Context engineering evolution
LLM (대규모 언어모델)이 단순한 명령 수행 시스템에서 복잡하고 다면적인 애플리케이션의 핵심 추론 엔진으로 진화함에 다라, 이들과 상호작용하는 방식또한 발전하고 있다.
Prompt engineering이라는 용어는 기본 개념으로 중요하지만 현대 AI system이 요구하는 정보 payload의 설계, 관리, 최적화를 포괄하기에는 부족하다. 그 이유는, 이러한 시스템이 하나의 고정된 문자열 텍스트만을 처리하지 않으며, 동적이고 구조화된, 다면적인 정보흐름을 활용하기 때문이다. 이에 대응하기 위해서 'Context Engineering' 이라는 새로운 개념이 생겨나게 되었다.

What is Context engineering?
Context Engineering을 공식적으로 정의하기 위해서 먼저 autoregressive LLM의 표준 확률모델을 알 필요가 있다. 파라미터 세타로 정의된 이 모델은 입력 컨텍스트 C가 주어졌을때, 출력 sequence Y를 다음의 조건부 확률을 최대화하도록 생성한다.
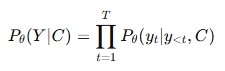
기존의 프롬프트 엔지니어링 패러다임에서는 컨텍스트 C를 단일하고 정적인 텍스트 문자열로 취급하였다. 즉, C = prompt라는 단일 개체로 보았다. 그러나 이러한 관점이 현대의 complex한 system에서는 더 이상 맞지 않았다. Context engineering은 C를 동적으로 구조화된 정보 component 집합으로 재 개념화 한다. 이러한 component들을 일련의 함수들에 의해 획득, 필터링, 포매팅되며 최종적으로 고수준의 조립함수 A에 의해 조율(orchestration)되게 된다.
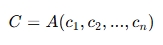
여기서 각 component ci는 임의로 정해지는 것이 아니고 참고한 survey 논문에서 다루는 핵심적인 기술영역들과 직접적으로 연결된다. 예를들어, 시스템 명령어 및 규칙, 외부지식(Rag, knowledge graph), 사용 가능한 외부 도구들의 정의 및 시그니처, 이전 상호작용으로부터 축적된 영속적 정보, 사용자, 세계, 또는 멀티에이전트 시스템의 동적 상태, 사용자의 현재 요청이 있다.
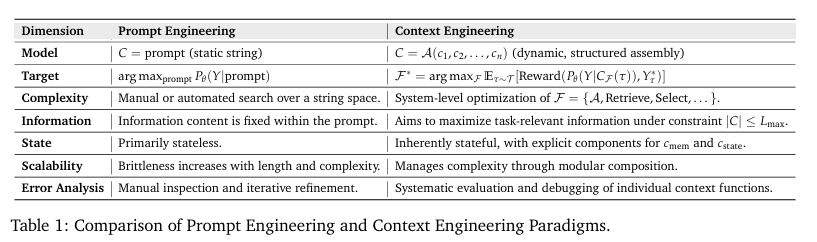
Context engineering은 전통적인 prompt engineering과의 근본적이 차별점을 두고 있다. Context engineering은 정교하고 문맥인식이 가능한 AI system을 설계, 이해, 최적화 하기 위해서 필요한 형식적이고 체계적인 framework를 제공한다. prompt design에서 art --> 정보 물류와 시스템 최적화의 science 로의 관점으로 전환한다고 볼 수 있다.
Context scaling
컨텍스트 스케일링은 문맥 정보처리의 범위와 정교함을 결정짓는 두가지 근본적인 dimension으로 구성된다.
1. Length scaling
ultra-long sequence 처리를 위한 연산적, 구조겆인 과제이다. 이는 수천~수백만의 token 까지 context window를 확장하면서도 긴 이야기, 문서, 상호작용 전반에 걸쳐 coherent understanding을 유지하는것을 목표로 한다.
이를 위해서는 sophisticated attention mechanisom, 메모리 관리 기술, 구조적인 혁신이 필요하다. 이들은 모델이 광범위한 input sequence에서도 문맥적인 일관성을 유지할 수 있게 한다.
2. Multimodal and structural scaling
두번째로는 단순한 text를 넘어서는 context 확장을 의미한다. 이는 다차원적이고 동적인 cross-modal 정보구조를 포함한다. 시간 순서에 따른 관계와 시퀸스의 이해인 시간적 컨텍스트, 위치기반 및 기하학적 관계해석의 공간적 컨텍스트, 여러 개체의 변화 상태를 추적하는 참여자 상태, 목표, 동기, 암묵적 목적을 이해하는 의도기반 컨텍스트, 특정 사회적,문화적 맥락에서의 의미를 해석하는 문화적 컨텍스트가 있다.
현대의 Context engineering은 이 두가지 fundamental dimentions들을 동시에 해결할 수 있어야 한다. 실제 애플리케이션에서는 단지 긴 텍스트 뿐만이 아니라 다음과 같은 다양한 데이터 유형을 동시에 처리해야 하기 때문이다.
- 구조화된 지식 그래프
- 다중모달 입력 (텍스트, 이미지, 오디오, 비디오)
- 시간적 시퀸스
- 인간이 자연스럽게 이해하는 암묵적 문맥 신호 등
이라한 다차원적 접근 방식은 단순히 모델 파라미터수를 늘리는 scaling을 넘어 인간 지능이 복잡한 현실세계를 이해하는 방식에 가까운 시스템을 구축하려는 근복적인 방향 전환을 의미하게 된다.
Why Context engineering?
현재 대규모 언어모델(LLMs)은 고도화된 컨텍스트 엔지니어링 접근법이 반드시 필요한 기술적 한계에 직면해 있다. 예를들어, self-attention mechanism은 sequence 길이가 늘어날수록 계산량과 메모리 사용량이 제곱 비율로 증가하기 때문에, 긴 context를 처리하는데에 있어서 심각한 장벽이 되고 있다. 이에 따라 chatbot이나 여러 모델의 실제 응용에 부정적인 영향을 미치고 있다. 특히 상용 서비스에서는 동일한 context를 반복적으로 처리해야하기 때문에 추가 latency와 토큰 기반의 과금 비용이 더해져 이러한 문제를 악화시킨다. 계산 자원 문제이외에도 여러 단점들이 존재하고 있다. 빈번한 hallucination(환각), 입력 문맥에 대한 불성실한 응답, 입력 변화에 대한 민감한 반응, 구문적으로는 맞지만 의미적으로 일관성이 없는 응답이 이 있다. 또한 기존의 prompt engineering은 근사기반(approximation-driven)이거나 주관적인 방식에 의존하고 있어서 모델의 개별적인 행동차이를 충분히 고려하지 못하는 경향이 있다. 하지만, 정확하고 풍부한 문맥이 담긴 프롬프트 작성은 모호성을 줄이고 응답의 일관성을 높이기 때문에 프롬프트 엔지니어링은 여전히 중요하다.
고급 context engineering 기법들 (e.g, In-Context Learning, Chain-of-Thought, Tree-of-Thought, Planning)은 정교한 언어 이해 및 생성 능력의 기반이 되며 검색 및 생성 최적화를 통해 강력한 문맥인식 AI응용을 가능하게 한다. 향후 logit Contrast를 활용한 chain-of-thought 보강, 다양한 문맥 유형의 효과적 활용, 특히 코드 인텔리전스 분야에서의 문법, 의미, 실행 흐름, 문서화를 통합, 고도화된 필터링 및 선택 메커니즘을 통해 Transformer 구조의 스케일링 한계 극복 등 성능의 품질을 유지하면서도 확장 가능한 LLM 시스템 개발의 핵심 경로가 된다.
Foundational Components
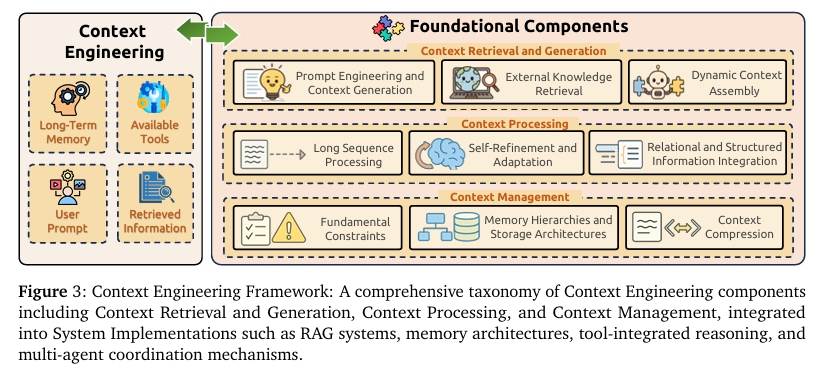
Context Engineering은 대규모 언어 모델에서 정보관리를 위한 핵심적 과제를 해결하기 위해 설계된 세가지 기본 구성 요소를 기반으로 구축된다.
- Context Retrieval and Generation (문맥 검색 및 생성)
프롬프트 설계, 외부지식 검색, 동적 문맥 조립 등을 통해 적절한 문맥 정보를 수집 - Context Processing (문맥 처리)
획득된 정보를 최적화하고, 긴 시퀸스를 처리하며, 구조화된 데이터를 통합 - Context Management (문맥 관리)
메모리 계층 설계, 압축 기술 개발등을 통해 문맥 정보의 효율적인 조직과 활용을 담당
아래는 Artificial Analysis에서 발표한 공식 자료이다. 빅테크 기업들의 LLM을 비교분석하였다. 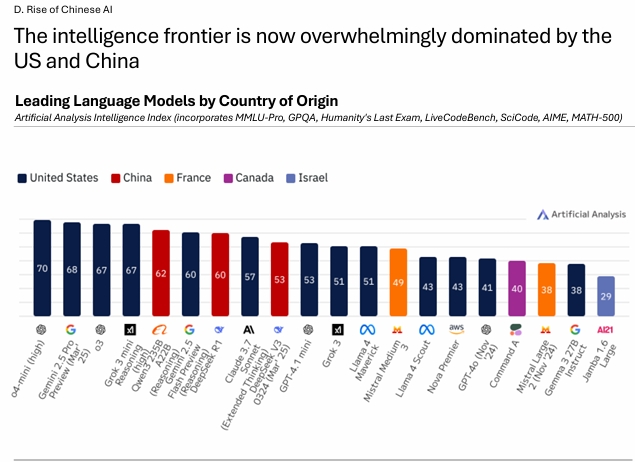
2025년 보고서에 의하면, 대부분의 AI 모델들의 경우, 현재 미국과 중국이 압도적인 점유율을 차지하고 있는것을 볼 수 있다.
미국은 추론 기반의 모델에서 선두자리를 지키고 있다. Aritificial Analysis의 intelligence index 기준, 상위 4개의 모델은 모두 미국연구소의 추론 모델이다. 중국의 경우, 비 추론 모델 부문에서 1위를 하였는데, DeepSeek V3 0325가 현재 non-reasoning 부문에서 최고 성능의 모델로 미국 및 타국 모델들을 앞서고 있다. 하지만 그 외 국가들에서는 점진적인 발전이 이루어지고 있지만, 아직 최첨단의 frontier 지능 모델 경쟁에서는 주요한 위치를 차지하지 못하고 있다.

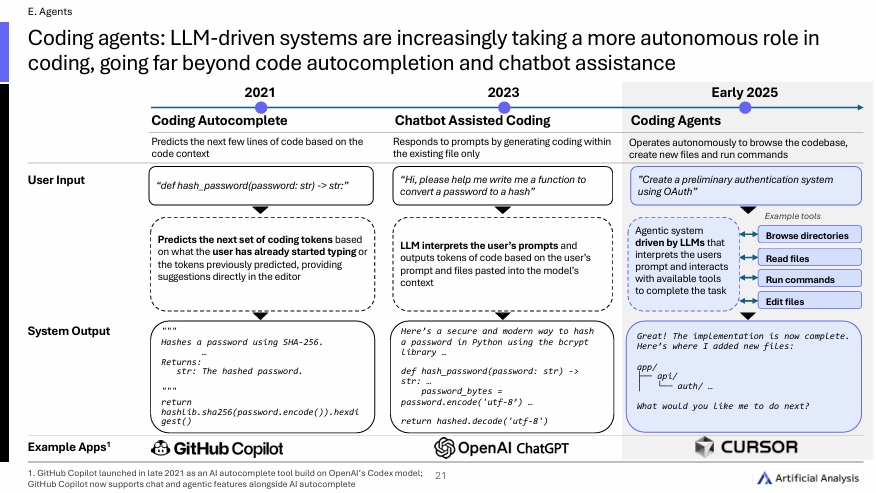
현재는 위그림처럼, 사용자의 프롬프트를 해석하고, 사용 가능한 도구들과 상호작용하여 주어진 작업을 수행하는 LLM 기반의 agent system으로 변화하였다.
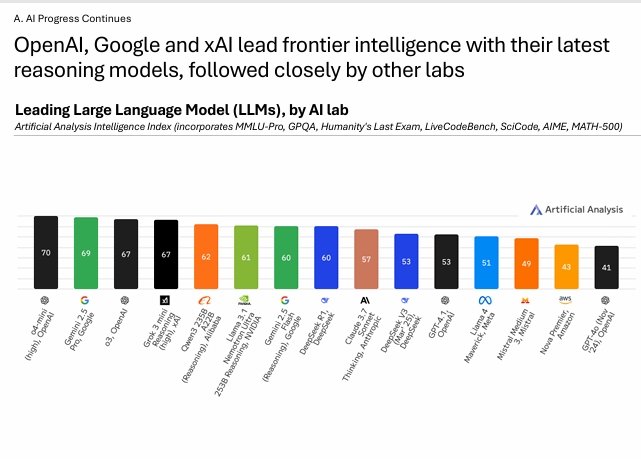
Open AI는 여전히 선두를 지키고 있고, o3와 o4-mini-high 모델은 최첨단 지능 모델로 평가되고 있다. 구글의 Gemini 2.5 pro도 매우 근접한 수준이다. 높은 intelligence index를 기록한 모델은 공통적으로 thinking을 거쳐 답변하는 추론 기반의 모델이기 때문에 '추론 능력'이 핵심적인 경쟁력이라고 볼 수 있다. 2025년 초 기준 미국의 주요 5대 연구소 (Open AI, Google, Anthropic, sAI, Meta)에 대해 NVIDIA, DeepSeek, Alibaba, Mistral, Amazon도 frontier 모델 대열에 합류하였다. 여기서 핵심 경쟁력이라고 볼수 있는 Reasoning에 대해 부연설명을하기 위해 아래의 그림을 첨부하겠다. 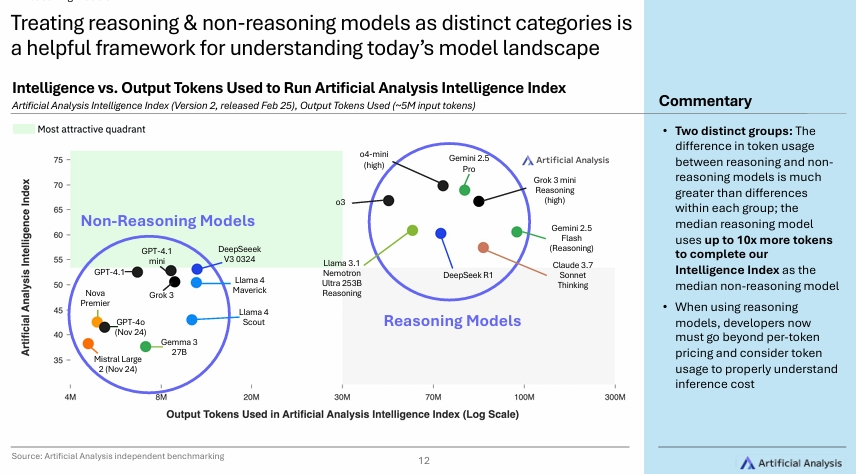
해당그림에서는 뚜렷하게 두 그룹으로 Reasoning model vs non-reasoning model로 나뉘게 된다. Reasoning model은 평균적으로 Non-reasoning model보다 최대 10배 더 많은 토큰을 사용하여 intelligence index를 수행하기 때문에 모델간의 성능 비교분석에서 'token efficeincy'도 매우 중요한 기준이 될 수 있음을 보여준다.
단순히 토큰 단가만으로는 reasoning 모델의 실제 비용을 제대로 파악할 수 없다. 이제는 총 토큰 사용량과 조합하여 총 추론비용을 계산해야 합리적인 의사결정이 가능할 수 있다. 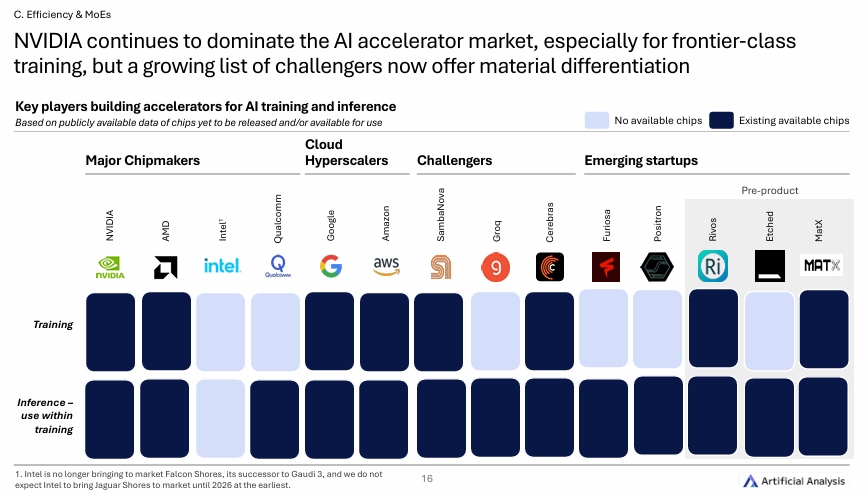
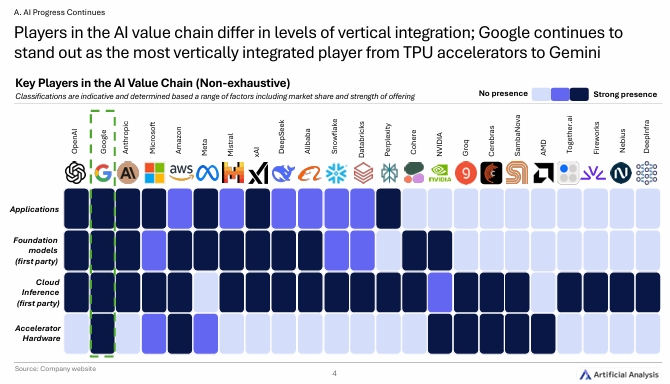
AI 모델의 성능은 하드웨어에도 크게 좌우된다. 여전히 NVIDIA가 독보적인 점유율을 자랑하고 있다.
Reference
A Survey of context Engineering for Large Language Models
Artificial Analysis AI Adoption Survey Report H1 2025
Artificial-Analysis-State-of-AI-Q1-2025-Highlights-Report
The architecture of today's LLM applications
