2017년 WWW 억셉된 논문 사실 모델링이 현란하거나 그러진 않는데, Neural 네트워크를 CF에 적용한 첫 사례인가보다(??) 인용수:6814 추천에서 이정도면 엄청 높은 것 같은뎅,,,
INTRODUCTION
Collaborative filtering, 즉 사용자와 아이템 간의 상호작용의 시그널을 담아내는 방식은 주로 Matric Factorization 방법으로 구현된다.
이 방법은 user와 item을 latent space로 보내 vector로 표현하는 방식이고, user의 특정 item에 대한 상호작용은 user와 item latent vector의 내적으로 표현된다.
이때 내적은 단순히 latent feature의 곱이기 때문에 user interaction data의 복잡한 구조를 나타내는데 충분하지 않다 (저자의 주장),,,
근데 정말,, 추천에 복잡한 정보가 내재되어 있는게 맞을까? 그렇다면 트랜스포머를 통해 성능이 많이 향상되어야 하는 것이 아닐까
본 논문에서는 DNN을 써서 interaction function을 배우고자 한다. 지금껏 DNN을 추천에 쓰려는 시도들이 있었지만, 결국엔 MF,,,
implicit feedback 데이터를 활용
이 논문의 contribution은
1. Latent feature를 모델링하기 위한 neural network architecture를 제시하고, general framework NCF를 만들었다.
- MF가 NCF의 specialization이라는 것을 증명하였고,, MLP를 통해 NCF를 이끌어냈다.
- 두 개의 real-world 데이터셋에 대하여 NCF가 CF에 있어서 좋은 접근이라는 것을 증명했다.

1이면 유저와 아이템의 상호작용이 관찰된 경우, 0이면 관찰X
0이라고 꼭 부정적인 반응일 것이라고 할 수는 없지만, 당연히 관찰된 아이템보다는 선호도가 떨어질 것이라는 가정 (일단 흥미로워 보였으니 클릭을 했겠지,,, 하지만 클릭했지만 negative sample일수도 있고,,,,, 추천은 진짜 데이터셋이 제일 문제다,,,, 하지만 클릭을 유도하는 것이 추천 시스템의 목적이라면 이런 것도 positive로 분류하는게 맞는 것 같고
장기적인 사용자의 이용 시간을 증대하고자함이면 true positive만을 잘 골라야 함,, 아닌가 싫어하는 걸 더 잘 골라야 하나?? 그런 것 같기두 )
2.2 Matrix Factorization
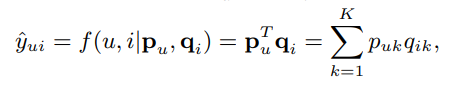
위에서도 언급했듯이, Matrix Factorization은 다음과 같이 유저와 아이템의 latent vector(Pu, Qi)를 곱해서 나온 값이 상호작용의 점수
이 논문에서 얘기하고 싶은 것은 inner product의 한계에 대해서 지적하고, 이를 Neural Network를 활용해 개선했다는 것이다
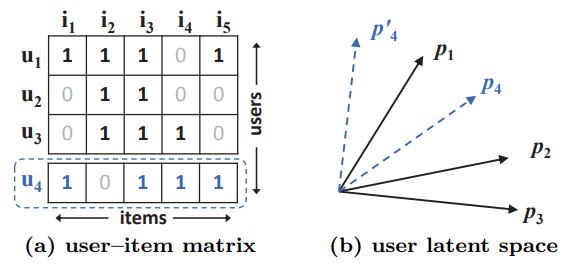
본 그림을 보면 u4의 경우, p1이랑 제일 비슷하다는 이유로 1b의 p4'처럼 그려진다면 나머지 2, 3에 대해서 순서가 맞지 않게 됨
따라서 MF에서 내적을 통해 최적화를 진행하다보면 latent vector의 최적화가 어려움,,ㅠㅠ,,,
근데 이게 inner product를 안쓴다고 해결될 문제일까?????,,,,,, 걍 차원을 추가해야하는 거 아닌감,,
맞네 바로 밑에 나옴 ㅋㅋ ㅠㅠ
이걸 해결하는 방법으로는 차원을 늘리는 방법이 있는데 차원이 커지면 추천 데이터셋은 sparse하기 때문에 오버피팅이 발생할 수밖에 없음T_T
따라서 본 논문에서는 DNN을 이용해서 interaction function을 배워보고자 함
3. Neural Collaborative Filtering
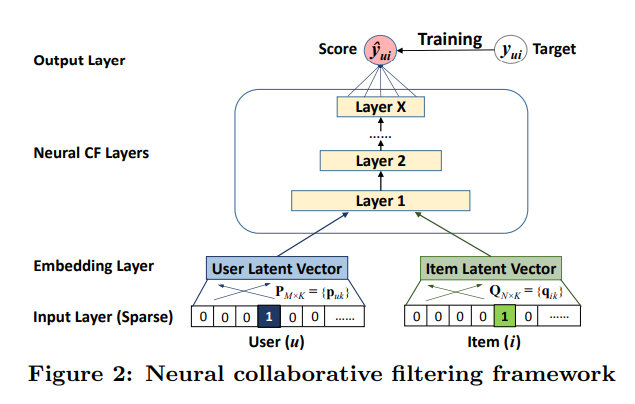
구조는 다음과 같이 생겼는데 Layer1에서 user와 item을 input으로 받는다. 이때 user와 item 페어 대신에 아이템의 컨텐츠 정보를 넣는다든가 하면 content based recommendation이 될 수도 있고, cold start 문제를 해결할 수도 있게 된다.
사실 이 논문을 다시 읽으면서 뭘 배워야할지.. 약간의 의문이 있었는데 (죄송합니다 죄송합니다,,) 잘 쓴 논문이 되려면 가져야할 요소?에 대해서 생각해볼 수 있었다.
물론 Matrix Factorization이 아닌 정말 순수한 DNN의 첫 도입이라는 의의도 있긴 하지만 이렇게 general하게 사용될 수 있도록 모델링을 해야한다는 것을 느꼈다.
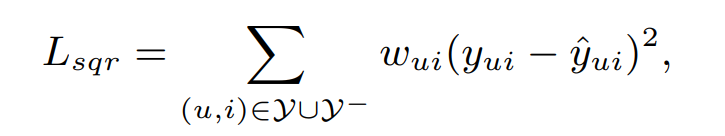
Loss function을 이처럼 pointwise로 계산하고자했지만, 이건 VAE에서 배웠던 것처럼 가우시안 분포를 가정했을 때 loss가 squared loss와 같아짐
따라서 squared loss는 어찌보면 가우시안 분포에서 나왔다고 추론할 수 있는 여지를 주게 되고 이는 implicit data를 활용한 경우에는 맞지 않음
왜냐면 1과 0. binary니까.
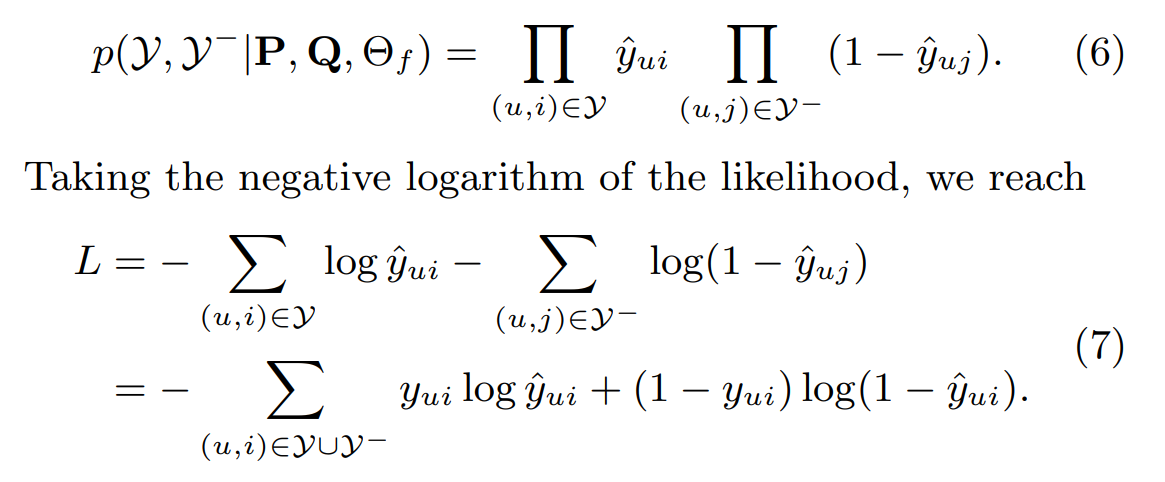
따라서 이 논문에서는 이런 식으로 binary classification처럼 loss를 구상하였다.
이게 참,, Log취하니까 덧셈이 되는 거지 그게 아니라 정말 전부 다 곱셈한다고 생각하면 정말 폭력적인 계산량이다.
그러니까 정말 CPU를 곱셈에 쓰는 건,,, 너무 낭비 같기도 하고
여튼 이런 간단해보이는 논문이지만 역시 정보이론 같은 수학 공부를 조금 해두어야겠다고 생각했다.
또한 보통 추천 연구에서는 classification aware log loss는 잘 사용하지 않는데, 4.3에서 그 effectiveness에 대해 탐색했다고 한다.
Negative Sampling
non-uniform하게 샘플링하는게 성능 향상에 더 좋지만 이 논문에서는 각 iteration마다 uniform하게 샘플링했다. 비율도 유지하면서
3.2 Generalized Matrix Facotirzation
자 그렇다면 이제 NCF로 MF를 만들 수 있음을 보여보자 layer 한 층인 NCF에 대해서
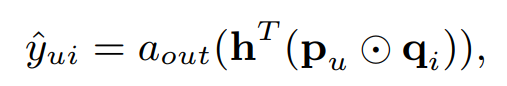
a를 identity function, h를 uniform vector1로 주면 얘는 결국 MF가 됨
(이 논문의 introduction에서 말했던 MF를 DNN으로 푸는 케이스)
만약 a를 통해 nonlinearity를 더한다면, 보다 general한 MF가 됨
이 논무에서는 sigmoid 사용
근데 대체... 시그모이드 더 뭐가 글케 대단한데.... 왜 자꾸 쓰이는 건데
미분했을 때 예쁘게 생겨서??
3.3 Multi-Layer Perceptron
Layer1에서 user와 item 벡터 두개를 받는데 이때 이 둘을 단순히 concat하는 것은 collaborative signal을 표현하는데 충분하지 않다. 따라서 concat한 벡터에 hidden layer를 추가해서 user와 item의 interaction을 충분히 배우도록 하고자 함
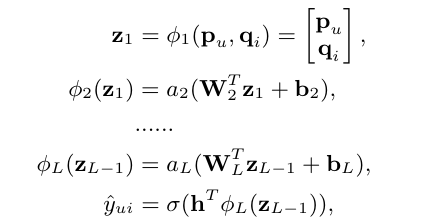
그래서 대략적으로 이렇게 Layer를 쌓아줍니당
3.4 Fusion of GMF and MLP
왜 이런 짓을,, 당연히 앙상블이 제일 좋지 않을까??
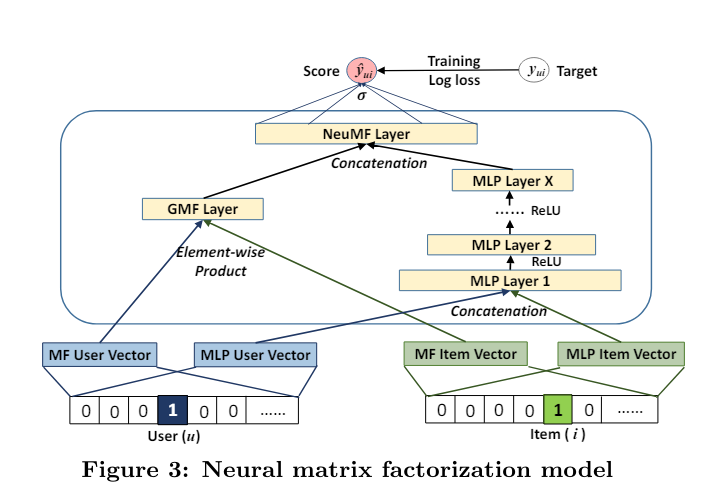
아주 간단하게는 user와 item 임베딩을 공유하면 된다.
하지만,, 단순 sharing은 어찌보면 fused model의 성능을 제한할 수도 있다. 왜냐면 GMF와 MLP의 optimal embedding size가 같은데 둘이 똑같이 해버리면 한쪽이 손해봄
그리고 초기화가 아주 중요하기 때문에!! pretrain된 GMF와 MLP에서 초기의 값들 가져옴 h에서만 (둘 다 있으니깐) 비율 alpha로 조정해서 가져옴
Experiments
- NCF가 정말 다른 CF 방법보다 성능이 좋은지?
- 어떻게 추천 태스크에서 동작하는지?
- 깊게 쌓는 것이 효과적일까?
Dataset

4.2 Performance Comparison (RQ1)
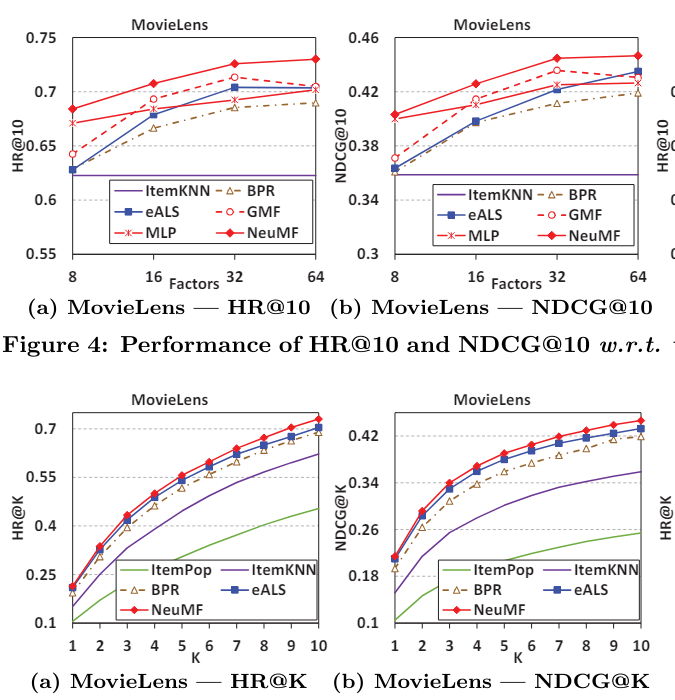
k도 이렇게 바꿔가면서 실험하고 전부 돌린게 신기하다 이게 바로 고전의 힘,,
4.2.1 Utility of Pre-training
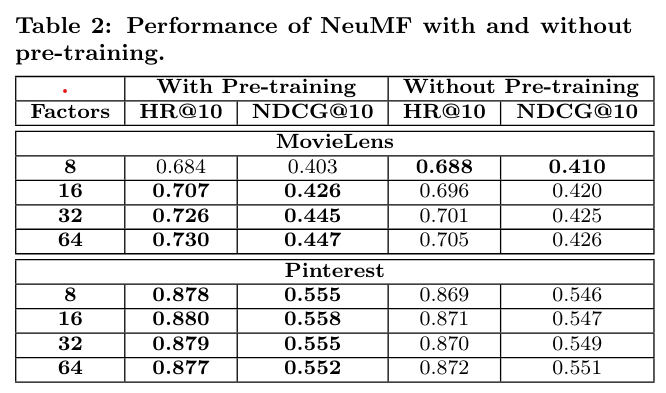
pretrain 했을 때 잘하더라
4.3 Log Loss with Negative Sampling (RQ2)
대부분 첫 10peoch까지 성능이 잘 향상되었다.
NeuMF > MLP > GMF 순으로 성능이 좋았다 (MLP로 MF 이김!!!!)
pairwise보다 pointwise가 좋은 이유는 샘플링에 더 유연하기 때문이다. pairwise의 경우 하나의 positive instance에 대해 하나의 negative sample을 비교할 수 있는데, (근데 이거 그냥 여러개 해버리면 되지 않남??) pointwise loss에서는 sampling ratio를 마음대로 조절할 수 있음(?)
겨우 negative sampling 비율이 한 개만으로는 충분하지 않다. 근데 또 너무 많이 뽑으면 성능이 떨어짐
의문인점
negative sample은 많으면 많을수록 좋은 거 아닌가??
=> 아마두 implicit data라서 그런 거 일수도 있겠다는 생각이 든다
근데 또 생각해보면 사실 sequential rec할 때도 다음에 봤을 때 임베딩을 비슷하게 만드는 건데 안보면 negative인 거니까,,,, negative 많을수록 좋아야하는 거 아닌가?? 혼란스럽다,,
4.4 Is Deep Learning Helpful? (RQ3)
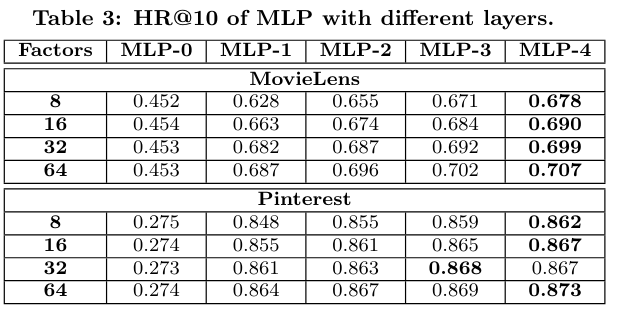
0층 쌓으면 ItemPoP보다 못하더라! 당연함,,
5. RELATED WORK
그동안은 explicit feedback 위주였으나 점점 implicit data 연구에 관심이 집중된다. (하지만 너무 옛날 논문이라 요즘엔,,, LLM 기반이니 사실 implicit으로 볼 수도 있을듯??)
왜냐면 Explicit feedback 쓸 때는 missing data를 아예 무시해야하는데 implicit에서는 negative로 해석하거나 missing data에서 negative를 샘플링함!
이제부터는 neural network를 사용했던 추천 연구에 대한 정리
- two-layer RBM 써서 user의 explicit rating 모델링
- 요즘엔 user-based AutoRec => 유저의 rating history 받아서 rating들 복원
(이런 연구는 user를 rated item들로 표현하는 item-item model가 비슷함) - unseen 데이터에 대해서 망가지는 것을 막기 위해 denoising autoencoder도 등장
여기까지 연구들은 CF 기반이고, explicit rating에만 포커싱했기 때문에 positive-only인 implicit data에 대해서는 학습이 불가능함
물론 이 이후에는 DNN을 implicit feedback 학습에 사용하긴 했지만 auxiliary information(아이템의 텍스트 정보같은 보조적인 정보들)만 모델링함
Collaborative Deep Denoising Autoencoder Framework for
Recommendations 논문이 가장 유사하지만 결국엔 SVD랑 같고 innner product한 거랑 똑같음,, 그렇기 때문에 deep layer가 효과가 별로 없었던 것!!!!!
하지만 이러한 구조랑 다르게 NCF의 경우에는 two path-way를 통해서 user와 item을 따로 feedforward 태웠기 때문에 파워풀하당,,
생각해볼만한 지점
- inner product를 너무나 당연시 여겼는데 사실 이런 것도 끊임 없이 의심해보고 굳이 이걸로 선택해야하는 이유가 있는가?? 질문을 던져볼 필요가 있다.
- 잘쓴 논문이란,, General한 것 (NCF, GMF, Fused model 이렇게 세가지로 다 제시한 것도 흥미롭고 어쨌든 확장성 있게 나름 layer층도 그렇고 다양한 실험을 해본듯하다.)
- negative sample ratio 또한 실험적으로 어떨 때 가장 효과적인지를 찾아야 하는 것을 보고 조금 두렵다,,
- Negative sample은 많으면 많을수록 좋을 거라고 생각했는데 그게 안통하는 경우도 있다. 그건 왜 그럴까?
지금은 7년전 논문 읽는 중,, 얼른 팔로업하쟈,,
