관계 데이터 모델에서 지원되는 두 가지 정형적인 언어
관계 해석
- 원하는 데이터만 명시하고 질의를 어떻게 수행할 것인가는 명시하지 않는 선언적인 언어
관계 대수
- 어떻게 질의를 수행할 것인가를 명시하는 절차적인 언어
- 관계 대수는 상용 관계 DBMS에서 널리 사용되는 SQL의 이론적인 기초
- 관계 대수는 SQL을 구현하고 최적화하기 위해 DBMS 내부 언어로도 사용된다
- 기존의 릴레이션들로부터 새로운 릴레이션을 생성한다.
- 기본적인 연산자들의 집합으로 이루어져 있다.
- 결과 릴레이션은 또 다른 관계 연산자의 입력으로 사용될 수 있다.
관계 대수의 완전성
- 일의의 질의어가 적어도 필수적인 관계 대수 연산자들만큼의 표현력을 갖고 있으면 관계적으로 완전하다고 말한다.
관계 대수의 연산자
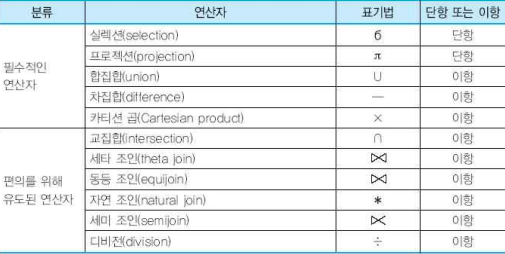
- 편의를 위해 유도된 연산자는 필수적인 연산자들의 조합으로 표현할 수 있다.
- division : R % S = πA(R)−πA(πA(R)×S−R)
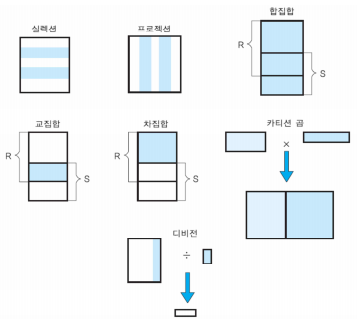
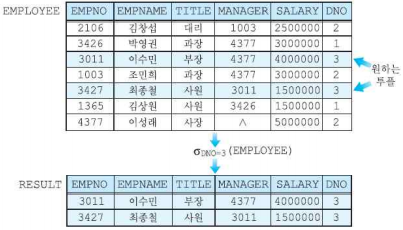
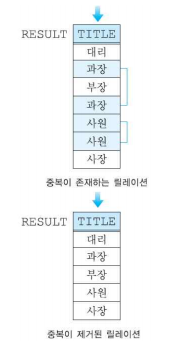
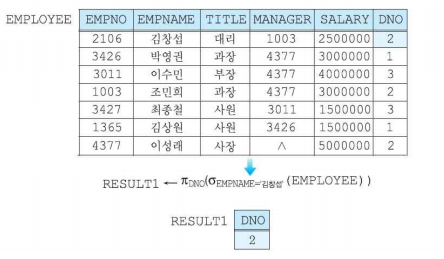
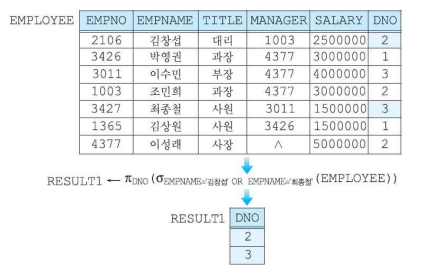
실렉션(Selection)

- 특정 열을 선택하는 연산자
- 차수에는 변화를 주지 않으며, 카디널리티는 작거나 같아지면 0의 값을 가질 수 있다.
- 실렉션 조건을 predicate라고 부른다.
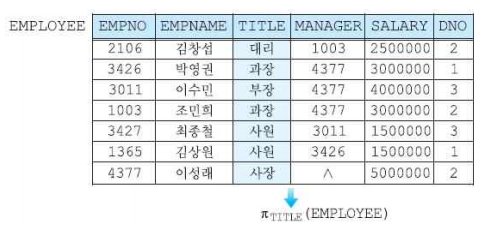
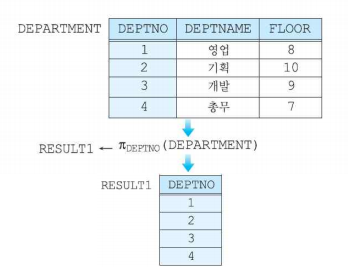
프로젝션(Projection)
- 특정 열을 선택하는 연산자
- 카디널리티에 변화를 주지 않으며, 차수는 작거나 같아지며 0보다 큰 값을 가진다.
- 중복 투플이 선택될 수 있으나 결과 릴레이션에는 중복이 제거된다.
집합 연산자
- 릴레이션이 투플들의 집합이기 때문에 기존의 집합 연산이 릴레이션에 적용된다.
- 집합 연산에 사용되는 2개의 릴레이션은 합집합 호환이여야 한다.
합집합 호환
- 필요충분조건 : 두 릴레이션의 애트리뷰트의 수가 같아야하며, 각 대응되는 도메인이 같아야한다.
합집합 연산자
- 결과 릴레이션에서 중복된 투플은 제거된다.
- 결과 릴레이션의 차수는 입력 릴레이션의 차수와 같고 애트리뷰트의 이름은 두 입력 중 하나의 애트리뷰트들과 같다.
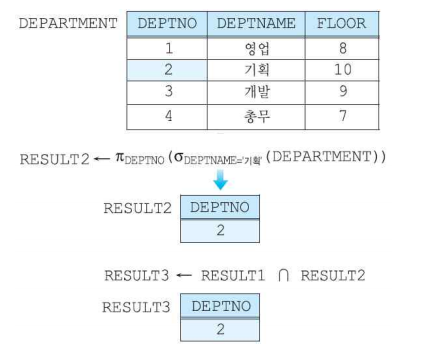
교집합 연산자
- 결과 릴레이션의 차수는 교집합 대상이 되는 두 릴레이션의 차수와 같으며 결과 릴레이션의 애트리뷰트 이름은 두 릴레이션 중 하나의 릴레이션 애트리뷰트와 같은 이름을 가진다.
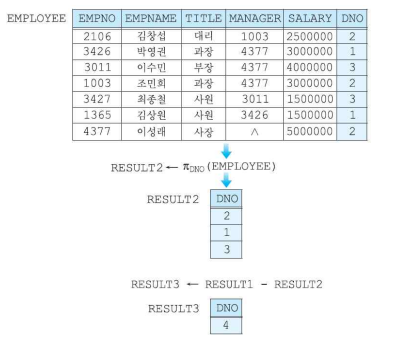
차집합 연산자
- R - S 의 형식으로 나타낸다.
- 결과 릴레이션은 R 또는 S의 차수와 같으며 애트리뷰트들의 이름은 R 또는 S의 애트리뷰트 이름을 가진다.
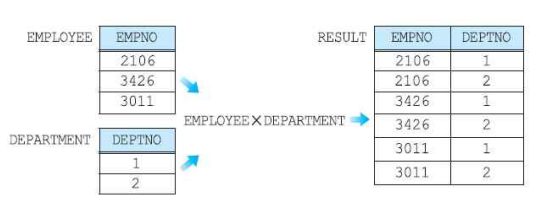
카티션 곱 연산자
- 입력 릴레이션의 차수가 각각 X,Y 이면 결과 릴레이션의 차수는 X + Y
- 입력 릴레이션의 카디널리티가 각각 X,Y 이면 결과 릴레이션의 카디널리티는 X * Y
- 카티션 곱의 결과는 매우 클 수 있으며, 대부분 사용자가 원하는 결과가 아니다.

KHU, SWCON