Recursive
1.시간복잡도(Time Complexity)
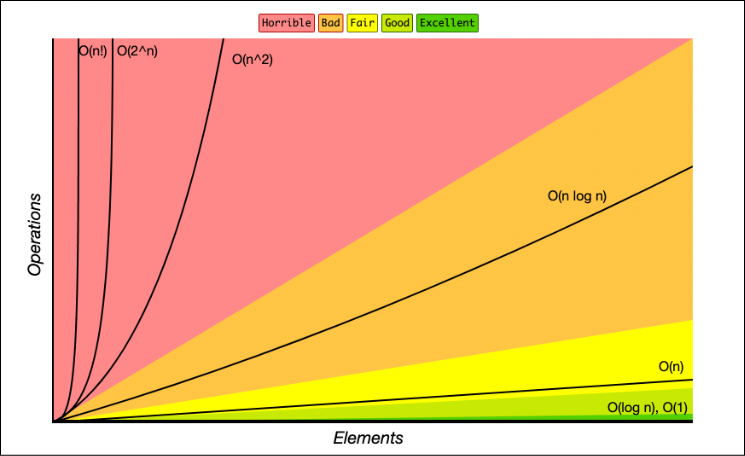
알고리즘의 실행 시간을 표현하는 것을 말한다. 여기서 실행 시간이란 통상적으로 쓰이는 시분초 개념이 아니라, 함수나 알고리즘 수행에 필요한 스텝 수를 의미한다. (실행 환경마다 성능이 다르기 때문에 시간을 초(seconds)나 밀리초(milliseconds)로 표현하면
2.Stack과 Queue
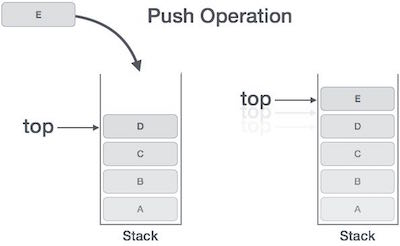
입력과 출력이 하나의 방향에서 일어나는 후입선출(LIFO)로 이루어지는 자료구조를 말한다. 즉 가장 최근에 넣은 데이터가 가장 먼저 나온다. Stack에 데이터를 넣는 것을 PUSH, 데이터를 꺼내는 것을 POP이라고 한다.데이터는 하나씩만 넣고 뺄 수 있다.https
3.[React] sidebar 만들기

참고https://wsss.tistory.com/124메뉴 버튼을 클릭하면 버튼 모양이 X로 바뀌고 왼쪽에서 메뉴가 튕겨져 나오는 사이드바를 클론해보았다. HTML, CSS, JS로 구현되어 있는 코드를 React와 styled-component로 바꾸면서 B
4.선택 정렬(selection sort)
대상 데이터에서 최솟값 (혹은 최댓값)을 찾고, 남은 정렬의 가장 앞에 있는 데이터와 교환하는 알고리즘을 가진 정렬이다. 선택 정렬은 구현 방법이 복잡하고, 시간 복잡도도 O(n^2)로 비효율적이기 때문에 자주 사용하지는 않는다. 선택 정렬의 과정은 다음과 같다. 1\
5.삽입 정렬(Insertion Sort)
삽입 정렬은 이미 정렬된 데이터 범위에 아직 정렬이 안 된 데이터를 적절한 위치에 삽입시켜 정렬하는 알고리즘이다.삽입 정렬은 시간 복잡도가 O(n^2)이지만 구현이 쉽다. 삽입 정렬의 과정1\. 현재 인덱스에 있는 데이터를 선택2\. 현재 선택한 데이터가 정렬된 데이터
6.버블 정렬(bubble sort)
버블 정렬은 두 인접한 데이터의 크기를 비교해 정렬하는 방법이다.버블 정렬 과정1\. 비교 연산이 필요한 루프 범위 설정2\. 인접한 데이터 값을 비교3\. swap 조건에 부합하면 swap4\. 반복문이 끝날 때까지 2~3번 반복5\. 정렬 영역을 설정한다. 다음 루
7.[React] 카드 슬라이더 만들기(1)
저번 주와 마찬가지로 javascript로 만들어진 카드 슬라이더를 리액트로 클론해보는 연습을 했다. 참고 https://wsss.tistory.com/1582Swiper API https://swiperjs.com/react우선 Swiper라는 라
8.퀵 정렬(Quick Sort)
기준값(pivot)을 선정해 해당 값보다 작은 데이터와 큰 데이터로 분류하는 것을 반복해 정렬하는 알고리즘이다. 데이터를 분할하는 pivot을 설정한다. 이 경우 pivot의 위치는 임의로 설정해도 된다.pivot을 기준으로 데이터를 2개의 집합으로 분리한다.이때 pi
9.힙 정렬 (Heap Sort)
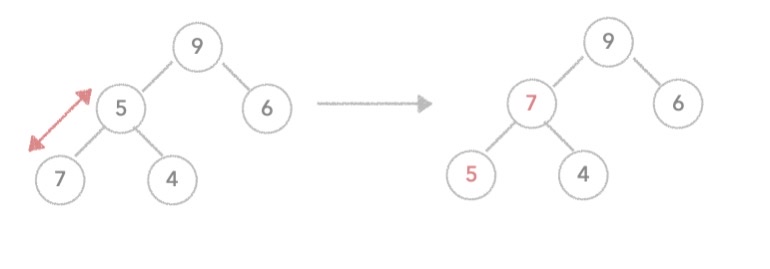
힙은 완전 이진 트리의 일종으로 최댓값, 최솟값을 쉽게 추출할 수 있고, 중복값을 허용한다는 특징을 가진다. 힙 정렬을 이해하기 위해서는 먼저 이진 트리와 완전 이진 트리에 대해 알아야 한다. 컴퓨터가 데이터를 표현할 때 데이터를 각 노드에 담은 뒤 노드를 두 개씩 이
10.BFS와 DFS
BFS와 DFS는 트리나 그래프 등의 비선형 구조를 무차별 탐색할 때 사용한다. 여기서 무차별 탐색이란 가능한 경우의 수를 전부 시도한다는 의미이다. 거리, 지도 탐색 등에 많이 사용된다. BFS는 넓이 우선 검색으로, 같은 depth를 모두 확인한 후에 내려가서 다시
11.해시(Hash)
해시는 데이터를 다루는 기법 중의 하나로, key-value 형태로 데이터가 존재하고, key 값이 배열의 인덱스로 저장되기 때문에 검색과 저장이 빠르게 일어나게 된다. 특정 데이터가 저장되는 인덱스가 그 데이터만의 고유한 위치이기 때문에 삽입 시 다른 데이터의 사이에