LLaVA-SG: Leveraging Scene Graphs as Visual Semantic Expression in Vision-Language Models
Abstract
Scene Graph Expression을 VLM에 넣어서 혁신을 일으켜 보겠다.
Introduction
VLM은 query text와 image를 input으로 받아서 질문에 답변할 수 있음. 그런데 대부분 ViT를 이용하기 때문에 image를 fragmented patch로 인식하게 됨. 기존의 연구들은 suboptimal
따라서 본 논문에서는 visual model을 통해 image로부터 entity들을 추출하고, patch 단위가 아니라 eneity level에서 semantic 정보를 보존하고자 함.
catastrophic forgetting을 피하면서, LLaVA가 추출된 entity들 사이의 relationship을 구분할 수 있도록 해야함.
Method
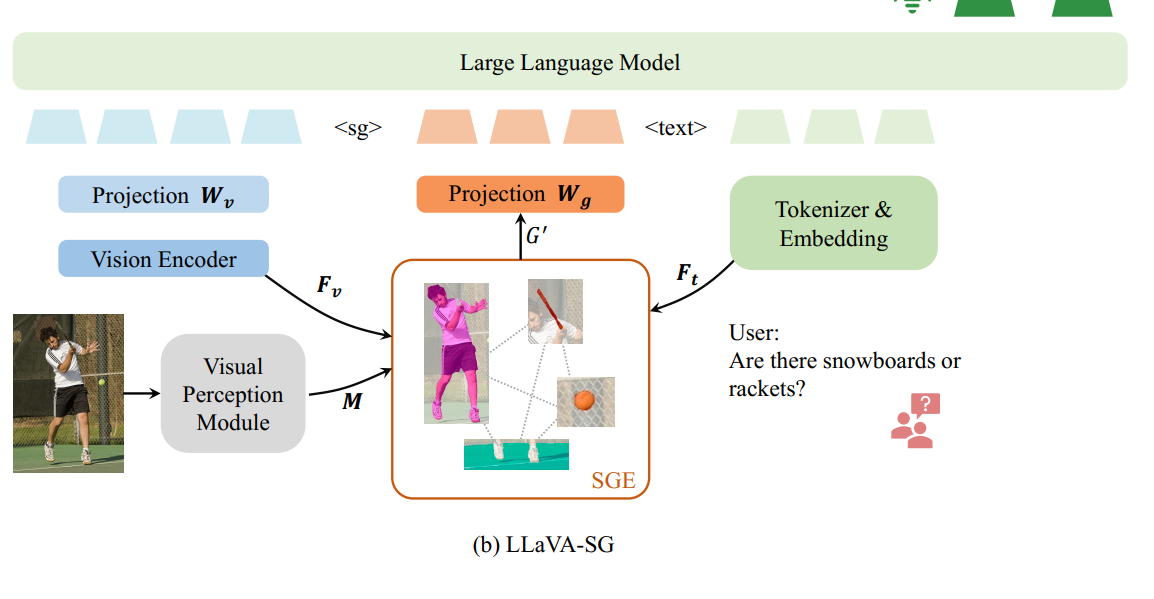
A. Semantic Information Expression
1) Visual Eneity Extraction:
Image로부터 entity들 추출하고, objtect detection module이 bounding box 생성
그다음 pixel-level의 semantic segmantation mask 생성
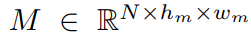
N개의 entity들에 대해서 hm, vm 크기의 mask
2) Scene Graph Expression
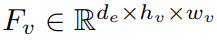
얘는 Input Image의 visual feature인데 (de는 Fv의 dimension이고 hv, wv는 feature map shape임!)
]
그러면 이제 mask의 각 point의 feature는 Fv에서 mask에 속하는 애들의 평균값. 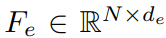
N개의 entity에 대해서 이러한 feature를 얻을 수 있게 됨. 그러면 이제 이러한 N개의 entity들을 node로보고 scene graph를 형성하면 됨
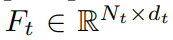
Prompt Feature 라는 것.. 얘를 활용해서 Scene graph의 key node를 활성화함. Attention 매커니즘을 활용해서 Ft를 Scene graph (G)에 넣고자 한다.
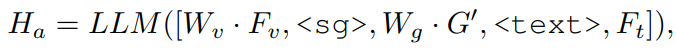
이런식으로 LLM에 넣어준다
Training
Visual Feature Alignment
image encoder와 LLM을 미리 학습된 모델 그대로 가져오고 freeze함 (Wv만 학습)
SGE training
SGE module과 Wg를 학습시키는데, 기존에 쓰이던 Visual Genome / Open Image V6 이외에도 open-vocabulary visual relationshipt understanding을 위해서 GRIT과 GPT를 활용했다.
Experiments
CLIP ViT-L을 vision encoder로 사용했고, Vicuna를 LLM으로 활용했다. image tagging을 위해서는 RAM 활용했고 Grounding-DINO를 활용해서 detection했고, SAM을 이용해서 semantic segmentation.

이런식으로 원래는 못맞추던 문제들을 SG 덕에 맞출 수 있게 되었다.
Conclustion
SGE용 data만을 추가해서 파인튜닝한다든가, SGE 모듈을 LLM하고 처음부터 end-to-end로 학습시킨다든가 하는 방법보다는 애초에 SGE 모듈을 따로 학습하고, 그다음 LLM과 함께 파인튜닝하는 방식의 성능이 가장 좋았따.
