
Decision tree(결정트리)
- 파이프라인
- 결정트리
- 결정트리의 특성중요도
1. Pipeline
- 여러 ML 모델을 같은 전처리 프로세스에 연결시킬 수 있습니다.
- 그리드서치(grid search)를 통해 여러 하이퍼파라미터를 쉽게 연결할 수 있습니다.
- 전처리 과정의 간단화
from category_encoders import OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
#파이프라인(로지스틱_회귀)
pipe = make_pipeline(
OneHotEncoder(),
SimpleImputer(),
StandardScaler(),
LogisticRegression(n_jobs=-1)
)
#파이프라인 학습
pipe.fit(X_train, y_train)
print('검증세트 정확도', pipe.score(X_val, y_val))
#named_steps(파이프라인 스텝에 접근가능)
import matplotlib.pyplot as plt
#named_steps(로지스틱회귀)
model_lr = pipe.named_steps['logisticregression']
#named_steps(원핫인코딩)
enc = pipe.named_steps['onehotencoder']
#인코딩 후 컬럼추출
encoded_columns = enc.transform(X_val).columns
#계수와 특성
coefficients = pd.Series(model_lr.coef_[0], encoded_columns)
#시각화
plt.figure(figsize=(10,30))
coefficients.sort_values().plot.barh();
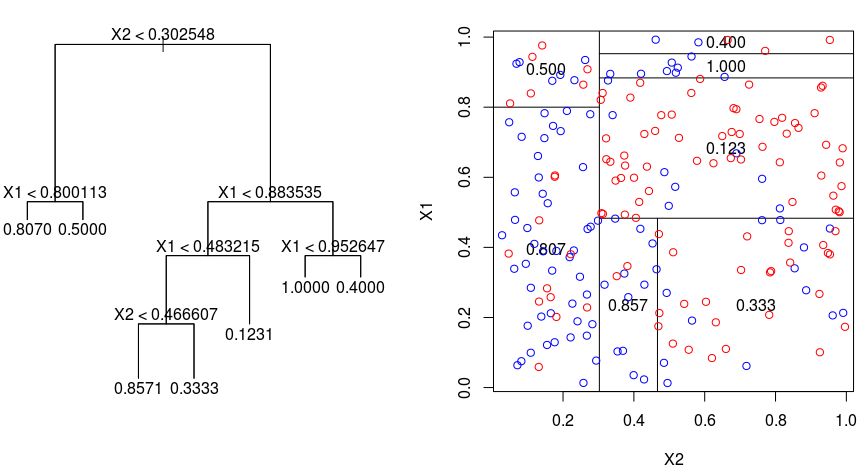
2. Decision tree(결정트리)
- 결정트리(의사결정나무) 모델은 특성들을 기준으로 샘플을 분류해 나가는데 그 형태가 나무의 가지가 뻗어나가는 모습과 비슷해서 결정트리라는 이름을 가지고 있습니다.
- 노드 : 뿌리노드, 중간노드, 말단노드로 나눌 수 있다.
- 결정트리는 분류문제와 회귀문제 둘 다 적용할 수 있다.
- 결정트리는 데이터를 분할해가는 알고리즘이다.
- 분류 과정은 새로운 데이터가 특정 말단 노드에 속한다는 정보를 확인한 뒤 말단노드의 빈도가 가장 높은 범주로 데이터를 분류합니다.
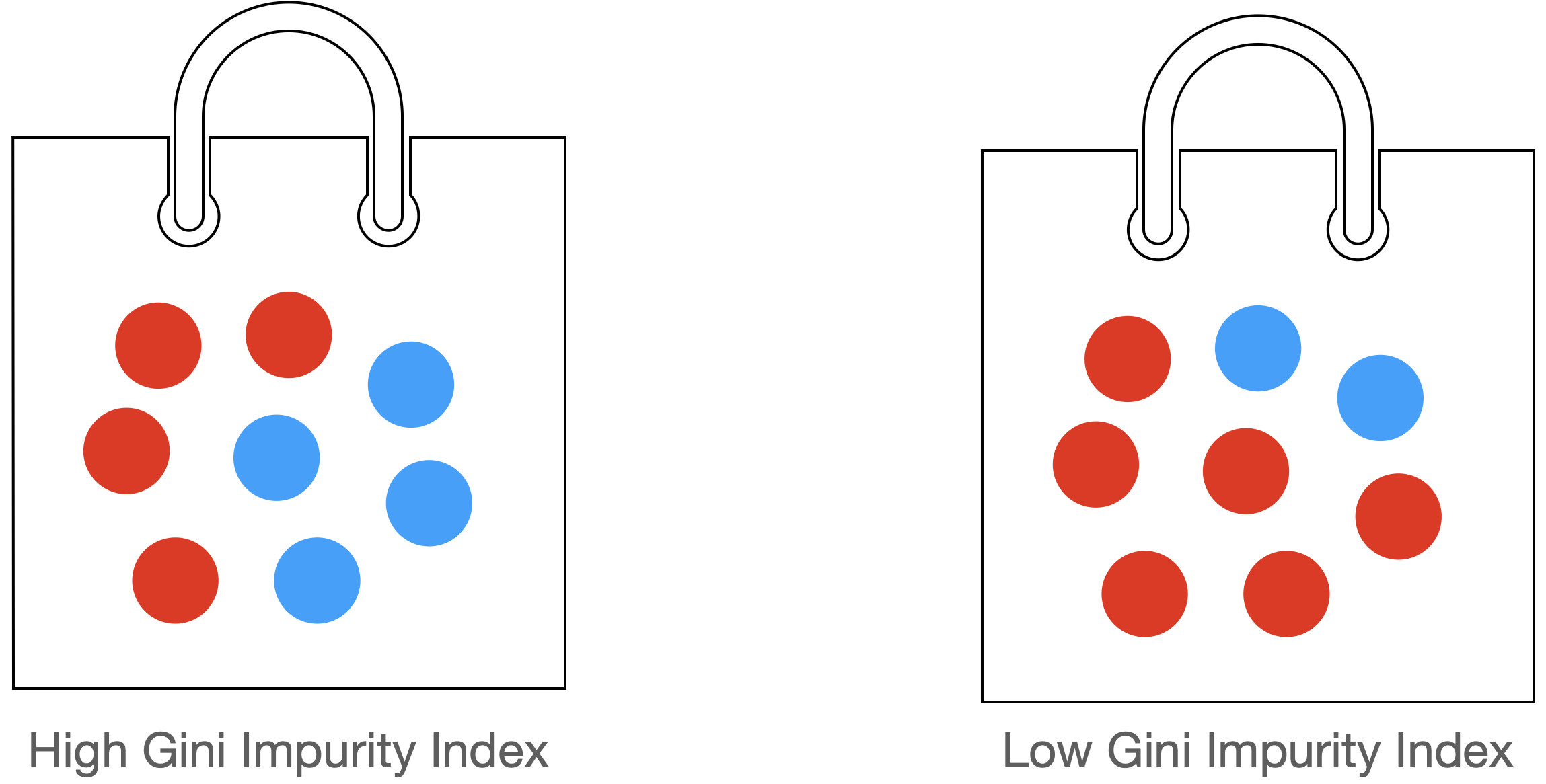
- 지니불순도와 엔트로피
- 불순도 : 불순도라는 개념은 여러 범주가 섞여있는 정도를 말한다
- 분할에 사용할 특성이나 분할지점(값)은 타겟변수를 가장 잘 구별해 주는(불순도의 감소가 최대가 되는, 정보획득이 가장 큰)것을 선택합니다.
- 정보획득(Information Gain)은 특정한 특성을 사용해 분할했을 때 엔트로피의 감소량을 뜻합니다.
from sklearn.tree import DecisionTreeClassifier
#파이프라인(결정트리)
pipe = make_pipeline(
OneHotEncoder(use_cat_names=True),
SimpleImputer(), #결측치 -> 평균
DecisionTreeClassifier(random_state=1, criterion='entropy')
)
#모델학습
pipe.fit(x_train, y_train)
- 과적합 해결
- max_depth = 트리의 최대 깊이입니다.
- min_samples_leaf = 리프 노드에 있어야 하는 최소 샘플 수입니다
- min_sampls_split = 내부 노드를 분할하는 데 필요한 최소 샘플 수
#과적합 해결 하이퍼파라미터
from sklearn.tree import DecisionTreeClassifier
#결정트리
DecisionTreeClassifier(
max_depth = default(= None),
min_samples_leaf = default(=1),
min_samples_split= default(=2),
random_state=1, criterion='entropy'
)3. 결정트리의 특성중요도
- 선형회귀모델에서는 회귀계수가 있다면 결정트리에서는 특성중요도가 있다.
- 특성중요도는 항상 양수값을 가진다.
- 이 값을 통해 특성이 얼마나 일찍 그리고 자주 분기에 사용되는지 결정됩니다.
- 결정트리모델은 선형모델과 달리 비선형, 비단조(non-monotonic), 특성상호작용(feature interactions) 특징을 가지고 있는 데이터 분석에 용의합니다.
회고
오늘 나는 당황함을 경혐했다. 어찌 설명을 듣고 들어도 잘이해가 안될까? 솔직히 지금도 약간 이해가 안가는 것도 있다. 특히 불순도 관련해서이다. 불순도가 낮게 만드는 특성을 사용한다. 하지만 특성중요도는 다르다. '특성중요도가 높으면 불순도를 낮게 만들어주는 특성인가?' 한 번 더 생각해보고 자야겠다.
잘못하더라도 계속하면 따라가진다. 하지만 생각을 계속해야한다. 생각없이 따라가면 다시 그 길을 가지 못한다. 하지만 생각을 하면서 따라간다면 다음에 다시 갈 때도 전자보다는 훨씬 효율적으로 따라갈 것이라고 자신한다.
항상 열심히 하자! 화이팅!

미래의 데이터 분석가~@