chapter1 - 자바 언어 기초
자바는 프로그래밍 언어로, 사람이 컴퓨터와 소통하기 위한 언어의 종류 중 하나이다.
사람이 자바 언어를 통해 소스코드(Source Code)를 생성하면 이를 컴퓨터가 이해하기 위해 기계어의 형식으로 번역하는 것을 컴파일(Compile)이라고 한다. 컴파일을 해주는 소프트웨어를 컴파일러(Compiler)라고 부르는데, C언어의 컴파일러가 GCC듯 자바는 JVM이 해당 기능을 수행한다.
JVM이 *.java 파일을 *.class 파일로 바꿔주면 컴퓨터가 읽어서 프로그램이 실행되는 것이다.
하지만 파이썬이나 자바스크립트는 이런 컴파일 과정을 거치지 않는데, 이는 인터프리터(Interpreter) 언어이기 때문이다. 이런 애들은 사람이 작성한 스크립트를 그때 그때 마다 번역해서 CPU에 전달하기 때문에 이런 과정이 통역과 비슷해 인터프리팅(interpreting)이라고 부른다.
이해하기 쉽게 비유하자면
컴파일러의 경우 책 한권을 통째로 번역한 후 출판해 읽는 것이고
인터프리터의 경우 구글 번역기로 필요한 문장을 하나씩 번역해 읽는 것이다.
둘 다 장단점이 있다.
전자는 한번 번역해 놓으면 몇 번이고 계속 읽어볼 수 있지만 수정하려면 책을 다시 써야 하고
후자는 바로바로 수정이 가능하지만 전달하고자 하는 내용이 많을 때는 구글번역기로 한줄씩 해석하면 너무 오래걸린다.
그래서 프로그래밍을 할 때는 본인이 만들고자 하는 소프트웨어가 어떤 특징을 가지는지를 먼저 생각하고 언어를 선택해야 한다.
chapter2 - 변수와 타입
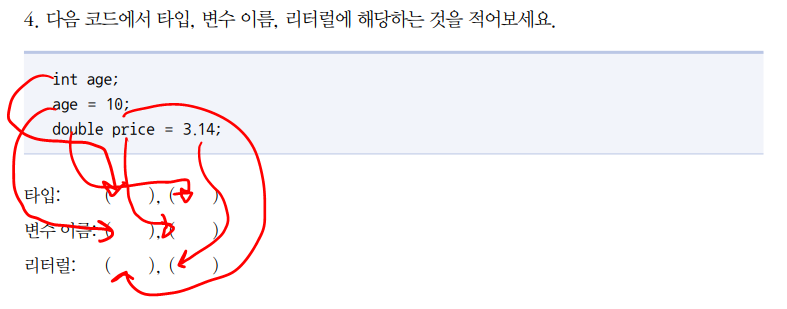
변수 선언
<자료형> <변수명> = <초기값>;
컴퓨터의 메모리(RAM)에는 많은 프로그램의 데이터를 저장한다. 이 때 어디에 어떤 방식으로 저장할지 미리 정해져 있지 않는다면 관리가 복잡해 지므로 자바를 포함한 여러 프로그래밍 언어들은 변수를 이용해 데이터를 저장한다.
변수는 하나의 값을 저장할 수 있는 메모리 주소에 붙여진 이름이다. 메모리가 아파트라고 치면 몇동 몇호에 누가 살고 있는지를 기록하는 것이다. 그래서 변수를 사용하기 위해 필요한 것은 자료형과 변수 이름이다.
int age; 이렇게 적으면 정수(int) 값을 저장 할 수 있는 변수 age를 선언한 것이다.
그럼 여기 있는 int 처럼 자료형의 종류에는 어떤 것이 있는지 알아보자.
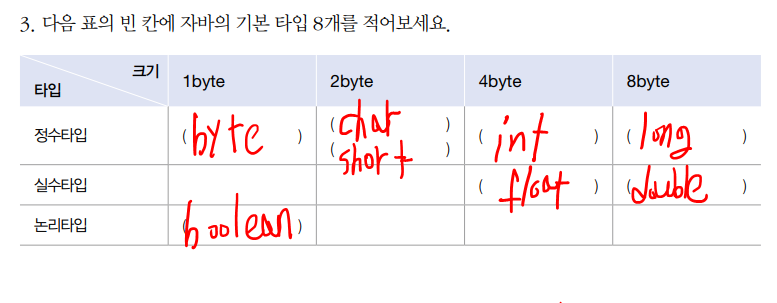
정수 타입
변수는 어떤 타입인지에 따라 메모리에 할당하는 크기와 담을 수 있는 값의 종류가 정해진다.
자바는 총 8개의 기본 타입이 존재한다. 이를 원시 타입(Primitive Type) 이라고 한다.
| 값의 분류 | 기본 타입 |
|---|---|
| 정수 | byte, char, short, int, long |
| 실수 | float, double |
| 논리(true,false) | boolean |
정수 타입은 5가지로, 다음과 같이 메모리 할당 크기와 지정된 범위를 가진다.
| 타입 | 메모리 | 크기 | 저장되는 값의 | 허용 범위 |
|---|---|---|---|---|
| byte | 1byte | 8bit | ~ | -128 ~ 127 |
| short | 2byte | 16bit | ~ | -32,768 ~ 32,767 |
| char | 2byte | 16bit | 0 ~ | 0 ~ 65535(유니코드) |
| int | 4byte | 32bit | ~ | -2,147,483,648 ~ 2,147,483,648 |
| long | 8byte | 64bit | ~ | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,808 |
여기서 char를 제외한 나머지 변수들은 모두 지수가 홀수인 것을 볼 수 있는데, 이는 맨 앞 비트가 부호를 결정짓는 용도로 사용되기 때문이다.
0 111 1111 이 2진수를 10진수로 바꾸면 127인데, 앞의 0은 양수를 의미한다.
1 000 0000 같은 경우는 맨 앞의 비트가 1 이기 때문에 음수를 의미하고, 음수를 표현할 때는 나머지 7개의 비트를 모두 뒤집은 후 1을 더한 다음 앞에 -를 붙이면서 완성된다.
문자 타입
하나의 문자를 작은따옴표로 감싼 것을 문자 리터럴이라고 한다.
문자 리터럴은 유니코드로 변환되어 저장되는데, 유니코드는 세계 각국의 문자를 0~65535 숫자로 매핑한 국제 표준 규약이다. 그래서 char는 이러한 유니코드들을 담을 용도로 만들어 진 것이다.
char var1 = 'A' // 문자와 매핑되는 숫자 : 65
char var2 = '가' // 문자와 매핑되는 숫자 : 44032이런식으로 매핑된다고 보면 된다.
char를 선언할 때 주의할 점은 초기화를 작은 따옴표(') 두개를 연속으로 붙이면 에러가 난다는 것이다.
char c = ''; //<- 컴파일 에러
char c = ' '; //<- 띄어쓰기를 넣어줘야 빈 공백이 들어간다. 실수 타입
실수는 float, double이 있으며 허용 범위는 아래와 같다.
| 타입 | 메모리 | 크기 | 저장되는 값의 허용 범위 | 유효 소수 이하 자리 |
|---|---|---|---|---|
| float | 4byte | 32bit | ~ | 7자리 |
| double | 8byte | 64bit | ~ | 15자리 |
자바는 부동 소수점(floating-point) 방식으로 메모리에 저장한다.
double이 float 보다 더 정밀하게 연산할 수 있다.
부동소수점 설명
논리 타입
이건 참과 거짓, boolean으로 선언하고 true와 false 두 가지가 있다.
연습문제

4번, 초기화 되지 않는 상태의 변수는 읽을 수 없습니다.

2번과 7번은 예약어, 3번은 숫자가 첫 글자, 4번,6번은 특수문자가 첫 글자라서 쓸 수 없습니다.

3번.
자동 타입 변환은 수용할 수 있는 메모리의 크기가 = 왼쪽에 있는 변수의 타입형이 오른쪽에 있는 타입형 보다 커야 하는데요.
그래야 비트가 덮어써지는 것이 가능하기 때문입니다. 그리고 3번 처럼
같은 4바이트 크기의 변수라도 short는 음수까지 나타내고 char는 음수를 나타낼 수 없기 때문에 에러가 발생합니다.

4번, String은 객체라서 아무리 한 글자라도 변환할 수 없습니다.

3번, char를 초기화 할 때는 공백이 있어야 합니다.

3번, 출력값을 바꾸는거지 변수값을 바꾸지는 않지요.

1번, byte + byte 하면 int가 나옵니다.

2번, Int가 아니라 Integer 입니다.
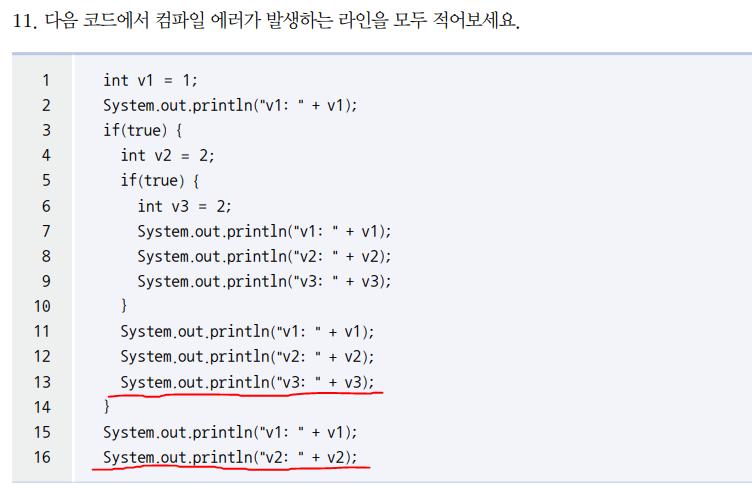
지역변수의 범위를 잘 알아야 합니다.
Chapter 3
자바의 연산자에 대해서 설명한다.
오버플로우와 언더플로우
타입이 혀용하는 최대값을 벗어나는 것을 오버플로우,
타입이 허용하는 최소값을 벗어나는 것을 언더플로우라고 한다.
정수 타입에서 오버/언더플로우가 발생 시 에러 대신 해당 정수 타입의 최대/최소값으로 되돌아간다.
NaN 과 Infinity
NaN과 Infinity는 나눗셈 또는 나머지 연산에서 좌측 피연산자가 정수, 우측 피연산자가 0일 경우 나타나는 예외처리의 일종이다. 원래 내 기억에는 ZeroDivisionerror float division by zero 뭔 이런 에러 메세지가 나왔던 것 같은데 자바가 버전이 올라가면서 생겼나보다.
5 / 0.0 -> Infinity
5 % 0.0 -> NaN
이런 예외처리가 일어날 시 에러가 뜨지 않고 그대로 컴파일이 되기 때문에 변수 연산에 큰 혼란을 줄 수도 있다. 그래서 안전하게 코딩하기 위해선
if(Double.isInfinite(z) || Double.isNaN(z))이렇게 Double에서 지원하는 함수를 통해 확인을 해 주는 것이 좋다.
비교 연산자
String을 == 으로 비교하지 않는 이유는 String이 Heap 영역에 생성된 객체이기 때문이다.
인스턴스 객체(Object)를 생성 했을 때, Heap 영역에 생성된 객체가 메모리상에 올리간다. 그리고 Stack 영역에 해당 객체에 대한 주소값이 저장된다.
또한 Stack에는 원시타입의 데이터(byte,short,int,long,double,float,boolean,char)가 저장된다.
즉, 인스턴스 객체 입장에서 보면 Stack 영역에 존재 하는 것은 오직 객체에 대한 주소값 뿐이다.
객체를 사용하려면 Stack에서 해당 주소값을 Heap에 대입해 객체를 찾는 식이다. 그래서 == 을 통해서 비교를 하게 될 시 다른 원시타입의 데이터는 값을 비교하지만 객체는 고유한 주소를 비교하게 되서 다른 결과값이 나온다.
그러므로, String 뿐만 아니라 임의로 만든 객체인 Car, Human 등등을 비교할 때도 반드시 equals를 오버라이딩해 같은지를 비교해야 한다.
그런데 여기서 드는 의문은 1 < 3 은 true가 나오지만 String <= String 이런식으로 객체끼리 대소를 비교 하게 되면 어떻게 될까? ==과 마찬가지로 이는 객체 끼리 작동하지 않는다. 객체를 비교하기 위해서는 Comparable 이라는 인터페이스를 상속받아 클래스의 기본 정렬 기준을 재정의 해줘야 한다.
Comparable의 ComapreTo() 메소드를 통해 기준을 재정의 할 수 있는데,
@Override
public int compareTo(Player o) {
return o.getScore() - getScore();
}이 ComapreTo의 리턴값이 양수일 때는 파리미터로 들어온 객체가 더 작다고 판별한다.
리턴값이 0일 때는 두 객체의 값이 동일,
리턴값이 음수일 때는 파라미터로 들어온 객체가 더 크다고 판별하게 되는 것이다.
논리 연산자 와 비트 연산자
논리 연산자에는 AND (&&), OR(||), XOR(^), NOT(!)
비트 연산자에는 AND (&), OR(|), XOR(^), NOT(~), Shift(>>, <<) 연산이 있다.
Shift연산은 이렇게 동작한다.
| 연산식 | 설명 |
|---|---|
x << y | 정수 x의 각 비트를 y만큼 왼쪽으로 이동시킴. (빈자리는 0으로 채워짐.) |
x >> y | 정수 x의 각 비트를 y만큼 오른쪽으로 이동시킴. (빈자리는 정수 x의 최상위 부호비트와 같은 값으로 초기화) |
&&과 &는 같은 기능을 하지만 &&이 더 효율적이다.
그 이유는 &&을 쓰게 될 시 앞의 피연산자가 false가 되면 즉시 false를 산출하지만
&는 두 피연산자를 모두 비교하기 때문이다.
||과 |도 같다.
비트 연산자는 비트마스킹 기법을 쓸 때 사용된다.
비트마스킹은 정수의 이진수를 자료구조로 쓰는 기법이다.
비트마스킹의 대표적인 용도는 Set을 구현하는 것이다.
비트마스킹으로 자바의 컬렉션 프레임워크인 Set을 구현할 수 있는데,
a |= (1<<k);이게 Set의 add(e)와 같다.
(1<<k)에 의해 k자리에 비트가 켜지게 되고 이를 a에 or 연산 해 집합 a 에 원소 k를 추가할 수 있다.
if(a &(1<<k) == (1<<k))이렇게 쓸 시 Contains(e)를 구현 할 수 있다.
집합 a에서 k의 자리가 켜져있는지 검사하고, 있다면 포함되어 있는 것으로 간주한다.
그리고 앞서 설명한 오버플로우와 언더플로우에 의해 정수에 대한 비트마스킹을 하다가
범위를 넘어가게 되면 쓰레기값이 담겨서 꼬일수도 있는데, 그래서 자바에서는 주로 부호가 없는(unsigned) 자료형인 char로 비트마스킹을 구현한다.
연습 문제
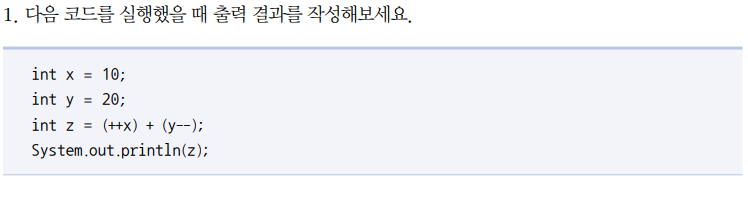
난 처음엔 30인줄 알았으나
y-- 연산은 int z = 의 = 보다 우선순위가 느리기 때문에
11+20이 z에 할당되고 그 다음에 y가 1 감소한다.
그러므로 31이다.
라고 생각했으나
증감 연산자 (++, --)는 우선순위가 가장 높았고 오히려 대입(=)은 가장 우선순위가 낮았다.
사실은 y-- 자체가 다른 연산을 먼저 수행하고 y를 1 감소시키는 기능을 하는 거였다.
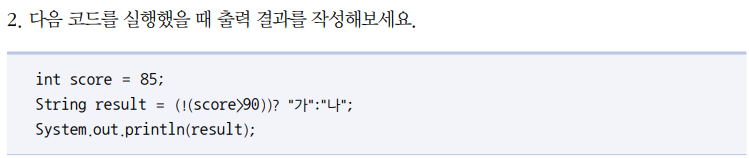
(!(85 > 90)) 85는 90보다 큰가요? -> 아니오. 앞에 !가 있으니 네. true 이므로 가를 출력
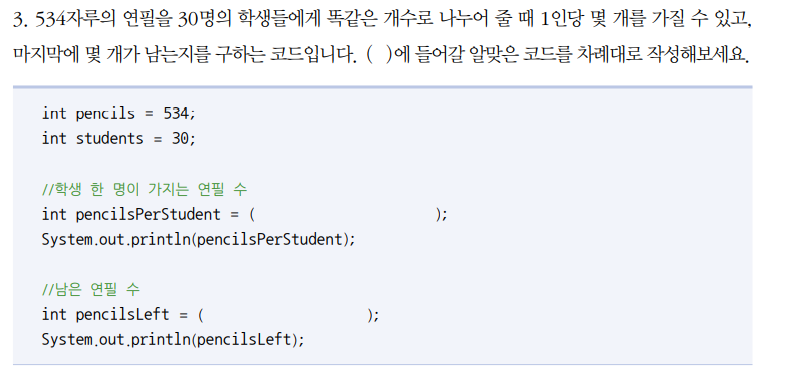
pencils / studentspencils % students

10의 자리를 버린다는 건 백의 자리를 구한 다음 100을 곱하는 것과 같습니다.
(value / 100) * 100

어차피 연산과정에 다 소수가 포함되어 있으니 1,2,3,4 모두 정답이네요.

10 > 7 && 5 <= 5 하면 true가 출력됩니다. 둘 다 참이니깐..
10%3 == 2 || 5%2 != 1 하면 false || false 라서 false 입니다.
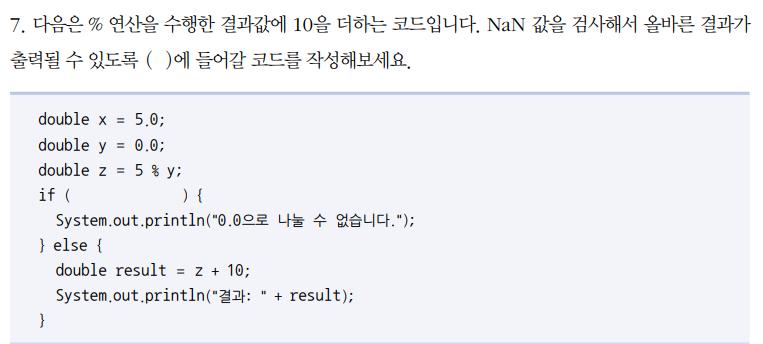
Double.isNaN(z)를 통해서 검사할 수 있습니다.
