
📍 집계 함수의 윈도우 함수로의 사용
✔️ 윈도우 함수
- SQL에서 데이터를 그룹화하지 않고도 집계와 분석 작업을 수행할 수 있게 해주는 기능
OVER절을 통해 윈도우(계산 범위)를 정의하며, 각 행에 대해 계산된 결과를 반환- 기본적으로 데이터가 사라지지 않고, 각 행마다 결과가 추가
PARTITION BY를 통해 그룹화 진행, 그룹화하여도GROUP BY와 달리 원본 행 유지ORDER BY를 통해 정렬, 정렬시 현재 행까지의 계산을 점진적으로 누적하며 집계ROW/RANGE BETWEEN을 통해 계산 범위(윈도우 범위) 지정
OVER (
[PARTITION BY 컬럼명] -- 그룹화 (선택)
[ORDER BY 컬럼명] -- 정렬 (선택)
[ROW/RANGE BETWEEN] -- 윈도우 범위 지정 (선택)
)✔️ 윈도우 함수로의 집계 함수
- 집계 함수 (
SUM,COUNT,MAX,MIN,AVG등)을OVER절과 함께 사용하여 기존 데이터를 유지하며 집계 - 사용 예시
- 누적합(
sum) / 누적평균(avg) - 순위 계산(
rank,dense_rank,row_number) - 이동 통계(
avg) - 그룹 내 비율
- 누적합(
- 예제
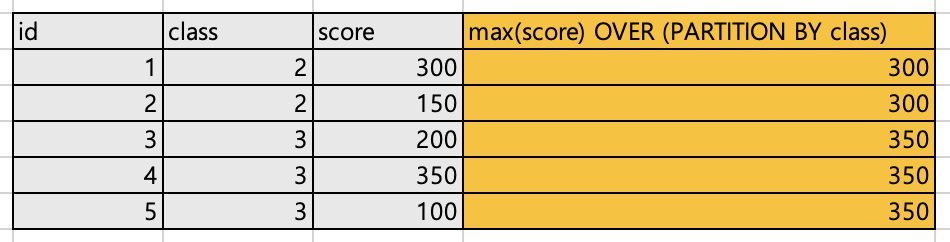
다음 예제를 통해 자세히 알아보자.class별 최대score
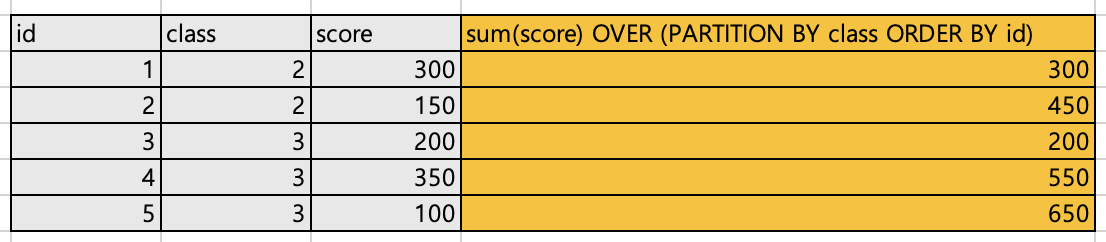
class별id순socre의 누적합
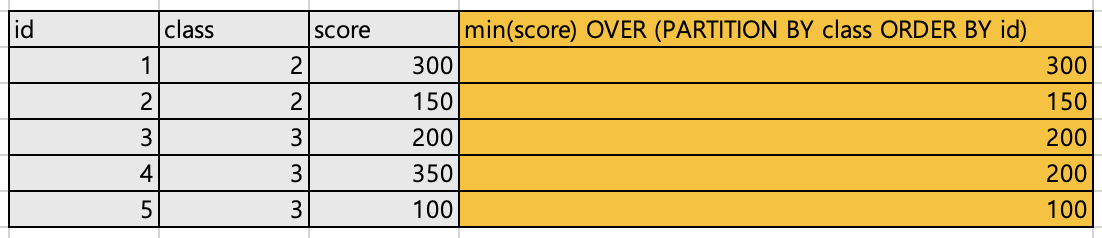
class별id순score의 최솟값
문제 흐름
서브 카테고리 별 매출액을 계산하고 그 매출액이 각 서브 카테고리가 속해있는 카테고리 안에서 비중을 얼마나 차지하는지, 그리고 전체 매출액에서는 비중을 얼마나 차지하는지 계산하는 쿼리를 작성해주세요.
➡️ 계산, 추출 내용
집계 함수 sum을 OVER를 붙여 윈도우 함수로 사용하여 각 partition column을 설정하고 집계한다.
이 때, 윈도우 함수로 사용했기 때문에 GROUP BY와 달리 레코드가 그대로 유지되어 중복 레코드가 다수 발생하게 된다.
이 다수의 중복 레코드는 다시 GROUP BY를 통해 정리할 수 있다.
다만, 윈도우 함수를 사용한 쿼리에 그대로 GROUP BY를 함께 적용하면 계산이 틀어지게 된다.
따라서 이를 방지하기 위해 sum을 집계한 내용을 CTE calc로 따로 빼고,(서브쿼리로 넣어도 좋다.)
이 calc로부터 다시 모든 컬럼을 선택하여 추출하되,
GROUP BY를 적용시켜 중복 레코드를 정리하도록 했다.
모든 수치 데이터는 소수점 아래 셋째 자리에서 반올림 해 둘째 자리까지 표현해주세요.
➡️ 수치 데이터 포맷
category와 sub_category를 제외한 모든 컬럼에 round 함수를 사용하여 소숫점 2자리까지 나타내도록 한다.
코드
WITH
calc as (
SELECT
category,
sub_category,
round(
sum(sales) OVER (
PARTITION BY
category,
sub_category
),
2
) sales_sub_category,
round(
sum(sales) OVER (
PARTITION BY
category
),
2
) sales_category,
round(sum(sales) OVER (), 2) sales_total,
round(
(
sum(sales) OVER (
PARTITION BY
category,
sub_category
) / sum(sales) OVER (
PARTITION BY
category
)
) * 100,
2
) pct_in_category,
round(
(
sum(sales) OVER (
PARTITION BY
category,
sub_category
) / sum(sales) OVER ()
) * 100,
2
) pct_in_total
FROM
records
)
SELECT
*
FROM
calc
GROUP BY
category,
sub_category;마무리
이렇게 긴 쿼리는 처음 짜본다...
solvesql에는 "SQL 포맷팅"이라는 기능이 제공되는데, 이를 통해 쿼리를 깔끔한 포맷으로 정리할 수 있다.
단순하게 풀이한 쿼리에 이걸 적용한 결과인데, 생각보다 꽤나 길고 익숙하지 않아서 그런지 오히려 읽기 어려운 것 같다.
그리고 쿼리문은 제법 인간의 말과 비슷하다는 느낌을 많이 받아
수평으로 길게 작성한 쿼리가 이야기하는 느낌이 들어 더 익숙했는데,
세로로 길게 늘어놓으니 제법 코드같다 .. 낯설군
그리고 집계함수의 윈도우 함수로의 사용은 어제 익힌 이후 처음 스스로 적용해봤는데,
원래 하던 대로 GROUP BY를 통해 집계했다면 정말 많은 CTE가 필요해졌을 것이다.
정말 좋은 기능인 것 같다..!
