EfficientNet
모델의 성능을 높이는 방법
- network의 depth를 깊게 만드는 것
- channel width(filter 개수)를 늘리는 것
- input image의 해상도를 올리는 것
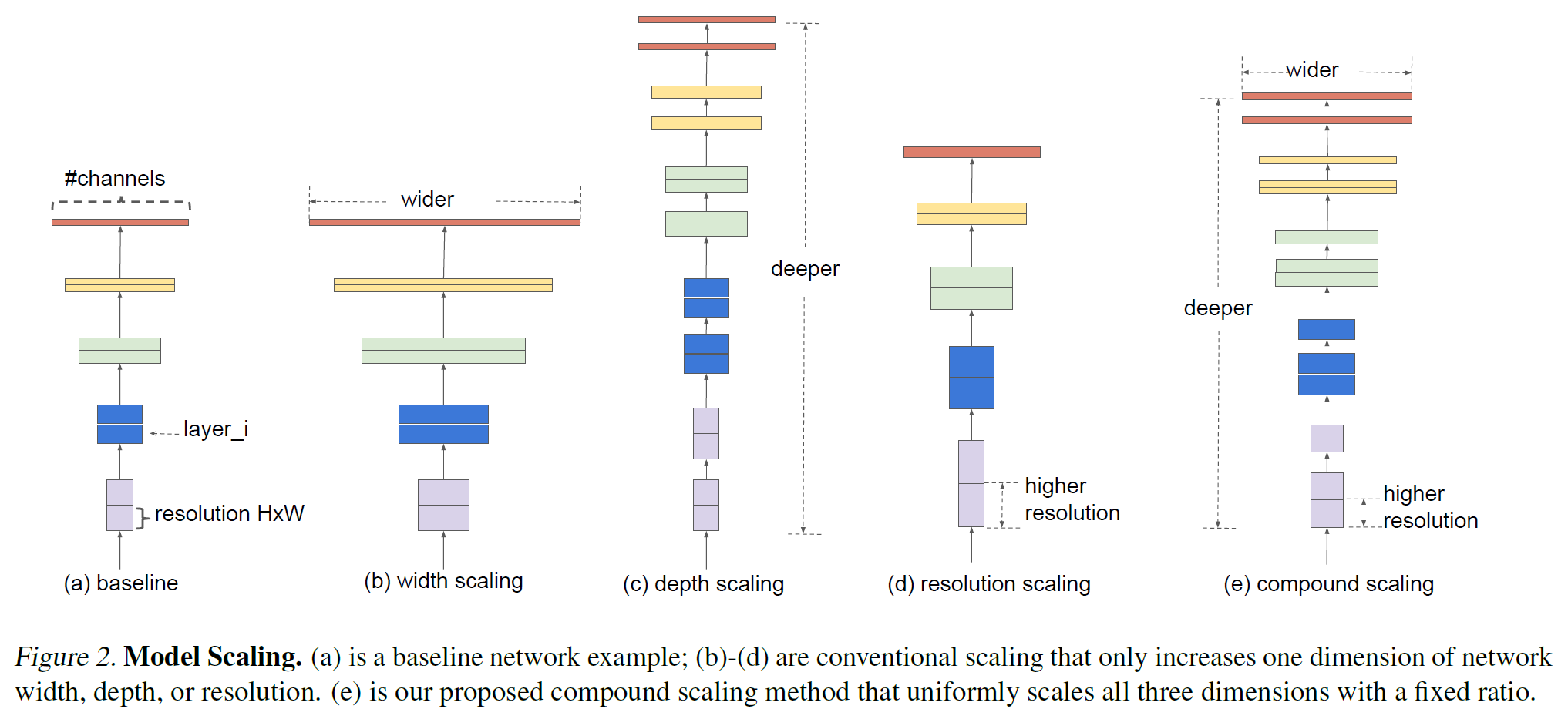
efficientnet이란?
- 모델의 성능을 높이는 방법에 관여하는 depth, width, resolution을 compound coefficient를 통해 상관 관계를 가지는 식을 통해 효율적인 조합을 찾는다.
- 기존의 모델들보다 적은 FLOPS(계산량)으로 더 좋은 성능을 낸다.
Efficientnet B0 ~ B7의 차이
- B0에서 b7으로 갈수록 Compound scaling을 통한 데이터의 사이즈가 커진다.
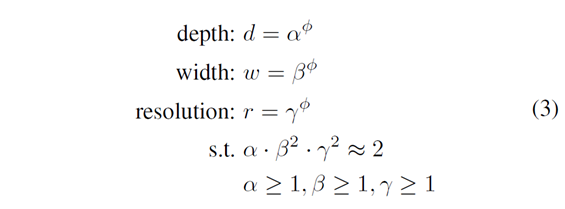
- Efficientnet b0의 경우 α=1,β=1로 설정되어있으며 매개 변수는 4.5M
매개 변수 설정
batch size = 16
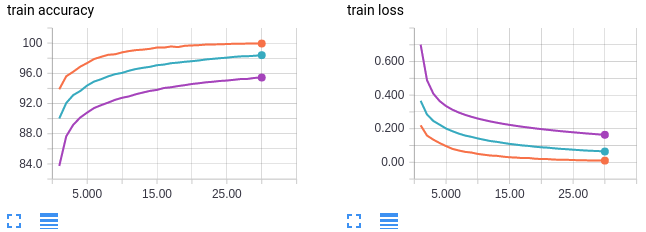
- orange curve : batch size 64
- Blue curves: batch size 256
- Purple curves: batch size 1024
- 통계적으로 적은 batch size를 가질수록 훈련시간은 오래 걸리지만 성능에 있어 향상이 있었기에 기존 batch size 32에서 16으로 축소
data set 분할
- train : valid set data를 0.95 : 0.05로 분할
data = datasets.ImageFolder(data_dir)
train_size = int(len(data)*0.95)
val_size = int((len(data)-train_size))
train_data,val_data = random_split(data,[train_size,val_size])
torch.manual_seed(3334)
print(f'train size: {len(train_data)}\nval size: {len(val_data)}')Efficient Net B0 model
class MBConv(nn.Module):
def __init__(self, in_, out_, expand,
kernel_size, stride, skip,
se_ratio, dc_ratio=0.2):
super().__init__()
mid_ = in_ * expand
self.expand_conv = conv_bn_act(in_, mid_, kernel_size=1, bias=False) if expand != 1 else nn.Identity()
self.depth_wise_conv = conv_bn_act(mid_, mid_,
kernel_size=kernel_size, stride=stride,
groups=mid_, bias=False)
self.se = SEModule(mid_, int(in_ * se_ratio)) if se_ratio > 0 else nn.Identity()
self.project_conv = nn.Sequential(
SamePadConv2d(mid_, out_, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_, 1e-3, 0.01)
)
# if _block_args.id_skip:
# and all(s == 1 for s in self._block_args.strides)
# and self._block_args.input_filters == self._block_args.output_filters:
self.skip = skip and (stride == 1) and (in_ == out_)
# DropConnect
# self.dropconnect = DropConnect(dc_ratio) if dc_ratio > 0 else nn.Identity()
# Original TF Repo not using drop_rate
# https://github.com/tensorflow/tpu/blob/05f7b15cdf0ae36bac84beb4aef0a09983ce8f66/models/official/efficientnet/efficientnet_model.py#L408
self.dropconnect = nn.Identity()
def forward(self, inputs):
expand = self.expand_conv(inputs)
x = self.depth_wise_conv(expand)
x = self.se(x)
x = self.project_conv(x)
if self.skip:
x = self.dropconnect(x)
x = x + inputs
return x
class MBBlock(nn.Module):
def __init__(self, in_, out_, expand, kernel, stride, num_repeat, skip, se_ratio, drop_connect_ratio=0.2):
super().__init__()
layers = [MBConv(in_, out_, expand, kernel, stride, skip, se_ratio, drop_connect_ratio)]
for i in range(1, num_repeat):
layers.append(MBConv(out_, out_, expand, kernel, 1, skip, se_ratio, drop_connect_ratio))
self.layers = nn.Sequential(*layers)
def forward(self, x):
return self.layers(x)
class EfficientNet(nn.Module):
def __init__(self, width_coeff, depth_coeff,
depth_div=8, min_depth=None,
dropout_rate=0.2, drop_connect_rate=0.2,
num_classes=400):
super().__init__()
min_depth = min_depth or depth_div
def renew_ch(x):
if not width_coeff:
return x
x *= width_coeff
new_x = max(min_depth, int(x + depth_div / 2) // depth_div * depth_div)
if new_x < 0.9 * x:
new_x += depth_div
return int(new_x)
def renew_repeat(x):
return int(math.ceil(x * depth_coeff))
self.stem = conv_bn_act(3, renew_ch(32), kernel_size=3, stride=2, bias=False)
self.blocks = nn.Sequential(
# input channel output expand k s skip se
MBBlock(renew_ch(32), renew_ch(16), 1, 3, 1, renew_repeat(1), True, 0.25, drop_connect_rate),
MBBlock(renew_ch(16), renew_ch(24), 6, 3, 2, renew_repeat(2), True, 0.25, drop_connect_rate),
MBBlock(renew_ch(24), renew_ch(40), 6, 5, 2, renew_repeat(2), True, 0.25, drop_connect_rate),
MBBlock(renew_ch(40), renew_ch(80), 6, 3, 2, renew_repeat(3), True, 0.25, drop_connect_rate),
MBBlock(renew_ch(80), renew_ch(112), 6, 5, 1, renew_repeat(3), True, 0.25, drop_connect_rate),
MBBlock(renew_ch(112), renew_ch(192), 6, 5, 2, renew_repeat(4), True, 0.25, drop_connect_rate),
MBBlock(renew_ch(192), renew_ch(320), 6, 3, 1, renew_repeat(1), True, 0.25, drop_connect_rate)
)
self.head = nn.Sequential(
*conv_bn_act(renew_ch(320), renew_ch(1280), kernel_size=1, bias=False),
nn.AdaptiveAvgPool2d(1),
nn.Dropout2d(dropout_rate, True) if dropout_rate > 0 else nn.Identity(),
Flatten(),
nn.Linear(renew_ch(1280), num_classes)
)
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, SamePadConv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
elif isinstance(m, nn.Linear):
init_range = 1.0 / math.sqrt(m.weight.shape[1])
nn.init.uniform_(m.weight, -init_range, init_range)
def forward(self, inputs):
stem = self.stem(inputs)
x = self.blocks(stem)
head = self.head(x)
return head
KHU, SWCON