depth의 수정
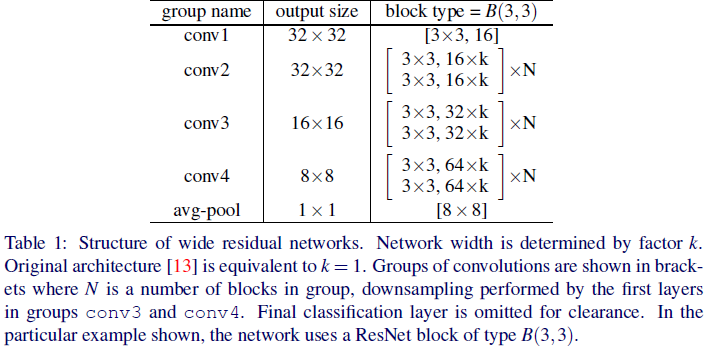
- Wide Resnet은 conv1 / conv2 / conv3 / conv4에서 각각 shortcut 형태로 layer가 들어가게 되므로 기본적으로 4개의 layer가 형성되어 있다.
- conv2에서 3x3 2 layers, conv3에서 3x3 2 layers, conv4에서 3x3 2layers로 총 6개가 depth를 늘릴 때마다 추가된다.
- 따라서 WRN의 Depth는 6n + 4의 형태를 가지게 된다.
width의 수정
- depth의 변화에 따라 총 매개변수가 5M이 넘지 않도록 조정한다.
1st : depth 28 / width 3
parser = argparse.ArgumentParser()
parser.add_argument("--adaptive", default=True, type=bool, help="True if you want to use the Adaptive SAM.")
parser.add_argument("--batch_size", default=32, type=int, help="Batch size used in the training and validation loop.")
parser.add_argument("--depth", default=28, type=int, help="Number of layers.")
parser.add_argument("--dropout", default=0.0, type=float, help="Dropout rate.")
parser.add_argument("--epochs", default=50, type=int, help="Total number of epochs.")
parser.add_argument("--label_smoothing", default=0.1, type=float, help="Use 0.0 for no label smoothing.")
parser.add_argument("--learning_rate", default=0.11, type=float, help="Base learning rate at the start of the training.")
parser.add_argument("--momentum", default=0.9, type=float, help="SGD Momentum.")
parser.add_argument("--threads", default=2, type=int, help="Number of CPU threads for dataloaders.")
parser.add_argument("--rho", default=2.0, type=int, help="Rho parameter for SAM.")
parser.add_argument("--weight_decay", default=0.0005, type=float, help="L2 weight decay.")
parser.add_argument("--width_factor", default=3, type=int, help="How many times wider compared to normal ResNet.")
args = parser.parse_args("")변수 정리 및 결과
- batch size = 32
- criterion = nn.CrossEntropyLoss()
- learning rate = 0.11
- depth : 28
- width : 3
- optimizer = SAM(model.parameters(), base_optimizer, rho=args.rho, adaptive=args.adaptive, lr=args.learning_rate, momentum=args.momentum, weight_decay=args.weight_decay)
- scheduler = StepLR(optimizer, args.learning_rate, args.epochs)
결과
- accuracy : 0.92700
2nd : depth : 10 / width : 5
parser = argparse.ArgumentParser()
parser.add_argument("--adaptive", default=True, type=bool, help="True if you want to use the Adaptive SAM.")
parser.add_argument("--batch_size", default=32, type=int, help="Batch size used in the training and validation loop.")
parser.add_argument("--depth", default=10, type=int, help="Number of layers.")
parser.add_argument("--dropout", default=0.0, type=float, help="Dropout rate.")
parser.add_argument("--epochs", default=50, type=int, help="Total number of epochs.")
parser.add_argument("--label_smoothing", default=0.1, type=float, help="Use 0.0 for no label smoothing.")
parser.add_argument("--learning_rate", default=0.1, type=float, help="Base learning rate at the start of the training.")
parser.add_argument("--momentum", default=0.9, type=float, help="SGD Momentum.")
parser.add_argument("--threads", default=2, type=int, help="Number of CPU threads for dataloaders.")
parser.add_argument("--rho", default=2.0, type=int, help="Rho parameter for SAM.")
parser.add_argument("--weight_decay", default=0.0005, type=float, help="L2 weight decay.")
parser.add_argument("--width_factor", default=5, type=int, help="How many times wider compared to normal ResNet.")
args = parser.parse_args("")변수 정리 및 결과
- batch size = 32
- criterion = nn.CrossEntropyLoss()
- learning rate = 0.1
- depth : 10
- width : 5
- optimizer = SAM(model.parameters(), base_optimizer, rho=args.rho, adaptive=args.adaptive, lr=args.learning_rate, momentum=args.momentum, weight_decay=args.weight_decay)
- scheduler = StepLR(optimizer, args.learning_rate, args.epochs)
결과
- accuracy : 0.92700

KHU, SWCON