회복의 필요성
- 어떤 트랜잭션 T를 수행하는 도중에 시스템이 다운되었을 때, T의 수행 효과가 데이터 베이스에 일부 반영되었을 수 있다. (원자성 보장 필요)
- 트랜잭션 T가 완료된 직후에 시스템이 다운되면 T의 모든 갱신 효과가 주기억 장치로부터 디스크에 기록되지 않을 수 있다. (수행 결과를 반영하여 지속성을 보장해야 한다)
- 디스크의 헤드 등이 고장 나서 디스크의 데이터베이스를 접근할 수 없다면 어떻게 할 것인가?
회복의 개요
- 여러 응용이 주기억 장치 버퍼 내의 동일한 데이터베이스 항목을 갱신한 후에 디스크에 기록함으로써 성능을 향상시키는 것이 중요하다.
- 버퍼의 내용을 디스크에 기록하는 것을 가능하면 최대한 줄이는 것이 일반적
- 버퍼가 꽉 찼을 때 또는 트랜잭션이 완료됐을 때 버퍼 내용을 디스크에 기록
- 트랜잭션이 버퍼에는 갱신 사항을 반영했지만 버퍼의 내용이 디스크에 기록되기 전에 고장이 발생할 수 있다.
- 고장이 발생하기 전에 트랜잭션이 완료 명령을 수행했다면 회복 모듈은 이 트랜잭션의 갱신 사항을 재수행(REDO)하여 트랜잭션의 갱신이 지속성을 갖도록 해야 한다.
- 고장이 발생하기 전에 트랜잭션이 완료 명령을 수행하지 못했다면 원자성을 보장하기 위해서 트랜잭션이 데이터베이스에 반영했을 가능성이 있는 갱신 사항을 취소(UNDO)해야 한다
저장 장치의 유형
- 주기억 장치와 같은 휘발성 저장 장치에 들어 있는 내용은 시스템이 다운된 후 모두 사라짐
- 디스크와 같은 비휘발성 저장 장치에 들어 있는 내용은 디스크 헤드 등이 손상을 입지 않는 한 시스템이 다운된 후에도 유지된다.
- 안전 저장 장치 : 모든 유형의 고장을 견딜 수 있는 저장 장치를 의미한다.
- 2개 이상의 비휘발성 저장 장치가 동시에 고장날 가능성이 매우 낮으므로 비휘발성 저장 장치에 2개 이상의 사본을 중복해서 저장함으로써 안전 저장 장치를 구현한다.
재해적 고장과 비재해적 고장
재해적 고장
- 디스크가 손상을 입어서 데이터베이스를 읽을 수 없는 고장
- 재해적 고장으로부터의 회복은 데이터베이스를 백업해 놓은 자기테이프를 기반으로 한다.
비재해적 고장
- 그 이외의 고장
- 대부분의 회복 알고리즘들은 비재해적 고장에 적용된다.
- 로그를 기반으로 한 즉시 갱신, 로그를 기반으로 한 지연갱신, 그림자 페이징(shadow paging) 등의 여러 알고리즘이 있다.
- 대부분 상용 DBMS에서 로그를 기반으로 한 즉시 갱신 방식을 사용한다.
로그를 사용한 즉시 갱신
- 즉시 갱신에서는 트랜잭션이 데이터베이스를 갱신한 사항이 주기억 장치의 버퍼에 유지되다가 트랜잭션이 완료되기 전이라도 디스크의 데이터베이스에 기록될 수 있다.
- 데이터베이스에는 완료된 트랜잭션의 수행 결과 뿐만 아니라 철회된 트랜잭션의 수행 결과도 반영될 수 있다.
- 트랜잭션의 원자성과 지속성을 보장하기 위해 DBMS는 로그라고 부르는 특별한 파일을 유지
- 데이터베이스의 항목에 영향을 미치는 모든 트랜잭션의 연산들에 대해서 로크레코드를 기록
- 각 로그레코드는 로그 순서 번호(LSN : Log Sequence Number)로 식별된다.
- 주기억 장치 내의 로그 버퍼에 로그 레코드들을 기록하고 로그 버퍼가 꽉 찰 때 디스크에 기록한다.
- 로그는 데이터베이스 회복에 필수적이므로 일반적으로 안전 저장 장치에 저장된다.
- 이중 로그 : 로그를 2개의 디스크에 중복해서 저장하는 것
- 각 로그 레코드가 어떤 트랜잭션에 속한 것인가를 식별하기 위해서 각 로그 레코드마다 트랜잭션 ID를 포함시킨다.
- 동일한 트랜잭션에 속하는 로그 레코드들은 연결 리스트로 유지한다.
로그 레코드의 유형
[Trans-id, start]
- 한 트랜잭션이 생성될 때 기록되는 로그 레코드
[Trans-ID, X, old_value, new_value]
- 주어진 Trans-ID를 갖는 트랜잭션이 데이터 항목 X를 이전값(Old_value)에서 새 값(new_value)로 수정했음을 나타내는 로그 레코드
- Physical log record
Logical log record
- [trans-id, x, add, 7]과 같은 논리적인 연산 형태를 지니며 수행여부를 pageLSN으로 식별한다.
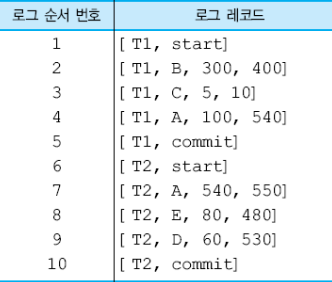
트랜잭션의 완료점
- 한 트랜잭션의 데이터베이스 갱신 연산이 모두 끝나고 데이터베이스 갱신 사항이 로그에 기록되었을 때
- DBMS의 회복 모듈은 로그를 검사하여 로그에 [Trans-ID, start] 로그 레코드와 [Trans-ID ,commit] 로그 레코드가 모두 존재하는 트랜잭션들을 재수행한다.
- [Trans-ID, start]로그 레코드는 로그에 존재하지만 [Trans-ID ,commit]로그 레코드가 존재하지 않는 트랜잭션들은 취소한다.
로그 버퍼
- append only / 로그 버퍼가 꽉 차면 디스크에 저장(FLUSH)하며, 저장된 버퍼에는 재사용이 가능하다.
로그 먼저 쓰기(WAL : Write – Ahead Logging)
- 트랜잭션이 데이터 베이스를 갱신하면 주기억 장치의 데이터베이스 버퍼에 갱신 사항을 기록하고, 로그 버퍼에는 이에 대응되는 로그 레코드를 기록한다.
- 만일 데이터베이스 버퍼가 로그 버퍼보다 먼저 디스크에 기록되는 경우에는 로그 버퍼가 디스크에 기록되기 전에 시스템이 다운되었다가 재가동되었을 때 주기억 장치는 휘발성이므로 데이터 베이스 버퍼와 로그 버퍼의 내용은 전혀 남아 있지 않게 된다.
- 로그 레코드가 없어서 이전 값을 알 수 없으므로 트랜잭션의 취소가 불가능하다.
- 따라서 데이터베이스 버퍼보다 로그 버퍼를 먼저 디스크에 기록해야 한다.
PageLSN (wal을 구현하기 위해서)
- 로그 버퍼의 내용을 디스크에 저장할 때, 항상 로그의 끝까지 저장하는 것은 오버헤드가 크다
- PageLSN(데이터 베이스 버퍼의 페이지 내에서 제일 마지막 업데이트 연산에 대응되는 로그LSN)을 포함하는 로그 버퍼의 블록까지 저장함으로써 오버헤드를 줄인다.
- FlushLSN : 디스크로 Flush한 마지막 LSN을 저장한다.
체크 포인트 필요성
- 시스템이 다운된 시점으로부터 오래 전에 완료된 트랜잭션들이 데이터베이스를 갱신한 사항은 이미 디스크에 반영되었을 가능성이 크다.
- DBMS가 로그를 사용하더라도 어떤 트랜잭션의 갱신 사항이 주기억 장치 버퍼로부터 디스크에 기록되었는가를 구분할 수는 없다.
- 따라서 DBMS는 회복시 재수행할 트랜잭션 수를 줄이기 위해서 주기적으로 체크포인트 수행
체크포인트 전략
- 체크포인트 시점에는 주기억 장치의 버퍼 내용이 디스크에 강제로 기록되므로, 체크포인트를 수행하면 디스크 상에서 로그와 데이터베이스 내용이 일치하게 된다.
- 체크포인트 작업이 끝나면 로그에 [checkpoint] 로그 레코드가 기록된다.
- 일반적으로 체크포인트를 1~20분마다 한 번씩 수행된다.
체크포인트를 할 때 수행되는 작업
- 수행 중인 트랜잭션들을 일시적으로 중지시키며, 회복 알고리즘(fuzzy 체크 포인트)에 따라서는 필요하지 않을 수 있다.
- 주기억 장치의 로그 버퍼를 디스크에 강제로 출력한다.
- 주기억 장치의 데이터베이스 버퍼를 디스크에 강제로 출력한다.
- [checkpoint] 로그 레코드를 로그 버퍼에 기록한 후 디스크에 강제로 출력한다.
- 체크포인트 시점에 수행 중이던 트랜잭션들의 ID도 [checkpoint] 로그레코드에 함께 기록한다.
- 일시적으로 중지된 트랜잭션의 수행을 재개한다.
데이터베이스 백업과 재해적 고장으로부터의 회복
- 데이터베이스가 저장되어 있는 디스크의 헤드 등이 고장나 데이터베이스를 읽을 수 없는 경우가 발생한다.
- 주기적으로 자기 테이프에 전체 데이터베이스와 로그를 백업하고, 자기 테이프를 안전하게 보관하는 법이 있다
- 사용자들에게 데이터베이스 사용을 계속 허용하면서, 지난 법 백업 이후에 갱신된 내용만 백업을 하는 점진적인 백업이 바람직하다.

KHU, SWCON