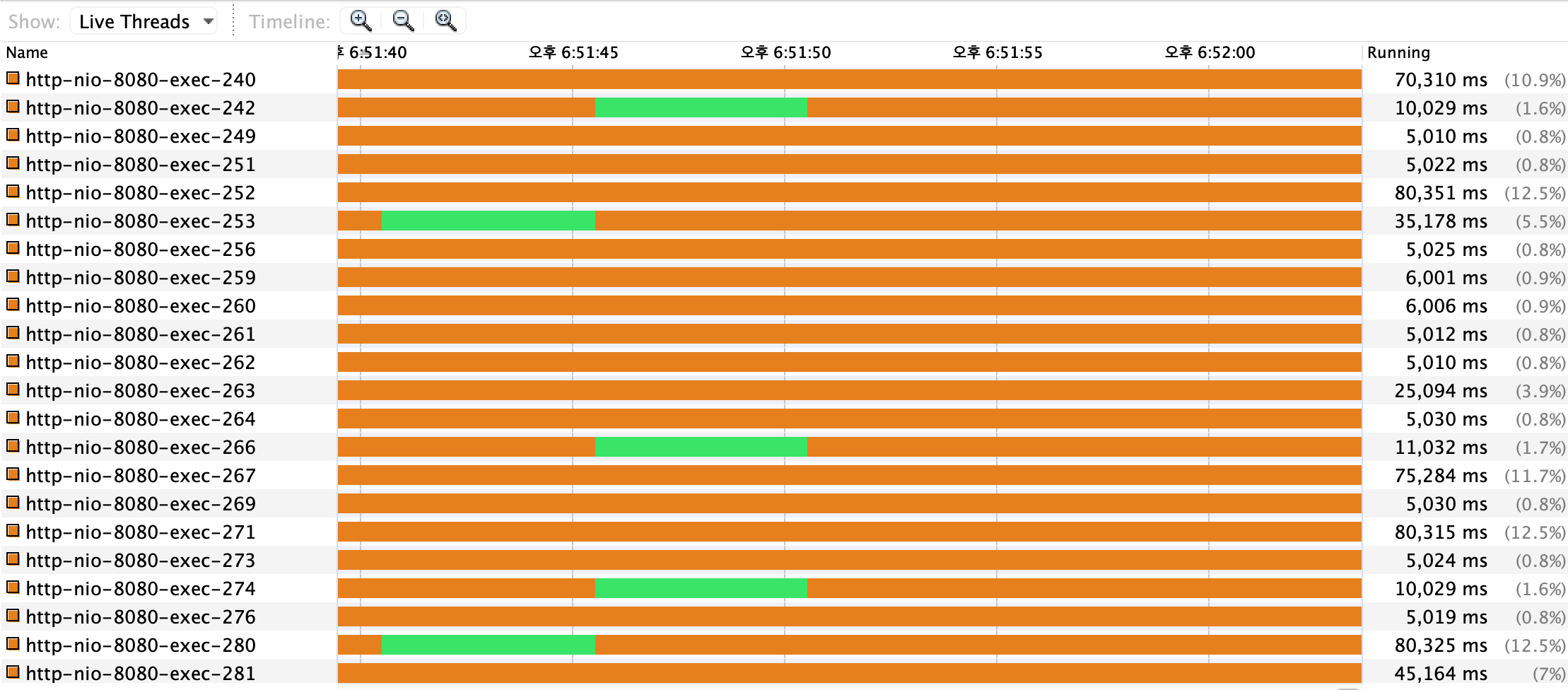
스레드
스레드는 커넥션 타임아웃에 의해 외부 API가 호출되지 않은 요청들을 제외하고는, 아래에서 볼 수 있듯이 5초 동안 Running 상태에 있는 것을 볼 수 있다.
사전 단계에서 살펴봤듯이, 스레드 덤프로 확인해보면 Blocking I/O는 JVM이 직접 wait를 건 게 아니라 OS 시스템콜 차원에서 막힌 거라서 RUNNABLE로 나오게 된다.
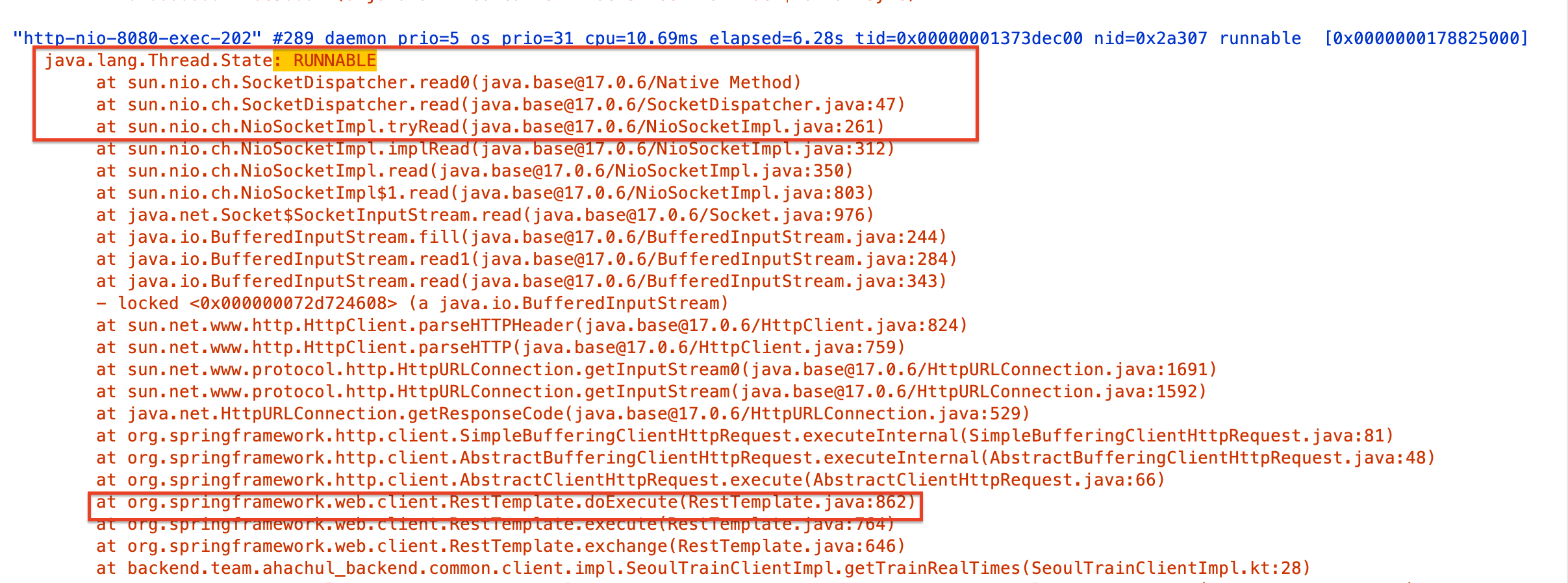
2. RestTemplate 커넥션 풀 O 외부 타임아웃 설정 O 테스트
그렇다면 이제 다시 커넥션 풀과 3초 타임아웃을 설정해주고 부하 테스트를 해보자. 더 정확한 테스트를 위해 외부 API가 호출되는 요청(blocking-test)과, 아예 관련없는 다른 기능(normal-test)도 함께 호출해주었다.
- 외부 장애 API 호출 : 10초 동안 3000
- 정상 API 호출 : 10초 동안 1000
마찬가지로 테스트 결과는 3초동안 반드시 기다려야 하므로 Connection timeout 예외가 발생하지만, 이번에는 Read time out 예외가 함께 발생하는 것을 볼 수 있다.


TPS 측정 결과
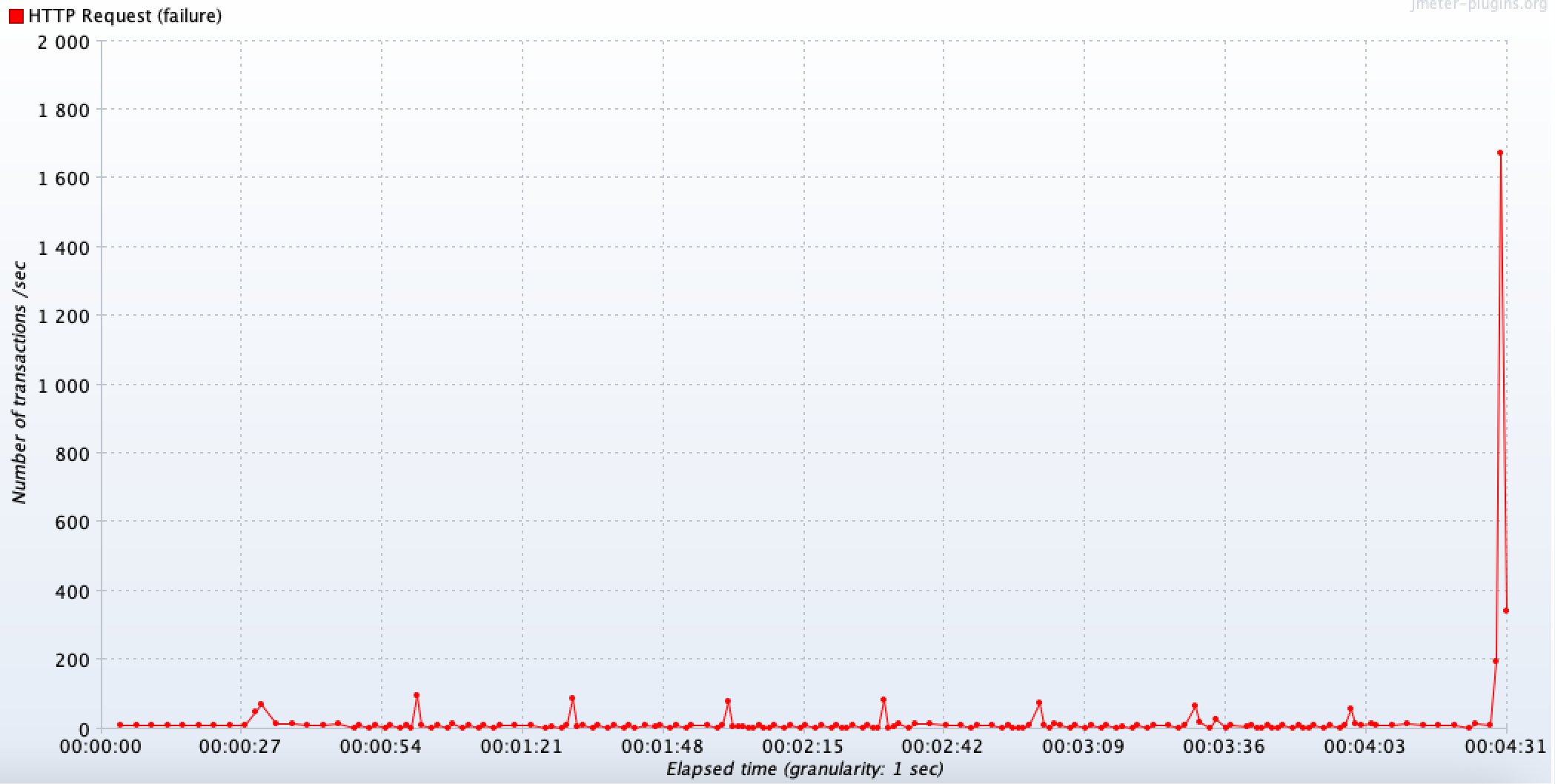
너무 오래 걸려서 중간에 중단했지만, 타임아웃이 없을 때랑 비슷한 그래프 양상을 띄며 평균적으로 10TPS 정도로 처리되고 있는 것을 볼 수 있다. 트래픽을 적게 해서 테스트해보면 아래와 같이 자세히 볼 수 있다.
-
장애 API(외부 API 호출 기능)
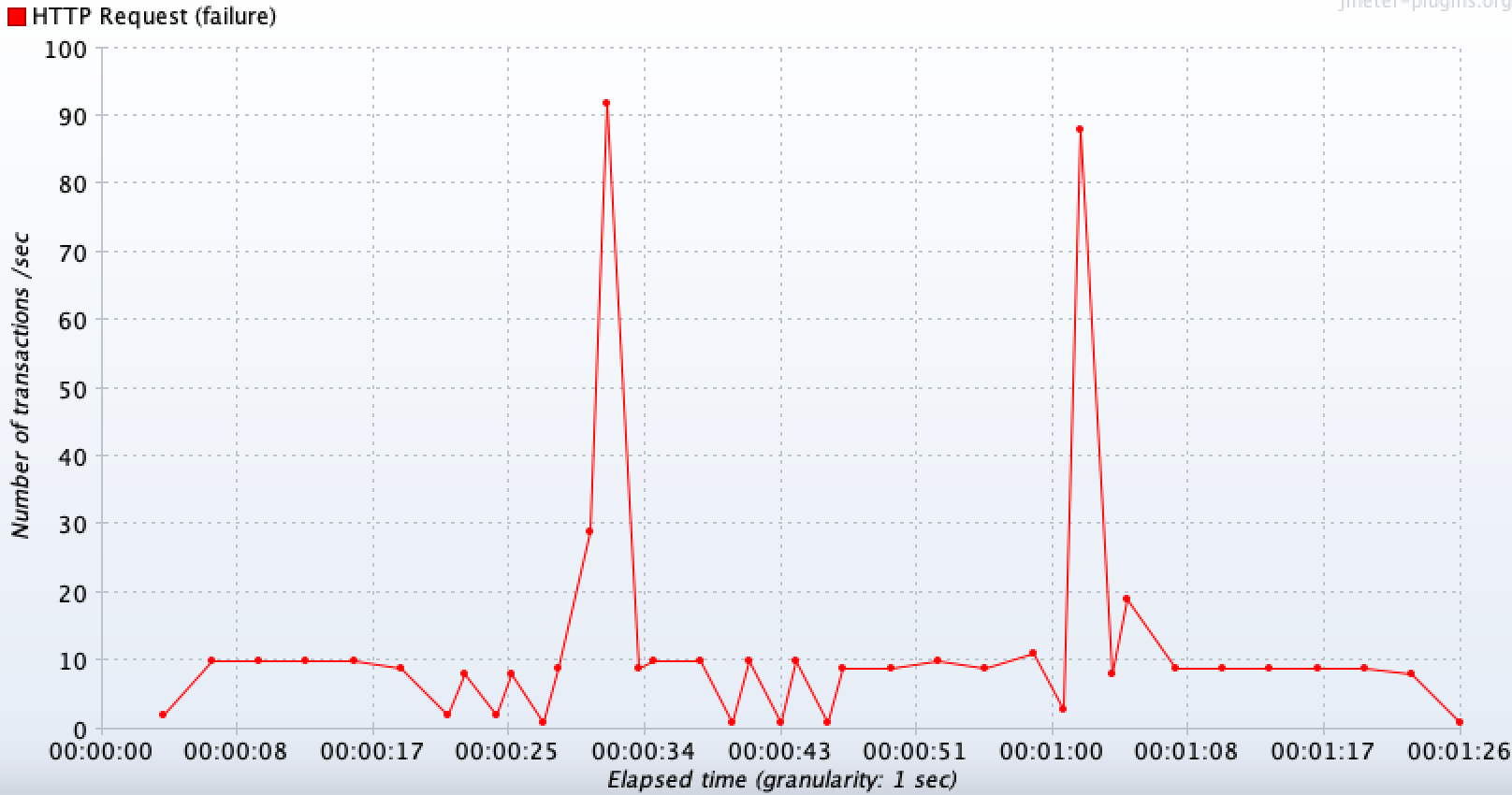
큰 스파이크가 나는 시점은 한꺼번에 30초 커넥션 타임아웃이 완료되는 순간이며, 그 직전까지는 3초 read 타임 아웃에 대한 실패 응답이 반환된다.
-
정상 API(다른 기능)
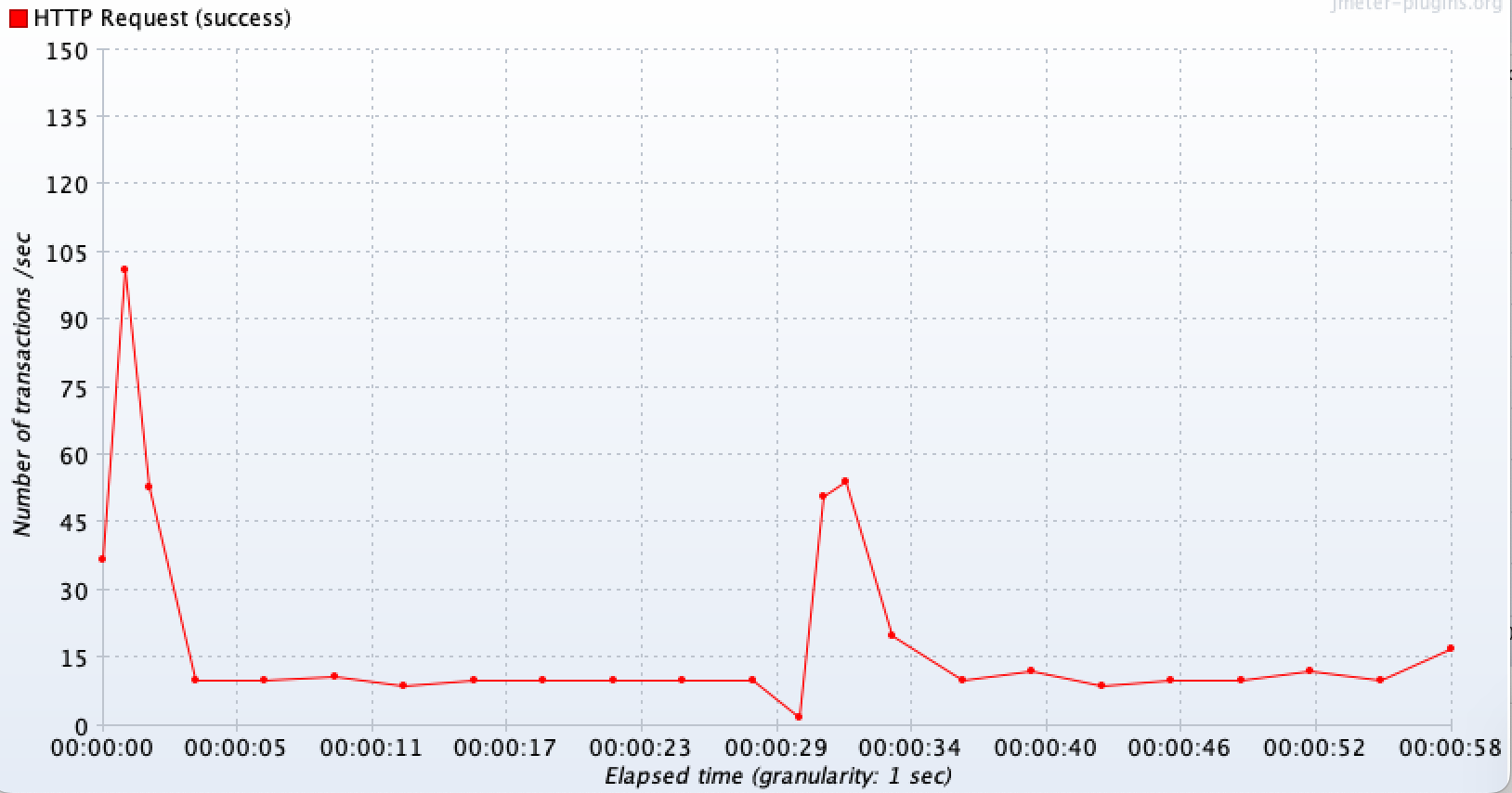
시작 직후엔 서버가 아직 여유라 TPS가 높게 치솟고, 곧 느린 API가 워커 스레드/커넥션을 대량 점유하면서 정상 요청에 대기가 발생하며 TPS가 10~15 수준으로 줄어들고, 이후 느린 쪽 API의 타임아웃이 한꺼번에 터져 스레드가 해방되는 순간에 잠깐 TPS가 회복되어 반등하는 패턴을 보인다.
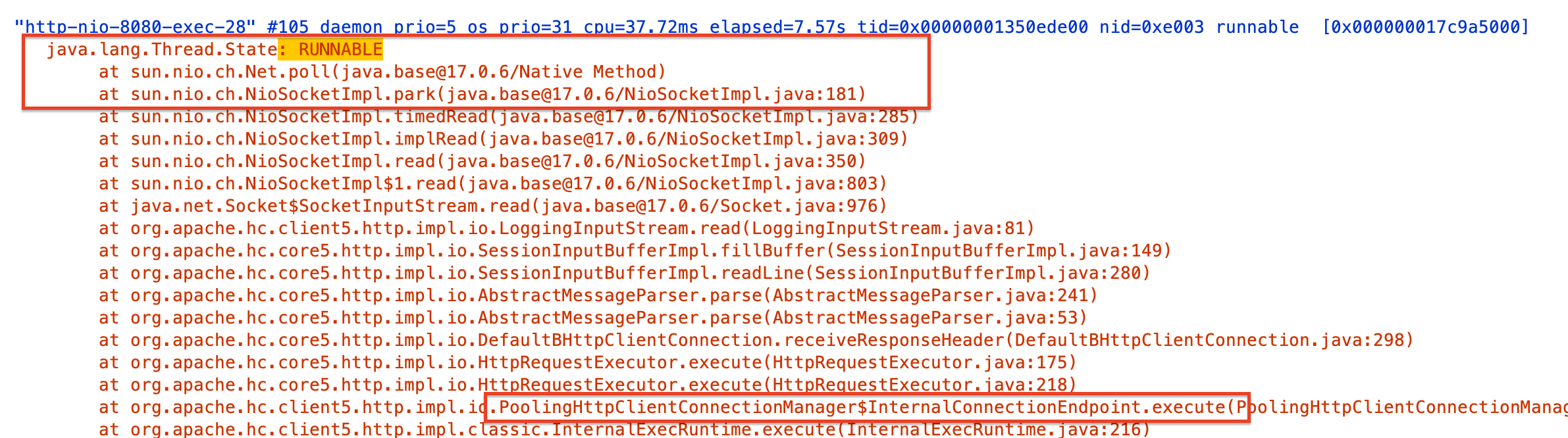
스레드 덤프 결과
스레드 상태를 확인해보면 마찬가지로 Blocking I/O로 인해 RUNNALBE 이지만, 앞과 다르게 PoolingHttpClientConnectionManager 를 사용하고 있다는 것을 볼 수 있다.
3. DB 커넥션 풀 사이즈 조정 및 트랜잭션 분리해보기
지연 상황에서 DB 커넥션 타임아웃 에러를 해결하려면 어떻게 해야할까?
TPS 향상은 어짜피 톰캣 스레드 풀에서 병목이 존재하니 효과가 없겠지만, 커넥션 timeout 에러 해결만을 놓고 본다면 hikariCP 커넥션 풀의 개수를 늘려보는 방향으로 접근해볼 수 있다.
다만 이론적으로 생각해보면 스레드가 block 되는 시간이 3초이기 때문에 몇천개 단위로 늘려야 안정적으로 감당할 수 있을 것 같아 보인다. 트랜잭션 구간이 최소 3초라고 가정하면, 아래 공식에 따라 200 TPS × 3s ≈ 600개 정도가 넉넉하게 필요할 것이다.
필요한 동시 커넥션 ≈ 목표 TPS × 평균 DB 사용시간(초)spring:
datasource:
driver-class-name: org.h2.Driver
...
hikari:
maximum-pool-size: 600 // h2 자체 max_connection X테스트 결과
실제 600개까지 과도하게 늘려보니 connection timeout 없이 정상적으로 처리가 된 것을 볼 수 있으며, 평균 처리량은 139TPS가 나온다.

Q. 하지만 커넥션 풀 사이즈를 늘리는게 항상 좋은걸까?
주의할 점이 위의 공식은 굉장히 이상적인 상황이고, 현실에서는 DB를 기준으로 안정적으로 처리 가능한 동시 쿼리 개수 만큼만 커넥션 풀을 설정해야 하는 것이 좋다.
실제 HikarCP와 PostgreSQL에서는 아래와 같은 공식을 권장하고 있다. 아래 공식은 CPU 코어수와 DB의 동시 처리 능력을 고려한 크기 설정 방식이다.
core_count * 2 + effective_spindle_countcore_count * 2: CPU 컨텍스트 스위칭으로 인한 오버헤드를 고려해도 I/O로 블로킹되는 시간에 다른 작업들을 처리할 수 있다.effective_spindle_count: 하드 디스크는 spindle을 회전시켜 요청을 처리하기에 디스크가 N개 있다면 동시에 N개의 I/O 요청을 처리할 수 있다.
// local 환경 기준
CPU 코어: 8코어 (성능 4 + 효율 4)
SSD이므로 effective_spindle_count = 1
connections = (8 * 2) + 1 = 17기본적으로 최소한으로 유지하고 있는 커넥션 개수인 minimum-idle 은 기본값이 최대로 생성 가능한 커넥션 개수인 maximum-pool-size 이다. 따라서 만약 minimum-idle 을 작게 설정하고 maximumPoolSize 를 늘리는 경우는 런타임에 커넥션을 추가로 생성하는 부분에서 오버헤드가 발생할 수 있어 고정적인 성능을 내기 힘들다.
그래서 두 설정 값을 같게 가져가되, maximum-pool-size 만 적절하게 조정해주는 것을 실제로도 권장하고 있다. 그렇기 때문에 풀 사이즈를 엄청나게 크게 잡게되면 요청이 적게 들어오고 트랜잭션이 짧은 경우 오히려 불필요하게 생성되어 있는 커넥션 자원이 낭비로 이어지고, 어짜피 DB 서버에서 처리할 수 있는 동시 커넥션 수가 존재하기 때문에 CPU 컨텍스트 스위칭으로 인한 오버헤드(CPU 부하 증가)만 발생할 수 있다.
따라서 해당 API 지연 상황에서는 적합하지 않은 방법이라고 볼 수 있다.
Q. 혹은 트랜잭션 수행 시간을 줄여서 빠르게 커넥션이 반납되도록 하면 되지 않을까?
맞다. 트랜잭션 수행 시간을 ms 까지 줄이기 위해 DB 커넥션이 필요한 부분과 외부 API 호출 부분을 아예 별도로 분리하고, JPA OSIV 설정을 끄는 방식으로도 해결할 수 있다.
기본적으로 JPA Open‑Session‑In‑View(OSIV) 설정값이 켜져 있다면 커넥션을 트랜잭션 종료가 아닌 API 응답이 종료될 때 까지 유지하고 있기 때문이다. 이렇게 되면 트랜잭션이 끝난 이후의 영역에서 지연 로딩과 같은 기능을 활용하지 못해 자칫 예외가 발생할 수 있지만, 다행히 프로젝트 전반적으로 엔티티를 서비스 계층 외부로 노출하지 않고 DTO 를 활용하고 있었기에 설정값을 쉽게 끌 수 있었다.
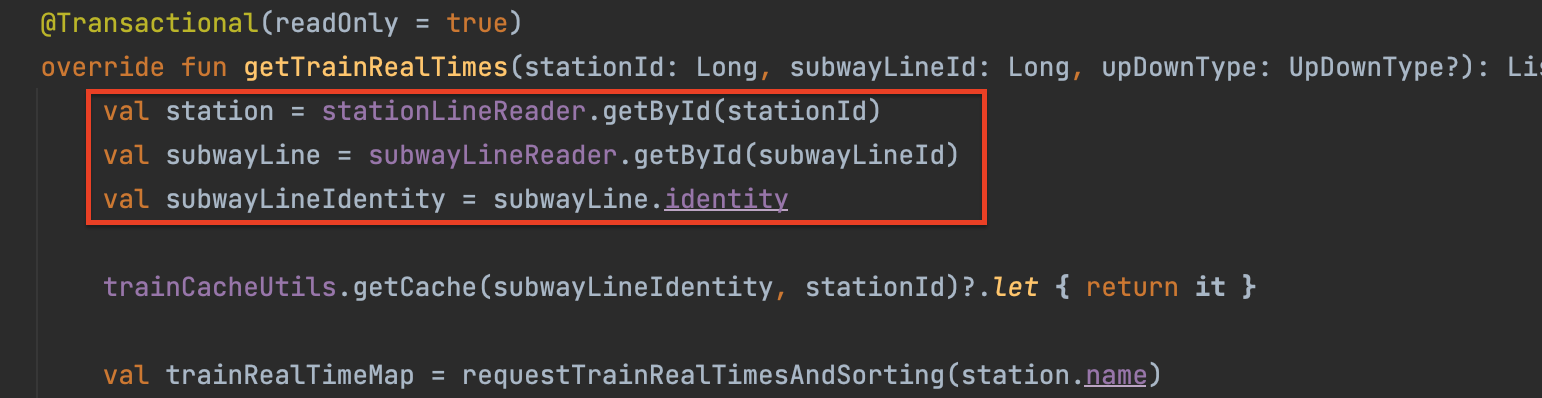
주의할 점은 @Transactional(readOnly=True) 가 동작하려면 같은 클래스에서 내부 메서드로 DB 조회 로직을 분리하면 안되고, 별도 클래스로 생성해줘야 한다. 내부로 분리하면 메서드 진입점인 getTrainRealTimes 에는 어노테이션이 없어 프록시 적용 대상이 되지 않기 때문이다.
spring:
jpa:
open-in-view: false // 프록시가 정상적으로 동작하기 위해서 별도 클래스로 분리(같은 클래스의 내부 호출은 프록시 적용 불가)
@Service
class TrainReadTxService(
private val stationLineReader: StationLineReader,
private val subwayLineReader: SubwayLineReader,
) {
@Transactional(readOnly = true)
fun fetchStationAndLine(stationId: Long, subwayLineId: Long): Pair<String, Long> {
val station = stationLineReader.getById(stationId)
val line = subwayLineReader.getById(subwayLineId)
return station.name to line.identity
}
}
override fun getTrainRealTimes(stationId: Long, subwayLineId: Long, upDownType: UpDownType?): List<GetTrainRealTimesDto.TrainRealTime> {
// 여기까지가 짧은 read-only 트랜잭션 (커넥션 보유)
val (stationName, subwayLineIdentity) = readTx.fetchStationAndLine(stationId, subwayLineId)
// 트랜잭션 종료 → 커넥션 반납
...
// 이후 외부 API 호출 로직 수행
}
이렇게 분리를 하고 다시 테스트를 해보니, 풀 사이즈를 조정하지 않고도 connection timeout 에러 상황을 피할 수는 있지만 여전히 3초 타임아웃으로 인해 다른 관련 없는 요청들은 정상적인 처리량을 가질 수가 없어 서버에 장애가 전파된다.
따라서 커넥션 풀 사이즈를 늘리는 방식은 현재 상황에서는 적절한 해결 방안은 되지 않는다고 생각해 기가했고, DB 트랜잭션과 외부 API 요청을 분리하는 것이 가능한 경우는 떨어트리는게 필요하다 생각되어 2번 방안만 채택했다.
4. 장애 전파를 위한 서킷 브레이커를 도입해보기
그렇다면 결국 DB Connection timeout을 해결하려면 아예 장애 상황에서 요청 자체를 차단하는 기술이 필요해진다. 가장 대표적인 방법인 서킷 브레이커를 도입해보자.
resilience4j 라이브러리를 활용해서 간단하게 적용을 해보자.
@CircuitBreaker(name = CUSTOM_CIRCUIT_BREAKER, fallbackMethod = "fallbackOnExternalTrainApiGet")
override fun getTrainRealTimes(stationId: Long, subwayLineId: Long, upDownType: UpDownType?): List<GetTrainRealTimesDto.TrainRealTime> {
...
} fun fallbackOnExternalTrainApiGet(
stationId: Long, subwayLineId: Long, upDownType: UpDownType?, e: Exception
): List<GetTrainRealTimesDto.TrainRealTime> {
when (e) {
// 200 반환(원래 400, 그래프에서 fallback 메서드 구별 위해 변경)
is CallNotPermittedException -> {
logger.error("circuit breaker opened for external train api")
throw CommonException(ResponseCode.FAILED_TO_GET_TRAIN_INFO, e)
}
else -> {
// 500 반환
throw CommonException(ResponseCode.INTERNAL_SERVER_ERROR, e)
}
}
}사전 준비 단계에서 언급했듯이, 서킷이 정상적으로 OPEN 되기까지 불필요하게 호출되는 API를 최대한 줄여야하기 때문에 위와 세팅 값을 변경해보았다.
- 부하는
20초동안 총1000개요청을 점진적으로 보내도록 했다. - 서킷 브레이커 설정 값들도 빠르게 OPEN될 수 있도록 조금씩 변경해주었다.
resilience4j:
circuit-breaker:
failure-rate-threshold: 10 # 실패율 10 % 이상 시 서킷 오픈
slow-call-duration-threshold: 1000 # 1000ms 이상 소요 시 실패로 간주
slow-call-rate-threshold: 10 # slowCallDurationThreshold 초과 비율이 10% 이상 시 서킷 오픈
wait-duration-in-open-state: 30000 # OPEN -> HALF-OPEN 전환 전 기다리는 시간
minimum-number-of-calls: 50 # 집계에 필요한 최소 호출 수
sliding-window-size: 50 # 서킷 CLOSE 상태에서 윈도우 사이즈 만큼 호출 도달 시 failureRateThreshold 실패 비율 계산
permitted-number-of-calls-in-half-open-state: 10 # HALFOPEN -> CLOSE or OPEN 으로 판단하기 위해 호출 횟수
TPS 결과본
-
장애 API(외부 API 호출 기능)
초반에 OPEN되기 이전에 빠르게 호출된 API 들은 모두 500에러가 발생하고, 이후 요청부터는 서킷이 OPEN됨으로 인해 외부 API 호출이 나가지 않으며 50TPS 처리량을 가지고 fallback 메서드가 정상적으로 수행되고 있는 것을 볼 수 있다.
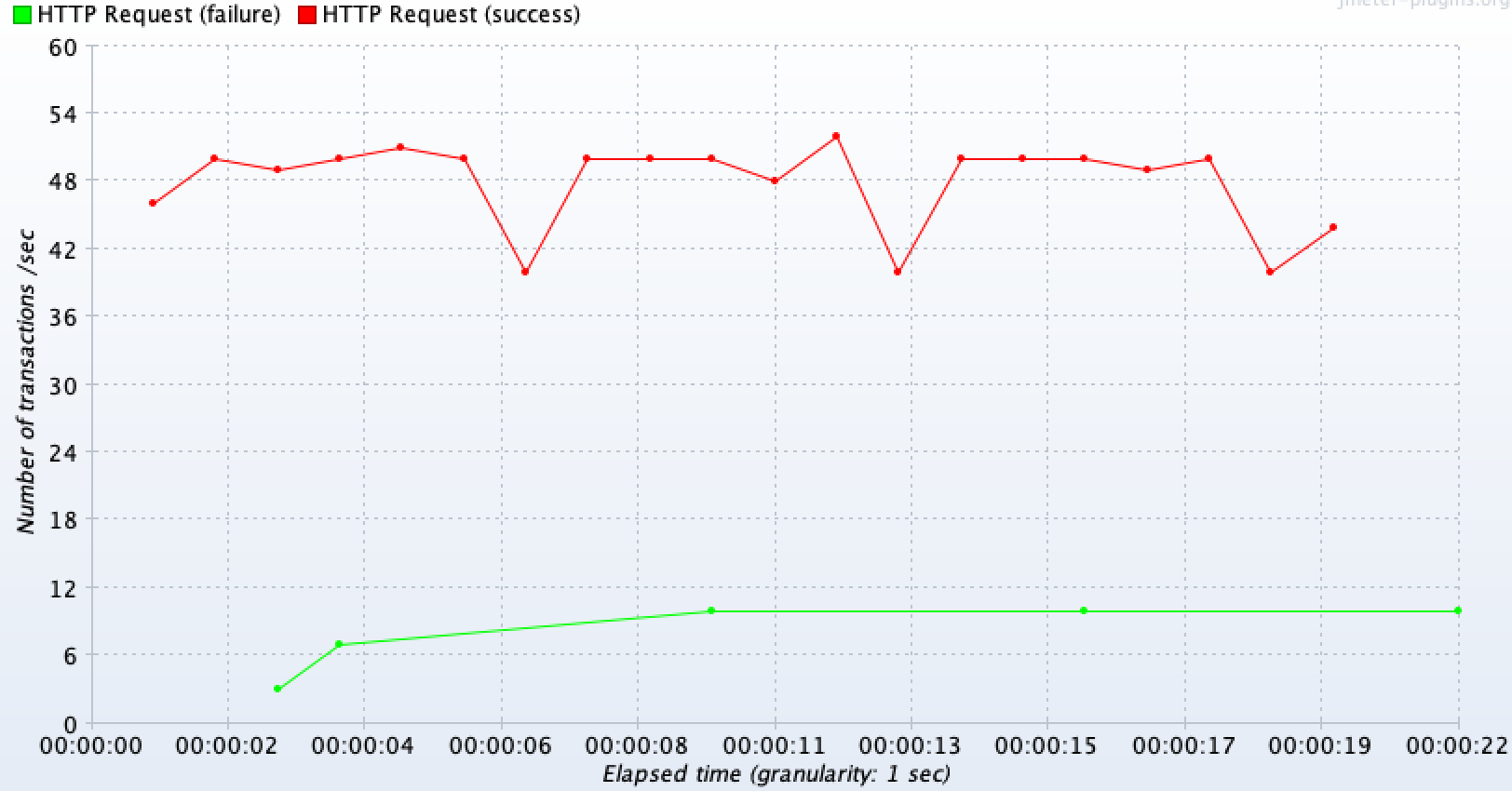
-
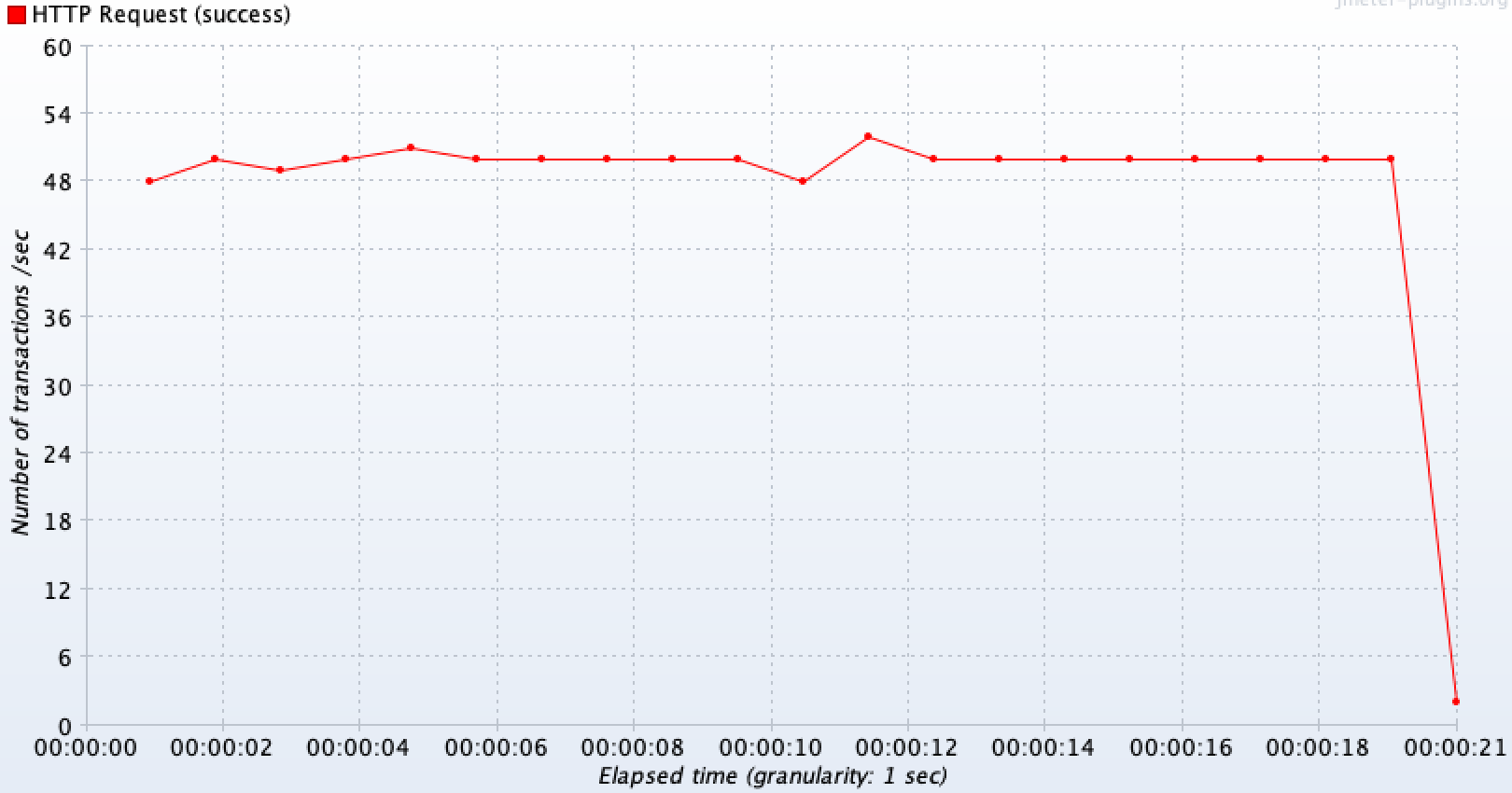
정상 API(다른 기능)
다른 정상 요청쪽도
50TPS로 들어온 요청을 모두 안정적으로 처리하고 있는 것을 볼 수 있다.
만약 위와 동일한 테스트 환경에서 다시 서킷 브레이커를 제거하면?
-
장애 API(외부 API 호출 기능) : RestTemplate 커넥션 풀 O 외부 타임아웃 설정 테스트와 비슷한 양상을 보인다.
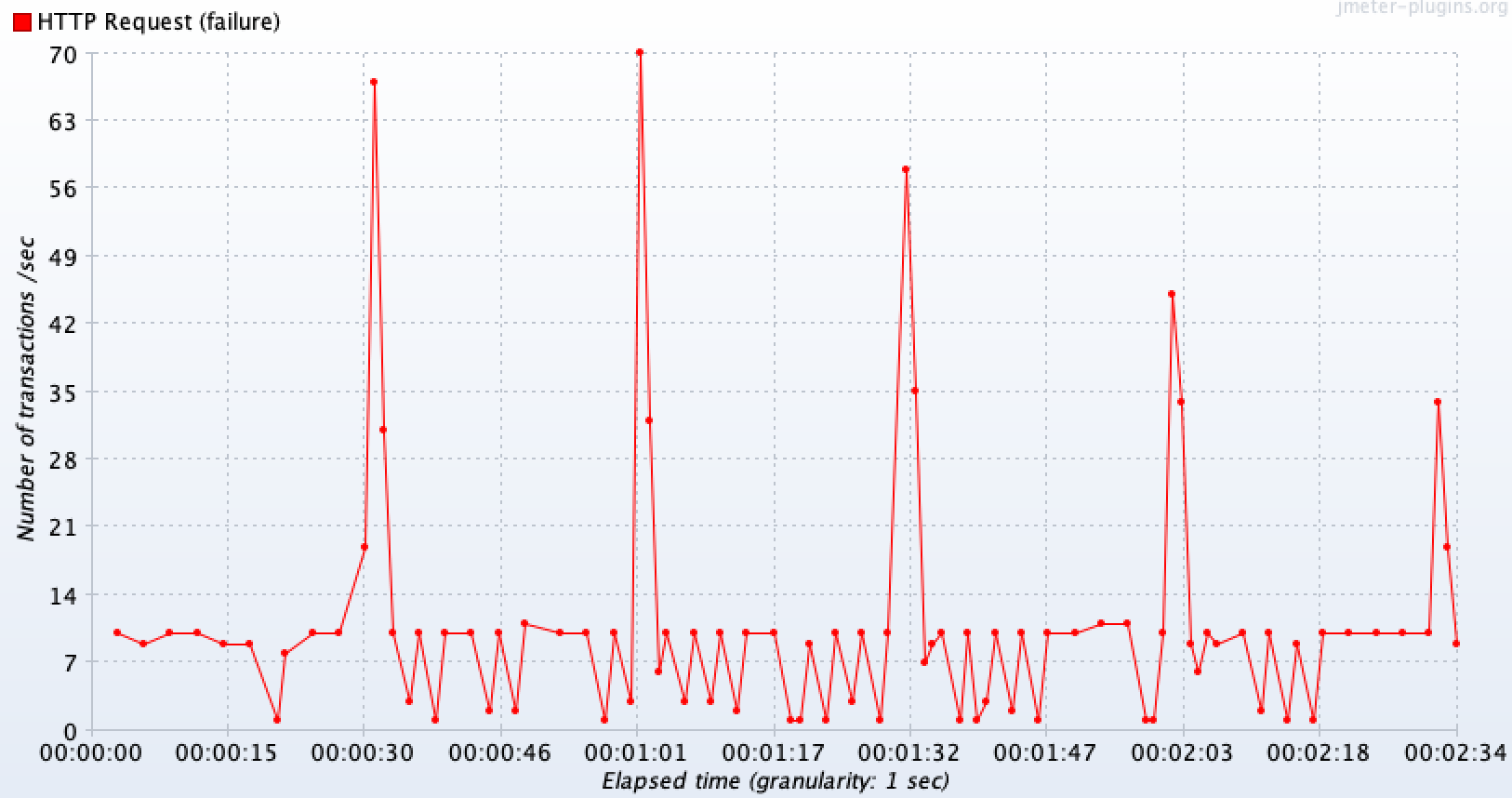
-
정상 API(다른 기능) : 대기 상태에 있을 때는 10TPS, 그게 아니라면 약 60TPS 정도 처리할 수 있다. 평균은 15TPS 정도 된다.
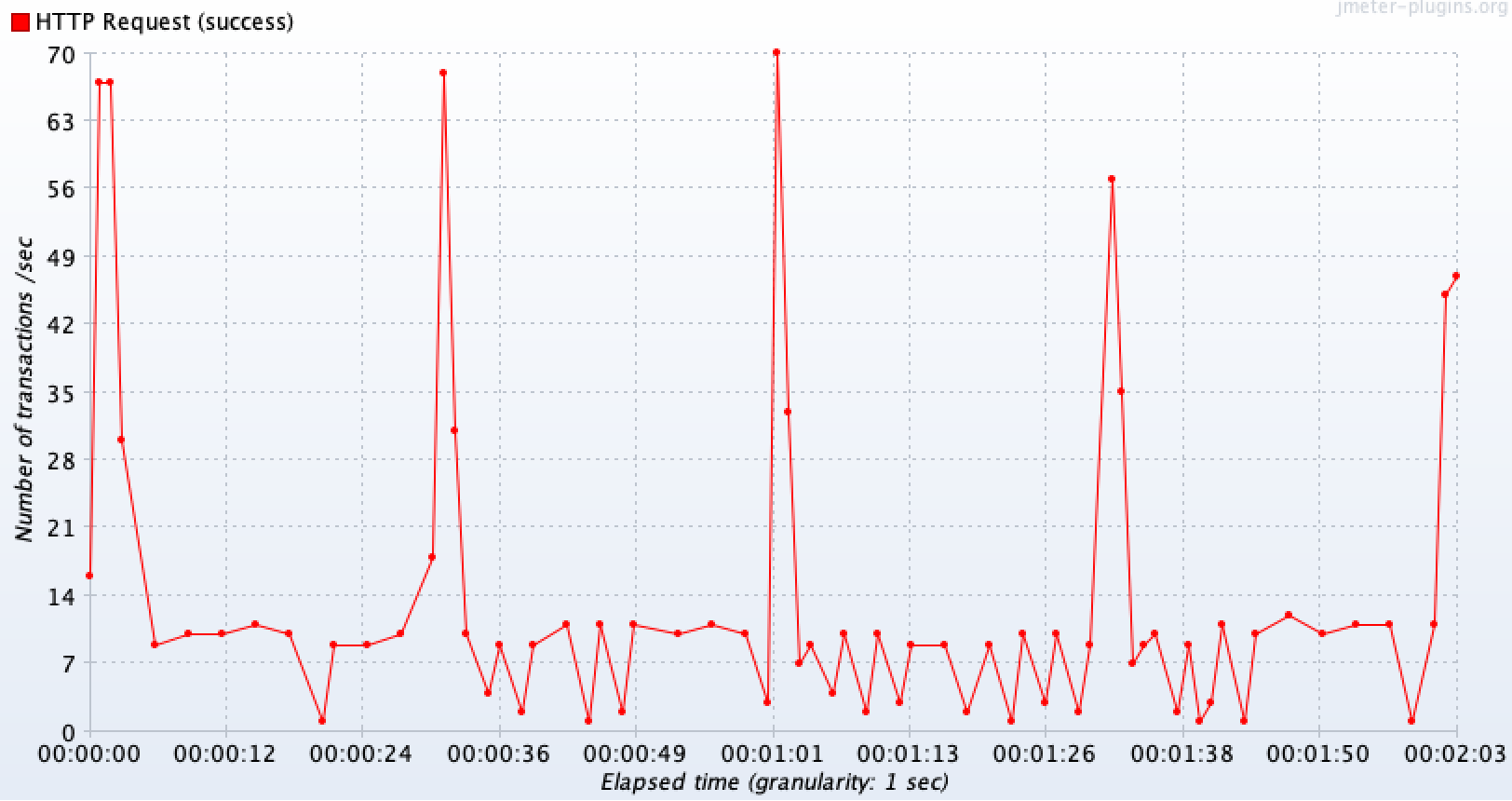
이처럼 테스트를 통해 서킷 브레이커가 외부 장애 상황에서 메서드 호출 자체를 차단함으로써 , 스레드가 고갈이 되는 문제를 방지해 관련이 없는 다른 요청들까지 TPS가 떨어지는 것을 막아준다는 역할을 하는 것을 확인해볼 수 있었다. 만약 MSA 환경이라면 각 모듈간에 장애가 전파가 되는 것을 막을 수 있어 더욱 그 효과를 발휘할 수 있을 것이다.
☁️ 테스트 결론
-
RestTemplate를 사용해 외부 API를 호출하는 로직의 핵심 병목은 Blocking I/O이기 때문에, WebClient(Non-Blocking I/O)를 도입할 수 있는 상황이라면 우선적으로 고려하자.
-
그러지 못한 상황이라면 RestTemplate은 커넥션 풀과 타임아웃을 무조건 설정해주자.
-
또한 지연과 같은 장애 상황에 대응하기 위해서는, DB 커넥션 풀 사이즈나 톰캣 스레드 사이즈를 증가시키는 것보다 서킷 브레이커를 도입하는게 적절한 선택이 될 수 있다.
(추가) Non-Blocking I/O 검토 및 도입하지 않은 이유
https://velog.io/@semi-cloud/Spring-Spring-MVC%EC%97%90%EC%84%9C-Webclient%EC%9D%98-%ED%9A%A8%EA%B3%BC%EB%A5%BC-%EB%B3%BC-%EC%88%98-%EC%9E%88%EC%9D%84%EA%B9%8C
참고 자료
WebClient - https://velog.io/@greentea/WebClient-%EC%82%AC%EC%9A%A9%EB%B0%A9%EB%B2%95
