
☁️ 에러 상황
마이페이지에서 공연의 자세한 정보를 빼오기 위해서는, 상세 버튼을 눌러 다른 페이지로 다시 이동해야했다. 내가 계획한 코드의 흐름은 다음과 같았다.
- 현재 페이지에서 상세 정보 페이지로 이동
- 데이터 뽑기
- 다시 돌아온 후, 다음 행으로 넘어가 전체 행에 대해 똑같은 일 반복

...
#마이페이지에서 표 데이터 모두 가져오기
ticket_list = driver1.find_elements(By.CLASS_NAME, "reserve table tbody")[0] #tr 여러개..?
ticket_rows = ticket_list.find_elements(By.CSS_SELECTOR, "tr") #td 여러개
#0:예메일, 3:관람일, 6:상세정보 링크
for idx, ticket in enumerate(ticket_rows): #list 형태
if idx == 0 : #첫번째 row 제외
continue
data = ticket.find_elements(By.CSS_SELECTOR, "td")
#예매 날짜
print(f"예매 날짜 : {data[0].text}")
#공연 상세 정보 페이지로 이동
data[6].find_element(By.TAG_NAME, "a").click()
#관람일시(공연 날짜와 시간)
play_date = driver1.find_element(By.ID, "divPlayDate")
print(f"관람 일시 : {play_date.text}")
#공연명
subject = driver1.find_element(By.XPATH, "//*[@id='Con_M']/div/div[2]/div[1]/div[1]")
play_title = subject.find_element(By.CLASS_NAME, "title").text
print(f"공연 제목 : {play_title}")
#포스터 url
img = driver1.find_element(By.CLASS_NAME, "post")
img_url = img.find_element(By.CSS_SELECTOR, "a img").get_attribute("src")
print(f"포스터 url : {img_url}")
#공연장
place = driver1.find_element(By.XPATH, "//*[@id='Con_M']/div/div[2]/div[1]/div[2]/div[2]/table/tbody/tr[4]/td")
play_place = place.find_element(By.CSS_SELECTOR, "a ").text
print(f"공연장 : {play_place}")
print('-'*50)
driver1.back() #이전 페이지로 돌아오기
time.sleep(2)하지만 다음과 같은 에러가 발생하였다. 대충 해석해보면, 요소가 html 문서에 없는데 그걸 긁으려 시도해서 에러를 보내는것 같았다.
selenium.common.exceptions.StaleElementReferenceException: Message: stale element reference: element is not attached to the page document
(Session info: chrome=99.0.4844.51)
왜냐하면, 미리 목록을 ticket_rows 에 뽑아놓고 상세정보 페이지로 이동해서 데이터를 뽑고 다시 돌아온다해도, 뒤로 가기는 이전 상태가 아니라 주소로 다시 접속하는 것이기 때문에 다시 데이터를 로딩하는 과정이 필요한 것이다.
따라서 기존에 뽑아놨던 ticket_rows 는 재접속 한 이상 더이상 유효하지 않게 되었는데, 거기서 반복문을 돌려서 데이터를 뽑아오려 하니 문제가 발생했던 것으로 파악이 되었다.

☁️ 문제 해결 과정 1 : 크롬 드라이버 변수 2개 생성
내가 뒤로 가기 버튼을 눌러버리면, 이전 상태로 되돌아가는 것이 아니라 이전에 접속했던 주소로 다시 접속하는 것이 되기 때문에 "뒤로"를 안누르고도 수집을 계속할 수 있게 만드는 방법을 선택하였다.
크롬 드라이버 변수를 2개 만들어서, 서로 독립적으로 데이터 수집해보자.


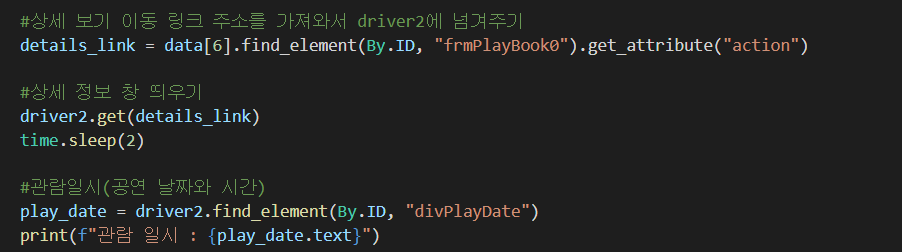
1. 로그인 보안 문제 발생
하지만 역시 우려했던 로그인 문제가 발생하였다. 다른 창에서 로그인이 필요한 마이페이지 예매 내역에 접근하는 것이기 때문에, 로그인이 필요하다고 팝업창이 떴다. (세션 유지가 끊기기 때문에)
근데 문제가 여기서 팝업창 로그인 다시 해서 뚫어도, 상세정보 페이지로 바로 가는게 아니라 다시 홈화면으로 돌아가기 때문에 하는 의미가 없어진다.
그래도 로그인에 통과해보고 싶어서, 로그인 후 쿠키를 저장해서 driver2 가 새 창을 열때 해당 쿠키를 넘겨주면 작동이 되지 않을가 생각했다.

2. Cookie Domain 에러
아래와 같이 셀레니움에서 얻은 쿠키를 drvier2 에 저장하려했는데, 다음과 같은 에러가 떴다.
selenium.common.exceptions.InvalidCookieDomainException: Message: invalid cookie domain
from copyreg import pickle
import pickle
...
#로그인 후 쿠키 가져오기
pickle.dump( driver.get_cookies() , open("cookies.dat","wb"))
# 쿠키 불러와서 새 주소에 저장
cookies = pickle.load(open('cookie.dat', 'rb'))
for cookie in cookies:
driver2.add_cookie(cookie)
# 쿠키를 저장한 상태로 페이지 요청
driver2.get(details_link)도메인이 맞지 않다는 것인데, 쿠키는 바로 도메인 베이스로 작동한다는 중요한 사실을 까멌었다. 자세히 찾아보니, 쿠키는 애초에 생성했던 브라우저의 주소로 다시 던져주는 것이 아니면 불가능하다 한다.
따라서 아래 세 주소의 도메인을 유심히 살펴보는데, 도메인이 같다. 원인을 해결하지 못해서 다른 방법을 찾아보았다.
2)https://ticket.interpark.com/Point/MyTicket/MyTicketMain.asp?&tid1=main_gnb&tid2=right_top&tid3=myticket&tid4=myticket
3)https://ticket.interpark.com/Cancel/TPDetailBooked.asp

☁️ 문제 해결 과정 2 : 초심으로 돌아가서 로직 재정의
더이상 첫번째 시도에서 삽질하지 말고, 다시 처음으로 돌아가서 반복문을 이리저리 구현해보았다.
내가 다시 생각해본 방법은 1)미리 총 데이터의 개수를 구해놓고, 2)그만큼 반복을 해서 상세정보 페이지에 접근하는데 중요한것은 이 반복문 안에 다시 데이터를 로딩하는 코드를 추가했다는 것이다.
#공연/스포츠 예매 내역
ticket_list = driver1.find_elements(By.CLASS_NAME, "reserve table tbody")[0] #tr 여러개
ticket_rows = ticket_list.find_elements(By.CSS_SELECTOR, "tr") #td 여러개(list 형태)
ticket_length = len(ticket_rows)
for idx in range(0, ticket_length):
if idx == 0:
continue
# 데이터 다시 로딩하는 과정 필요
ticket_list = driver1.find_elements(By.CLASS_NAME, "reserve table tbody")[0] #tr 여러개
ticket_rows = ticket_list.find_elements(By.CSS_SELECTOR, "tr") #td 여러개
data = ticket_rows[idx].find_elements(By.CSS_SELECTOR, "td")
#예매 날짜
print(f"예매 날짜 : {data[0].text}")
#상세 보기 이동 하기
data[6].find_element(By.TAG_NAME, "a").click()
#공연명
subject = driver1.find_element(By.XPATH, "//*[@id='Con_M']/div/div[2]/div[1]/div[1]")
play_title = subject.find_element(By.CLASS_NAME, "title").text
print(f"공연 제목 : {play_title}")
#관람일시(공연 날짜와 시간)
play_date = driver1.find_element(By.ID, "divPlayDate")
print(f"관람 일시 : {play_date.text}")
#포스터 url
img = driver1.find_element(By.CLASS_NAME, "post")
img_url = img.find_element(By.CSS_SELECTOR, "a img").get_attribute("src")
print(f"포스터 url : {img_url}")
#공연장
places = driver1.find_elements(By.CSS_SELECTOR, "tr")
for place in places:
if place.find_element(By.CSS_SELECTOR, "th").text == "장소":
break
play_place = place.find_element(By.CSS_SELECTOR, "a").text
print(f"공연장 : {play_place}")
print("-"*50)
driver1.back() #이전 페이지로 돌아가 다시 주소로 접속
time.sleep(2)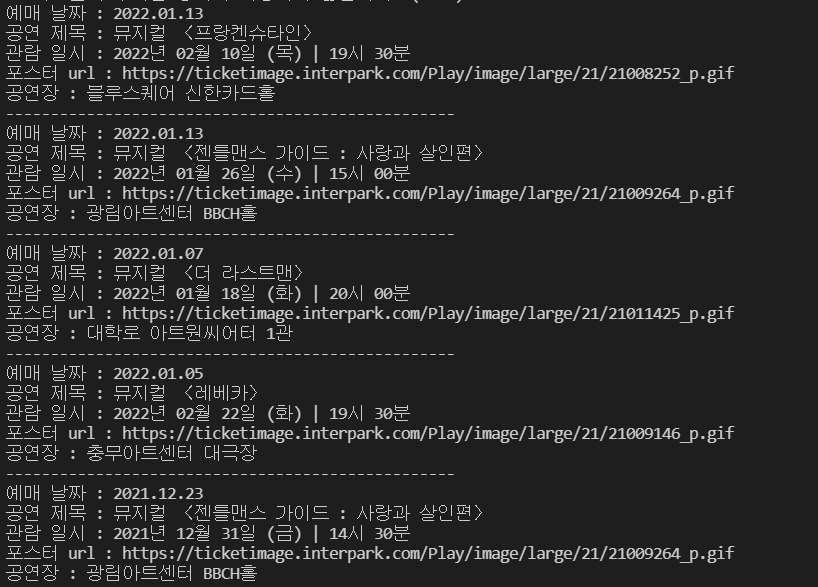
드디어 성공하였다! 하지만..이 5개의 공연 정보를 가져오는데 너무 오랜 시간이 걸렸다. 따라서 다음 포스트에서는 직접 시간 측정을 해보고 셀레니움의 성능을 향상시키는 방법에 대해서 알아볼 것이다.
