
Ridge Regression
1. One-hot encording 2. Feature selection 3. Ridge regression
1. One-hot encording
- One-hot encording
범주형- 명목형 = 순서가 없는 str데이터
명목형을 원핫 인코딩을 통해서 고유값을 컬럼으로 바꿔 0,1로 나타냄
- 주의
- 순서형과 헷갈리기 쉽다.
- 종류가 너무 많으면 쓰기 힘들다.
- 상관성이 발생 -> 생각해보기
- 순서형
- 명목형 = 순서가 없는 str데이터
#코드
#판다스 프로파일링 다운
!pip install -U pandas-profiling
#데이터 프로파일링 (카테고리 데이터 찾기)
df.profile_report()
#인코더 다운
!pip install category_encoders
#원핫 인코더 불러오기
from category_encoders import OneHotEncoder
from sklearn.model_selection import train_test_split
#원핫인코딩
encoder = OneHotEncoder(use_cat_names = True)
train = encoder.fit_transform(df)
test = encoder.transform(df)
#훈련, 테스트 데이터 나누기
x_train, x_test = train_test_split(
train, test_size=0.2, train_size=0.8, random_state=2
)
#타겟, 피쳐 나누기
y_train = x_train['target]
x_train = x_train.drop('target', axis = 1)
#test 피쳐, 타겟나누기
y_test = x_test['target]
x_test = x_test.drop('target', axis = 1)2. Feature selection
- 특성선택은 과제에 적합한 특성을 만들어내는 과정이다.
#코드
from sklearn.feature_selection import f_regression, SelectKBest
#셀렉터 지정(f검정 기준, 20개 선택)
selector = SelectKBest(score_func=f_regression, k=20)
#훈련데이터
X_train_selected = selector.fit_transform(x_train, y_train)
#테스트 데이터
X_test_selected = selector.transform(x_test)
#특성 전체 이름
all_names = x_train.columns
# selector.get_support()(선택된 특성을 bool로 나타내줌)
selected_mask = selector.get_support()
## 선택된 특성들
selected_names = all_names[selected_mask]
## 선택되지 않은 특성들
unselected_names = all_names[~selected_mask]
#feature list화
kss=[]
for i in selected_names:
kss.append(i)
#k=20 훈련데이터, 테스트데이터 만들기
x_train = x_train[kss]
x_test = x_test[kss]3. Ridge regression
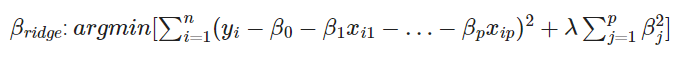
-
릿지회귀는 기존의 선형회귀에 튜닝파라미터(람다)를 추가
-
Ridge 회귀는 이 편향을 조금 더하고, 분산을 줄이는 방법으로
정규화(Regularization)를 수행합니다. 여기서 말하는 정규화는
모델을 변형하여 과적합을 완화해 일반화 성능을 높여주기 위한 기법을 말합니다.
-
람다가 증가할수록 정규화는 0으로 가까워진다.
#코드 # sklearn 버전 확인 -> 0.23보다 낮다면 재설치 진행. import sklearn sklearn.__version__ # sklearn 재설치 !pip uninstall scikit-learn -y !pip install -U scikit-learn # sklearn 버전 재확인 -> 0.23 이상으로 설치되었는지 확인 import sklearn sklearn.__version__ #from sklearn.linear_model import RidgeCV from warnings import simplefilter simplefilter(action='ignore', category=FutureWarning) #람다설정 alphas = [0, 0.001, 0.01, 0.1, 1] #릿지회귀 ridge = RidgeCV(alphas=alphas,normalize=True, cv=5) ridge.fit(x_train, y_train) from sklearn.preprocessing import PolynomialFeatures from sklearn.pipeline import make_pipeline X_total = pd.concat([x_train, x_test]) y_total = pd.concat([y_train, y_test]) def RidgeCVRegression(degree=3, **kwargs): return make_pipeline(PolynomialFeatures(degree), RidgeCV(**kwargs)) # 모든 데이터를 사용해 최종 모델을 만듭니다. model = RidgeCVRegression(alphas=alphas, normalize=True, cv=5) model.fit(X_total, y_total) coefs = model.named_steps["ridgecv"].coef_ print(f'Number of Features: {len(coefs)}') print(f'alpha: {model.named_steps["ridgecv"].alpha_}') print(f'cv best score: {model.named_steps["ridgecv"].best_score_}')
회고
오늘 많이 힘들었다. 하지만 많은 것을 배운 하루였다. 릿지회귀와 특성선택, 원핫인코딩에 대해서 배웠다. 원핫 인코딩은 이해하기 쉬웠다. 범주형을 0,1인 데이터로 바꿔주는 것이기떄문이다. 특성선택은 좀 더 공부해야겠다. 릿지회귀도 좀 더 공부해야겠다. 정말 재밌다 진짜 재밌다. 더 열심히 해서 쉽고 재밌게 느끼게 만들고 싶다. 일단 더 복습하는 것이 중요할 것 같다.

미래의 데이터 분석가~@