인덱스 된 순차 파일은 인덱스를 통해서 임의의 레코드를 접근할 수 있는 파일
인덱스
- 탐색 키를 가진 레코드의 빠른 검색을 위해 <탐색키, 레코드 포인터> 쌍을 관리하는 구조
- 데이터 파일과는 별도의 파일에 저장된다.
- 인덱스의 크기는 데이터 파일의 크기에 비해 훨씬 작다.
- 하나의 파일에 여러 개의 인덱스를 정의할 수 있다.
- 단일 단계 인덱스의 엔트리 : <탐색 키, 레코드에 대한 포인터>
- 엔트리(탐색키, 레코드 포인터)들은 탐색 키 값의 오름차순으로 정렬된다.
- 레코드 포인터 : 블록 포인터 + 레코드 오프셋
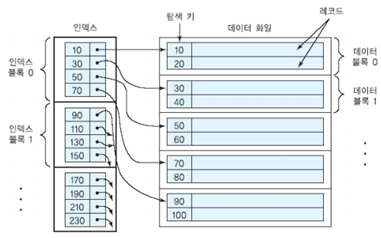
희소 인덱스 (순차파일에서만 가능) <탐색키, 블록 포인터>
- 데이터 블록에 대해 하나의 인덱스 엔트리가 만들어진 인덱스
- 블록을 지칭하는 블록 포인터를 가지며 각 블록의 첫번째 탐색키를 데이터로 가지고 있다.
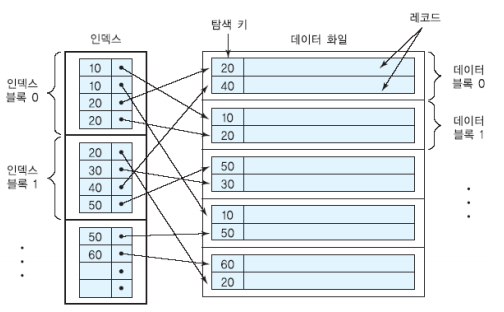
밀집 인덱스 <탐색키, 레코드 포인터(블록 포인터 + 레코드 오프셋)>
- 데이터 레코드 각각에 대해 하나의 인덱스 엔트리가 만들어진 인덱스
탐색 키
- 인덱스가 정의된 필드, 탐색의 기준으로 사용되는 attribute
- 후보키처럼 각 투플마다 고유하지 않으며, 키 attribute 외에 어떤 애튜리뷰트도 탐색 키로 사용된다.
- 인덱스의 엔트리들은 탐색 키 값의 오름차순으로 저장되어 있으므로 이진탐색을 이용할 수 있다.
기본 인덱스
- 탐색 키가 데이터 파일의 기본 키인 인덱스
- 일반적으로 희소 인덱스로 유지한다(밀집 인덱스와 대비)
- 최대 한 개의 기본 인덱스를 가질 수 있다.
클러스터링 인덱스
- 탐색 키 값에 따라 정렬된 데이터 파일에 대해 정의된다.
- 각각의 상이한 키 값마다 하나의 인덱스 엔트리가 인덱스에 포함된다.
- 기본 키가 아닌 중복이 가능한 파일 위에 정의된다.
- 범위 시작 값에 해당하는 인덱스 엔트리를 찾고, 순차적으로 찾아오기 때문에 범위 질의에 유용하다.
- 어떤 인덱스 엔트리에서 참조되는 데이터 블록을 읽어오면 그 데이터 블록에 들어 있는 대부분의 레코드들은 범위를 만족한다.
보조 인덱스
- 한 파일은 한가지 필드들의 조합에 대해서만 정렬될 수 있다.
- 보조 인덱스는 탐색 키 값에 따라 정렬되지 않은 데이터 파일에 대해 정의된다.
- 일반적으로 밀집 인덱스이므로 같은 수의 레코드들을 접근할 때 보조 인덱스를 통하면 디스크 접근 횟수가 증가할 수 있다.
희소 인덱스 vs. 밀집 인덱스
- 희소 인덱스는 일반적으로 밀집 인덱스에 비해 인덱스 단계 수가 1정도 적으므로 인덱스 탐색시 디스크 접근 수가 1만큼 적을 수 있다.
- 대부분의 경우에는 희소 인덱스가 효율적이지만, 질의에서 인덱스가 정의된 애트리뷰트만 검색(count 질의 등)하는 경우에는 데이터 파일에 접근할 필요 없이 인덱스만 접근해서 질의를 수행할 수 있으므로 더 유리하다.
클러스터링 인덱스 vs. 보조 인덱스
- 클러스터링 인덱스는 희소 인덱스일 경우가 많으며 범위 질의 등에 좋다
- 보조 인덱스는 밀집 인덱스이므로 일부 질의에 대해서는 파일에 접근할 필요 없이 처리할 수 있다
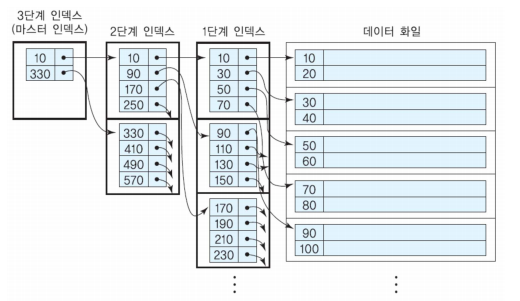
다단계 인덱스 (대부분 B+-트리를 사용한다.)
- 인덱스 엔트리 탐색 시간을 줄이기 위해서 단일 단계 인덱스를 디스크 상의 하나의 순서 파일로 간주하고 단일 단계 인덱스에 대해서 다시 인덱스를 정의한다.
- 가장 상위 단계 인덱스(Master Index)가 하나의 블록에 들어갈 때까지 반복한다.
- Master Index는 한 블록이므로 주기억장치에 상주할 수 있다
SQL 인덱스 정의문
- CREATE TABLE문에서 기본 키로 명시한 애트리뷰트에 대해서는 DBMS가 자동적으로 기본 인덱스를 생성한다.
- UNIQUE로 명시한 애트리뷰트에 대해서는 DBMS가 자동적으로 보조 인덱스를 생성한다.
- SQL2는 인덱스 정의 및 제거에 관한 표준 SQL문을 제공하지 않는다.
- 다른 애트리뷰트에 추가로 인덱스를 정의하기 위해서는 CREATE INDEX문을 사용한다.
다수의 애트리뷰트를 사용한 인덱스 정의
- 한 릴레이션에 속하는 2개 이상의 애트리뷰트들의 조합에 대하여 하나의 인덱스를 정의할 수 있다.
CREATE INDEX EMP INDEX ON EMPLOYEE (DNO, SALARY);
SELECT *
FROM EMOLOYEE
WHERE DNO = 3 > SALARY = 400000; # 특정한 값 조건이 주어질 때 사용 가능
SELECT *
FROM EMPLOYEE
WHERE DNO>=2 AND DNO <=3 AND SALARY >= 3000000
AND SALARY <= 4000000; # 범위 조건이 주어질 때 사용 가능
SELECT *
FROM EMPLOYEE
WHERE DNO = 2; # 앞의 애트리뷰트에 대한 점/범위 질의에 사용 가능
SELECT *
FROM EMPLOYEE
WHERE SALARY >= 3000000
AND SALARY <= 4000000; # 앞의 애트리뷰트(DNO의 값)이 할당되지 않아 사용하지 못한다.인덱스의 장점과 단점
- 인덱스는 검색 속도를 향상시키지만, 인덱스를 저장하기 위한 공간이 추가로 필요하고, 삽입/삭제/수정 속도 저하
- 삽입/삭제/수정 시 인덱스에도 반영해야 하기 때문에 시간이 오래 걸린다.
- 소수의 레코들을 수정하거나 삭제하는 연산의 속도는 향상된다.
- 릴레이션이 매우 크고, 질의에서 릴레이션의 투플들 중 일부(2~4%)를 검색하고, WHERE절이 잘 표현되었을 때 성능에 도움이 된다.
1단계 인덱스 : 희소 또는 밀집 인덱스 가능 / 그 이상의 인덱스 : 희소 인덱스
인덱스 선정 지침과 데이터베이스 튜닝
-
가장 중요한 질의들과 이들의 수행 빈도, 가장 중요한 갱신들과 이들의 수행 빈도, 이와 같은 질의와 갱신들에 대한 바람직한 성능들을 고려하여 인덱스를 선정한다.
-
워크로드 내의 각 질의에 대해 이 질의가 어떤 릴레이션에 접근하는가, WHERE절의 선택/조인 조건에 어떤 애트리뷰트들이 포함되는가, 이 조건들의 선별력은 얼마인가 등을 고려한다.
-
워크로드 내의 각 갱신에 대해 이 갱신이 어떤 애트리뷰트들이 포함되는가, 이 조건들의 선별력은 얼마인가, 갱신의 유형(INSERT/DELETE/UPDATE), 갱신의 영향을 받는 애트리뷰트 등을 고려한다.
워크로드
- 데이터베이스 질의들을 모아둔 것, 질의 종류 및 질의의 빈도 등 WORK에 대해 알 수 있게 한다.
선별력
- (조건에 의해 선택된 투플수)/(전체 투플 개수), 선별력의 값이 작은 것이 선별력이 높으며 선별력이 높도록 WHERE절 기재
-
어떤 릴레이션에 인덱스를 생성해야 하는가, 어떤 애트리뷰트를 탐색 키로 선정해야 하는가, 몇 개의 인덱스를 생성해야 하는가, 각 인덱스에 대해 클러스터링/밀집/희소 인덱스 중 어느 유형을 선택할 것인가를 고려해야 한다.
-
인덱스를 선정하는 한 가지 방법은 가장 중요한 질의들을 차례로 고려해보고, 현재의 인덱스가 최적의 계획에 적합한지 고려해보고, 인덱스를 추가하면 더 좋은 계획이 가능한지 알아본다.
-
물리적 데이터베이스 설계는 끊임없이 이루어지는 작업이다.
인덱스가 사용되지 않는 경우
- 시스템 카탈로그가 오래 전의 데이터베이스 상태를 나타낼 때
- DBMS의 질의 최적화 모듈이 릴레이션의 크기가 작아서 인덱스가 도움이 되지 않는다고 판단할 때
- 인덱스가 정의된 애트리뷰트에 산술연산자가 사용될 때, 식의 변환을 통해 사용할 수 있다.
- DBMS가 제공하는 내장함수(SUBSTR 등)가 사용될 때
- 널값에 대해서 일반적으로 사용하지 않는다.

KHU, SWCON