알아야할 개념이 매우 많다,,
Monte Carlo
확률 분포를 추정하고, 거기로부터 샘플링해서 loss function을 만드는 경우가 많은데 우리는 진짜 확률 분포를 구할 수 없고 무한 번의 sampling을 할 수도 없기 때문에 유한한 시도만으로 최대한 확률 분포를 추정하고자하는게 목표!
Markov Chain
확률이 바로 이전의 상태에 의해서만 영향을 받는다는 확률 과정
MCMC
https://angeloyeo.github.io/2020/09/17/MCMC.html
1. 추정하고자 하는 확률 분포가 있고, 일단 random initialize
2. 그다음 어디로 갈지 '추천' 받기
3. 추천을 거절 또는 승낙
4. 이동이동...
Restricted Boltzmann Machines (RBM’s)
visibile unit과 hidden unit이 있을 때, 각자 내부끼리는 연결이 없고 visible -> hidden 으로의 연결만 존재
(iid 가정으로 각각의 unit 확률 곱으로 표현하기 위해서)
구성요소
v, h
: visible / hidden layer
W
visible layer과 hidden layer 사이의 연결
b, c
visible과 hidden data의 내재적 특성 반영하는 bias
Energy
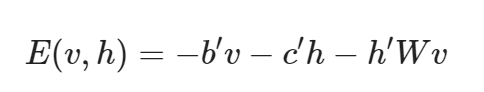 처음엔 softmax랑 비슷한 것 같아서 굳이 왜 energy라는 개념을 차용했는지 의아했는데, 아마도 Energy 라는 개념을 통해서 visible layer가 대부분 1인 경우와 같이 layer의 안정성이라는 개념을 반영해주기 때문인듯
energy 값이 낮을수록 안정하다.
결국 학습은 v (주어진 데이터)에서 h 뽑고, 뽑아진 h에서 다시 v'을 샘플링해서 v와 v'이 비슷해지는 방향으로
(AutoEncoder랑 매우 비슷하다 그래서 AutoRec에도 나온듯)
처음엔 softmax랑 비슷한 것 같아서 굳이 왜 energy라는 개념을 차용했는지 의아했는데, 아마도 Energy 라는 개념을 통해서 visible layer가 대부분 1인 경우와 같이 layer의 안정성이라는 개념을 반영해주기 때문인듯
energy 값이 낮을수록 안정하다.
결국 학습은 v (주어진 데이터)에서 h 뽑고, 뽑아진 h에서 다시 v'을 샘플링해서 v와 v'이 비슷해지는 방향으로
(AutoEncoder랑 매우 비슷하다 그래서 AutoRec에도 나온듯)

Es muss sein!