Database #Index
DB Index
- 목적: RDBMS에서 검색 속도를 높이기 위한 기술
- 테이블 내의 1개의 컬럼, 혹은 여러 개의 컬럼을 이용하여 생성될 수 있다
- RDB에서의 인덱스는 테이블 부분에 대한 하나의 사본으로 키-필드 값을 가지며 다른 세부 항목은 갖고있지 않다.
- 인덱스를 저장하는 데 필요한 디스크 공간은 보통 테이블을 저장하는 데 필요한 디스크 공간보다 작다.
- 키-필드 형식으로 저장하기 때문에 중복된 항목이 등록되는 것을 금지한다
=> 고유성 보장
Table의 컬럼을 indexing함
-> 해당 테이블의 레코드를 Full Scan 하지 않음으로써 B+ Tree 구조로 Index 파일 검색이 가능해져 검색 속도를 향상시킨다.
- 과정: 테이블을 생성하면 MYD, MYI, FRM 3개의 파일이 생성된다.
- FRM: 테이블 구조가 저장되어 있는 파일
- MYD: 실제 데이터가 있는 파일
- MYI: 인덱스 정보가 들어있는 파일
📎 인덱스를 사용하지 않는 경우, MYI 파일은 빈 상태이다.
📎 인덱싱하는 경우 MYI 파일이 생성되며 이후 사용자가 Select 쿼리로 index를 사용하는 컬럼을 탐색 시, MYI 파일의 내용을 검색한다.
- 단점
- 인덱스 생성시, .mdb 파일 크기가 증가한다.
- 한페이지를 동시에 수정할 수 있는 병행성이 줄어든다.
- 인덱스 된 필드에서 data를 업데이트하거나, 레코드를 추가 또는 삭제 시 성능이 떨어진다.
- 데이터 변경 작업이 자주 일어나는 경우, index를 재작성해야 하므로, 성능에 영향을 미친다.
https://hongjuzzang.github.io/db/db_index/
- 인덱스 관련 자료구조
📍 B-Tree(시간복잡도 O(logN))
- 일반적인 인덱스 구성 방법으로, 빠른 쿼리 동작과 검색을 위해 많은 양의 데이터를 저장하도록 설계된 자체 균형 트리 구조이다.
- 이진트리에서 발전되어 모든 리프노드들이 같은 레벨을 가질 수 있도록 자동 밸런스를 맞추는 트리이다.
- B-Tree는 노드에 여러 키-값을 가질 수 있고, 키 순서에 따라 오름차순으로 저장된다.
- 키의 삽입과 삭제 시 Merge Sort가 발생할 수 있다.
특징
📎 모든 노드는 최대 m개의 서브 노드를 가진다.
📎 루트 노드와 리프 노드를 제외한 모든 노드는 최소 m/2개, 최대 m개의 서브 노드를 가진다.
📎 노드의 자료 수가 k개라면 자식의 수는 k+1개여야 한다.
📎 모든 리프 노드는 같은 레벨에 나타나야 한다.
📎 한 노드안에 있는 키 값들은 오름차순을 유지한다.
📎 자료는 중복되면 안된다.
📍 B+Tree(시간복잡도 O(logN))
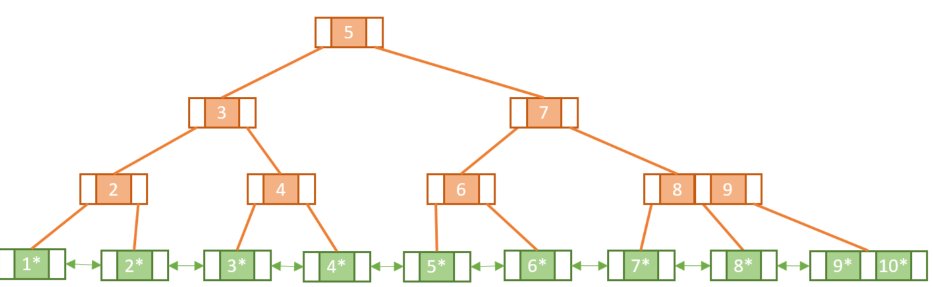
(주황색 노드는 index node, 초록색 노드는 data node)
- Index node: 리프 노드에 있는 키 값을 찾아갈 수 있는 라우터 역할(키만 있음)
- Data node: 리프 노드끼리 연결리스트로 형성되어있고 data를 가지고 있음
📎 루트 노드와 리프 노드를 제외한 모든 노드는 최소 m/2개, 최대 m개의 서브 노드를 가진다.
📎 루트 노드는 0 또는 2 ~m개의 서브 노드를 가진다.
📎 노드의 자료 수가 k개라면 자식의 수는 k+1개여야 한다.
📎 모든 리프 노드는 같은 레벨에 나타나야 한다.
📎 한 노드 안에 있는 키 값들은 오름차순 정렬되어 있다.
📎 Data node 내의 리프 노드들은 모두 링크로 연결되어 있다.
💡 비교
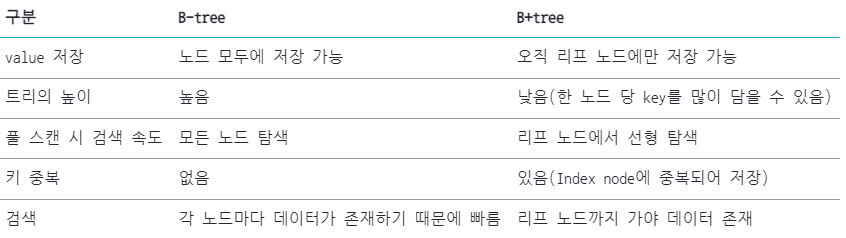
B-Tree vs B+Tree
- 리프 노드를 제외하고 데이터를 담지 않기 때문에 메모리 확보가 가능하다.
- 하나의 노드에 더 많은 키를 담을 수 있어서 트리의 높이는 낮아진다.(cache hit 높일 수 있음)
- 풀 스캔 시, B+Tree는 리프노드에 데이터가 모두 있기 때문에 한번 선형 탐색하면 되므로 B-Tree에 비해 속도가 빠르다
📍 Hash Index (시간복잡도 O(1))
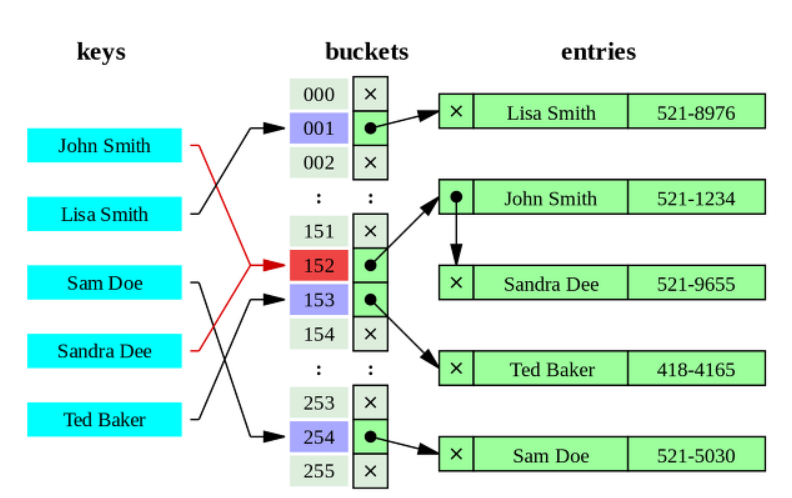
- 디스크 기반의 대용량 테이블용으로는 사용하지 않으나, 메모리 기반의 테이블에 주로 구현되어 있다.
- 빠른 검색을 제공하지만 키값 자체가 변환되어 저장되기 때문에 범위를 검색하거나 원본값 기준으로 정렬 불가능하다.
- 동등 비교 검색에는 최적화돼 있지만 범위 검색, 정렬 결과 가져오는 목적으로는 사용 불가능하다.(B-Tree를 DB 자료구조로 사용하는 이유)
- 다중 컬럼으로 생성된 해시 인덱스에서도 모든 컬럼이 동등 조건으로 비교되는 경우에만 인덱스를 사용할 수 있다.
- Clustered Index vs Non Clustered Index
[출처]
- 인덱스 단편화 & 인덱스 리빌딩
[출처]
https://bebeya.tistory.com/entry/MSSQL-%EC%9D%B8%EB%8D%B1%EC%8A%A4-%EB%8B%A8%ED%8E%B8%ED%99%94-%ED%99%95%EC%9D%B8-%EB%A6%AC%EB%B9%8C%EB%93%9C-%EC%A7%84%ED%96%89-100-%ED%9A%A8%EA%B3%BC
https://datalibrary.tistory.com/128
https://velog.io/@sweet_sumin/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4-%EC%9D%B8%EB%8D%B1%EC%8A%A4-%EB%A6%AC%EB%B9%8C%EB%93%9C%EA%B0%80-%ED%95%84%EC%9A%94%ED%95%9C-%EC%9D%B4%EC%9C%A0
- DBMS 의 인덱스는 항상 정렬된 상태를 유지하기 때문에 원하는 값을 탐색하는데는 빠르지만 새로운 값을 추가하거나 삭제, 수정하는 경우에는 쿼리문 실행 속도가 느려진다.
- 결론적으로 DBMS 에서 인덱스는 데이터의 저장 성능을 희생하고 그 대신 데이터의 읽기 속도를 높이는 기능이다.
