Auto-Encoding Variational Bayes
이제서야 다시 읽은 VAE.. 드디어 이 논문의 의의(?)를 조금이나마 이해하게 되었다.
작년에는 이걸 왜 이해하지 못했는지,,,
우선 VAE 논문의 main contribution은 두 가지였다는 것.
1) reparametrization trick을 통해서 일일 샘플링하지 않고 gradient method로 학습도 된다는 것이고
2) lower bound estimator를 통해서 approximate inference model을 효율적으로 제시했다는 것.
엄밀히 수학적 내용까지 모두 이해한 것은 아니지만, 일단 처음부터 시작을 해보자면
우리는 어떠한 데이터 X를 가지고 있다. 그리고, X랑 "비슷한" 데이터들을 생성하고 싶다.
그래서 AutoEncoder에서 아이디어를 얻어가지구, Z (latent variable)로부터 X를 decoder를 써서 생성해보고자 하였으나... 잘 안됐다.
너무나도 당연히 Z를 모르기 때문임ㅋ
우리는 X가 있다고 해서, Z를 알 수가 없다.
P(x)를 알아내서 X를 계속 생성해내고 싶은데 p(x)를 알 수가 없으니, p(x|z)p(z) z에 대해서 적분해서라도 구하고 싶은데 마찬가지로 p(x|z)를 모든 z에 대해서 적분할 수도 없음ㅋ
그래서.. p(x|z)를 가우시안 분포로 가정한다면??
결국엔 MSE LOSS가 돼서 잘 안되더라..
p(z|x)를 모사해볼 수는 없을까? 했는데 또 안됨ㅋ(당연함 p(x)를 알아야 쟤를 구할 수 있음)
그래서 시작된 게 이제 Encoder를 통해서 q_phi(z|x)를 추정해보자는 것이다. 왜냐면 우리가 데이터 X는 있으니까 일단 얘로부터 Z를 만드는 확률 분포부터 추정을 해보자. 요로케 돼서 Variational AutoEncoder가 탄생하게 되는 것이다.
결국 하고 싶은 건..
intractable posterior를 가지는 모델을 학습시키고 싶은 것.
결과적으로 p(X)를 만들고 싶은 거임 !!
그래서 logp(x)를 최대화하고 싶은 건데, p(z)p(x|z)dz를 적분하는게 불가능하니깐...
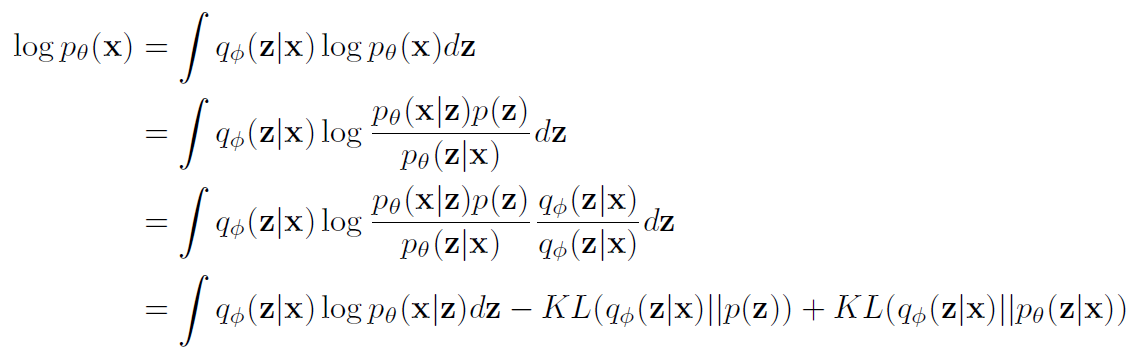
이런 식으로 식을 전개할 수 있게 되고, 마지막에 나와있는 KL Divergence 같은 경우는 우리가 추적할 수 없는 애들로 구성이 되어 있고 항상 0보다 크기 때문에 걔를 제외해서 lower bound를 만들 수 있게 됨

보면 알겠지만 Reconstruction error같은 경우는 input data X로부터 Z를 만들고(q_phi를 통해) 만들어진 Z로부터 다시 X를 복원하면서 학습이 됨
Regularization error 같은 경우는 p(z)와 q_phi(z|x)의 거리가 비슷해져야 한다는 건데 얘도 좀 단순한 식으로 정리가 됨..
그래서 논문을 읽을 때는 죄다 확률 분포고 뭐고 뭐고 무슨 말인지 잘 모르겠지만 결국엔 진짜 Sampling하면서 !! 하는게 아니라 parameter로 모사를 하는 것도 일종의 확률 분포를 학습하는 거라고 볼 수 있음
그리고 중요한 포인트는 우리가 이제 Z로부터 X를 복원해야 하는 건데. 우리는 q_phi(z|x)를 가우시안 분포로 가정을 했음. 그래서 결국에는 X를 복원할 때 가우시안 분포에서 원래대로라면 하나하나 다 샘플링을 해줘야하는데, 이건 오래 걸리기도 하고 결정적으로 gradient descent 방식을 사용할 수가 없음래대로라면 하나하나 다 샘플링을 해줘야하는데, 이건 오래 걸리기도 하고 결정적으로 gradient descent 방식을 사용할 수가 없음
그래서 나온 게 Reparameterization Trick이다.
처음 이 내요을 배웠을 때는 뭐가.. 다른 거지? 라고 생각을 했음 왜냐면 항상 나에게 가우시안 분포란,, 평균 + e * sigma 이런 꼴로 인식이 되었기 때문에 ..
근데 그건 나의 왜곡된 통계학 지식 때문인듯
여튼 원래대로라면 몬테카를로 샘플링처럼 많은 수를 일일이 샘플링해서 평균을 내는 방식으루 가야되는데 말이 안되기 때문에 이논문에서는 과감하게 샘플 하나만 뽑기루 했고 심지어 진짜 샘플링을 하기보다는 평균과 sigma 자체를 가져다가 epsilon만 랜덤샘플링해가지구 mu + e * sigma 이런 식으로 z를 계산했다 이말씀!
