물리적 데이터베이스 설계
- 논리적인 설계의 데이터 구조를 보조 기억 장치상의 파일(물리적인 데이터 모델)로 사상한다.
- 예상 빈도를 포함하여 데이터베이스 질의와 트랜잭션들을 분석한다.
- 데이터에 대한 효율적인 접근을 제공하기 위하여 저장 구조와 접근 방법들을 다룬다.
- 특정 DBMS의 특성을 고려하여 진행된다.
- 질의를 효율적으로 지원하기 위해서 인덱스 구조를 적절히 사용한다.
보조 기억 장치
- 사용자가 원하는 데이터를 검색하기 위해서 DBMS는 디스크 상의 데이터베이스로부터 사용자가 원하는 데이터를 포함하고 있는 블록을 읽어서 주기억 장치로 가져온다.
- 데이터가 변경된 경우에는 블록들을 디스크에 다시 기록한다.
- 블록 크기는 512바이트로부터 수 킬로바이트까지 다양하게 존재한다.
- 전형적인 블록 크기는 4096바이트
- 각 파일은 고정된 크기의 블록들로 나누어져서 저장된다.
- 디스크는 데이터베이스를 장기간 보관하는 주된 보조 기억 장치
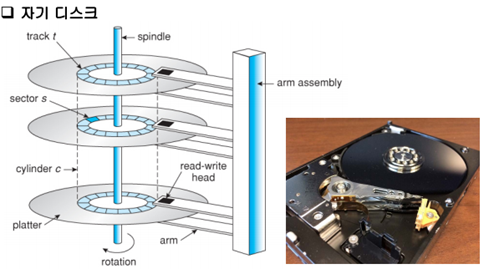
자기 디스크
- 디스크는 자기 물질로 만들어진 여러 개의 판으로 이루어져 있다.
- 각 면마다 디스크 헤드가 있다.
- 블록 (데이터 전송 단위)
- 각 판은 트랙과 섹터로 구분된다.
- 정보는 디스크 표면 상의 동심원(트랙)을 따라 저장된다.
- 여러 개의 디스크 면 중에서 같은 지름을 갖는 트랙들을 실린더라고 부른다.
- 블록은 한 개 이상의 섹터들로 이루어진다.
- 디스크에서 임의로 블록을 읽어오거나 기록하는데 걸리는 시간은 탐구 시간(seek time), 회전 지연 시간(rotational delay), 전송 시간(transfer time)의 합
- Arm assembly의 속도가 느리기 때문에 탐구 시간이 제일 오래 걸린다.
- 실린더의 역할이 중요해진다.
- HDD는 RPM을 성능의 척도로 가질 수 있으며 회전은 전기를 소모하기에 노트북 작게 설정
버퍼 관리와 운영 체제
- 디스크 입출력은 컴퓨터 시스템에서 가장 속도가 느린 작업이므로 입출력 횟수를 줄이는 것이 DMBS의 성능을 향상하는데 매우 중요하다.
- 가능하면 많은 블록들을 주기억 장치에 유지하거나 자주 참조되는 블록들을 주기억 장치에 유지하면 블록 전송 횟수를 줄일 수 있다.
- 버퍼는 디스크 블록들을 저장하는데 사용되는 주기억 장치 공간
- 버퍼 관리자는 운영 체제의 구성요소로써 주기억 장치 내에서 버퍼 공간을 할당하고 관리하는 일을 맡는다.
- 각 버퍼 slot에 어떤 disk page를 관리하고 있는지를 표시하는 mapping table을 가지고 있다.
- 운영체제에서 버퍼 관리를 위해 흔히 사용되는 LRU알고리즘은 항상 우수한 성능을 내지는 않는다.
- 버퍼가 꽉 찬 경우에는 replace policy에 의해 정해진 버퍼를 제거하고 읽고자 하는 버퍼를 넣는다.
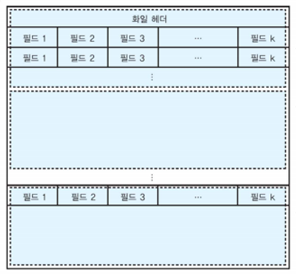
디스크 상에서 파일의 레코드 배치
-
릴레이션의 애트리뷰트는 고정 길이 또는 가변 길이의 필드로 표현된다.
-
연관된 필드들이 모여서 고정 길이 또는 가변 길이의 레코드가 된다.
-
한 릴레이션을 구성하는 레코드들의 모임이 파일이라고 부르는 블록들의 모임에 저장
-
파일은 파일 헤더를 가지고 있으며, 블록들도 블록 헤더를 가질 수 있다.
-
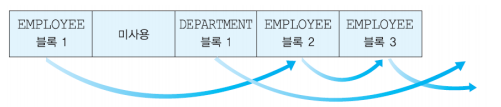
한 파일에 속하는 블록들이 반드시 인접해 있을 필요는 없지만, 인접해 있을 경우 탐구 시간과 회전 지연 시간이 들지 않기 때문에 블록들이 인접하도록 재조직할 수 있다.
-
떨어져 있더라도 Mapping table(FAT)이나 linked list를 통하여 표시할 수 있다.
BLOB (Binary Large Object)
- 이미지(GIF, JPG), 동영상(MPEG, RM) 등의 대규모 크기의 데이터를 저장하는데 사용된다.
- BLOB의 최대 크기는 오라클의 경우 8~128 TB
채우기 인수 (Fill Factor)
- 각 블록에 레코드를 채우는 공간의 비율
- 데이터 베이스 구축시 기존에 가지고 있는 대량의 데이터를 Bulk load하며, 추가적인 레코드 삽입시 기존의 레코드들을 이동하는 가능성을 줄이기 위해서 사용한다.
고정 길이 레코드
Record Reading
- 레코드 i를 접근하기 위해서는 n * (i-1) + 1의 위치에서 레코드를 읽는다.
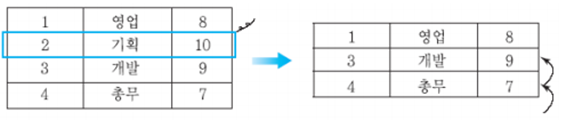
Record 삭제
-
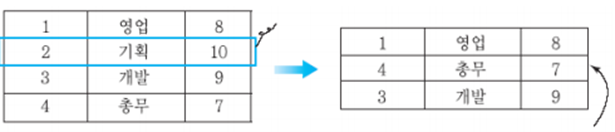
고정 길이 레코드 삭제시 레코드 순서 유지를 위해 여러 개의 레코드를 이동한다
-
레코드 순서 유지가 중요하지 않을 경우 한 개의 레코드를 이동한다.
-
지연 관리 방법 : 삭제된 공간을 관리하기 위해 free list를 관리한다 (이동 필요 없음)
파일 내의 클러스터링(Intra-file clustering)
- 한 파일 내에서 함께 검색될 가능성이 높은 레코드들을 디스크 상에서 물리적으로 가까운 곳에 모아두는 것
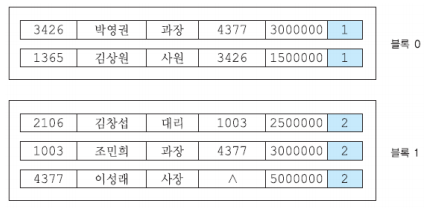
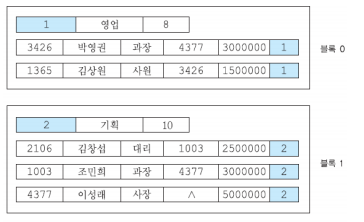
파일 간의 클러스터링(Inter-file clustering) / 릴레이션 간의 클러스터링
- 논리적으로 연관되어 함께 검색될 가능성이 높은 두 개 이상의 파일에 속한 레코드들을 디스크 상에서 물리적으로 가까운 곳에 저장하는 것

KHU, SWCON