Document digitization이란?
Document digitization은 문서를 정보 검색이나 요약과 같은 후속 작업을 위해 텍스트, HTML, Markdown 등의 기계가 읽을 수 있는 형식으로 변환하는 과정을 의미한다.
Upstage에서 제공하는 Document digitization 기술에는 2가지가 있다.
Document parsing
문서 레이아웃 분석과 함께 텍스트를 감지하고 인식하여, 문서를 HTML 또는 Markdown과 같은 structured, LLM-readable 형식으로 변환하는 기술.
Document OCR
문서에서 text를 감지하고 인식하며, 각 text의 location 정보까지 함께 추출하는 기술.
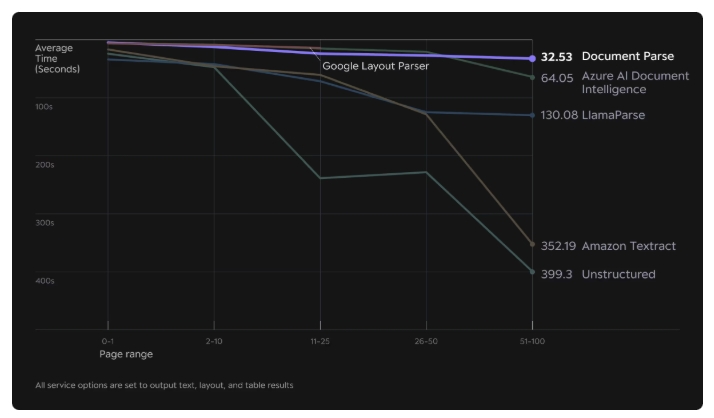
해당 글에서는 Document parsing에 대해서 좀 더 구체적으로 다루어 보려고 한다. 해당 기술은 Multi-page documents 에서 압도적인 속도를 자랑하는데, Upstage Document Parse는 100페이지 문서를 1분 이내에 처리한다. 50–100페이지 범위의 문서를 동일한 설정으로 처리하는 경우, 경쟁 서비스인 Unstructured와 AWS Textract보다 평균 10배, LlamaParse보다 평균 4배 더 빠른 성능을 보였다.
So what exactly is Document parsing?
Document parsing은 어떤 문서든 자동으로 HTML 또는 Markdown과 같은 구조화된 텍스트로 변환하는 과정을 말한다.
이 과정에서는 문서의 문단, 표, 이미지 등 레이아웃 요소를 감지하여 문서의 구조를 파악한다. 이후 API가 읽기 순서에 따라 요소들을 직렬화하고, 최종적으로 문서를 구조화된 텍스트로 변환한다. 현재 2가지 모델을 사용할 수 있다.

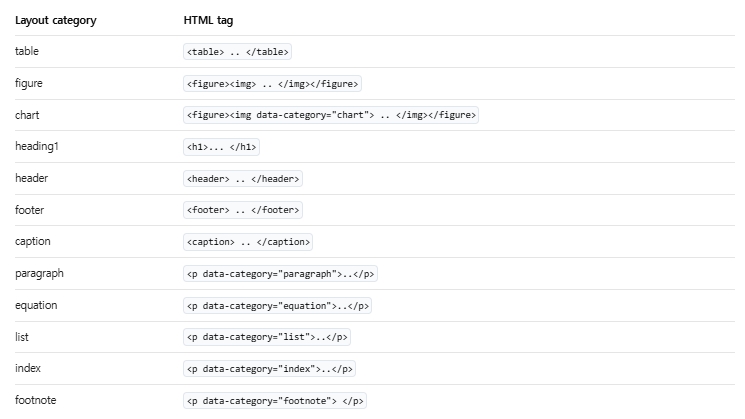
Upstage Document Parse는 입력문서에서 다양한 레이아웃 카테고리를 식별하고 이를 HTML tag로 변환한다.
아래 표는 문서 내 레이아웃 카테고리와 각각에 매핑되는 HTML tag를 설명한다. 만약 특정 레이아웃 카테고리에 적절한 tag가 존재하지 않으면, 모델이 감지한 레이아웃 유형을 설명하기 위해 "p" tag에 data-category 속성을 추가하여 표현한다.

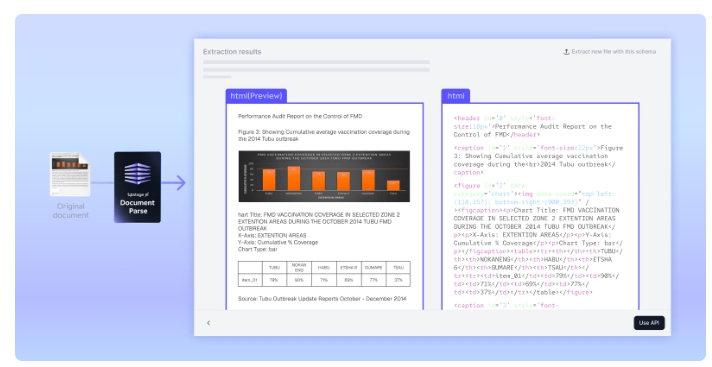
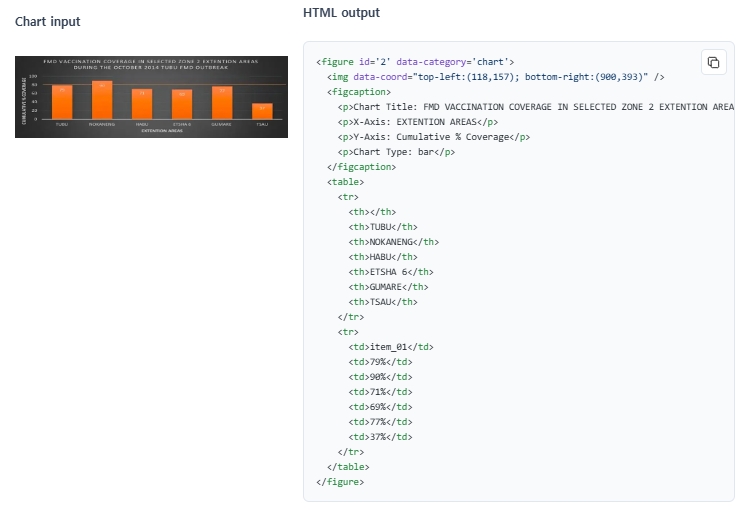
문서 안의 차트에는 유용한 정보가 포함되어 있지만, 일반적으로 이미지로만 파싱되기 때문에 검색, QA, RAG 같은 작업에서 활용하기 어렵다.
차트에서 수치 데이터를 추출해 table로 변환하면 기존의 텍스트 기반 파이프라인과 자연스럽게 통합되며, 차트 정보를 효과적으로 활용할 수 있다.
멀티모달 LLM을 사용해 이 문제를 해결할 수도 있지만, 비용이 더 높고 파이프라인이 복잡해지는 단점이 있다. 반면 Upstage Document parse의 경우 텍스트 기반 LLM과 호환되는 방식이 더 효율적이다. 차트 인식 기능은 아래에 제시된 차트 유형들을 감지하고 표 형식으로 변환한다.
다음과 같이 여러 페이지에 걸쳐 존재하지만 동일한 구조를 가진 표를 자동으로 감지하고 병합하는 기능 또한 제공한다.
이 기능을 활성화하려면 요청 시 merge_multipage_tables=true parameter를 설정하면 된다.
표가 병합되면, 연결된 표들 중 첫 번째 표 요소에 전체 내용이 통합되고, 이후 병합된 다른 표 요소들은 병합 결과가 반영된 상태로 업데이트된다.긴 데이터 표가 page 구분으로 인해 여러 페이지에 걸쳐 나뉘어 있을 때, page 경계를 넘더라도 데이터의 연속성을 유지해야 할 때 특히 유용하다.

Upstage console "playground"기능을 활용해서 Document parsing 기능을 사용해보겠다.
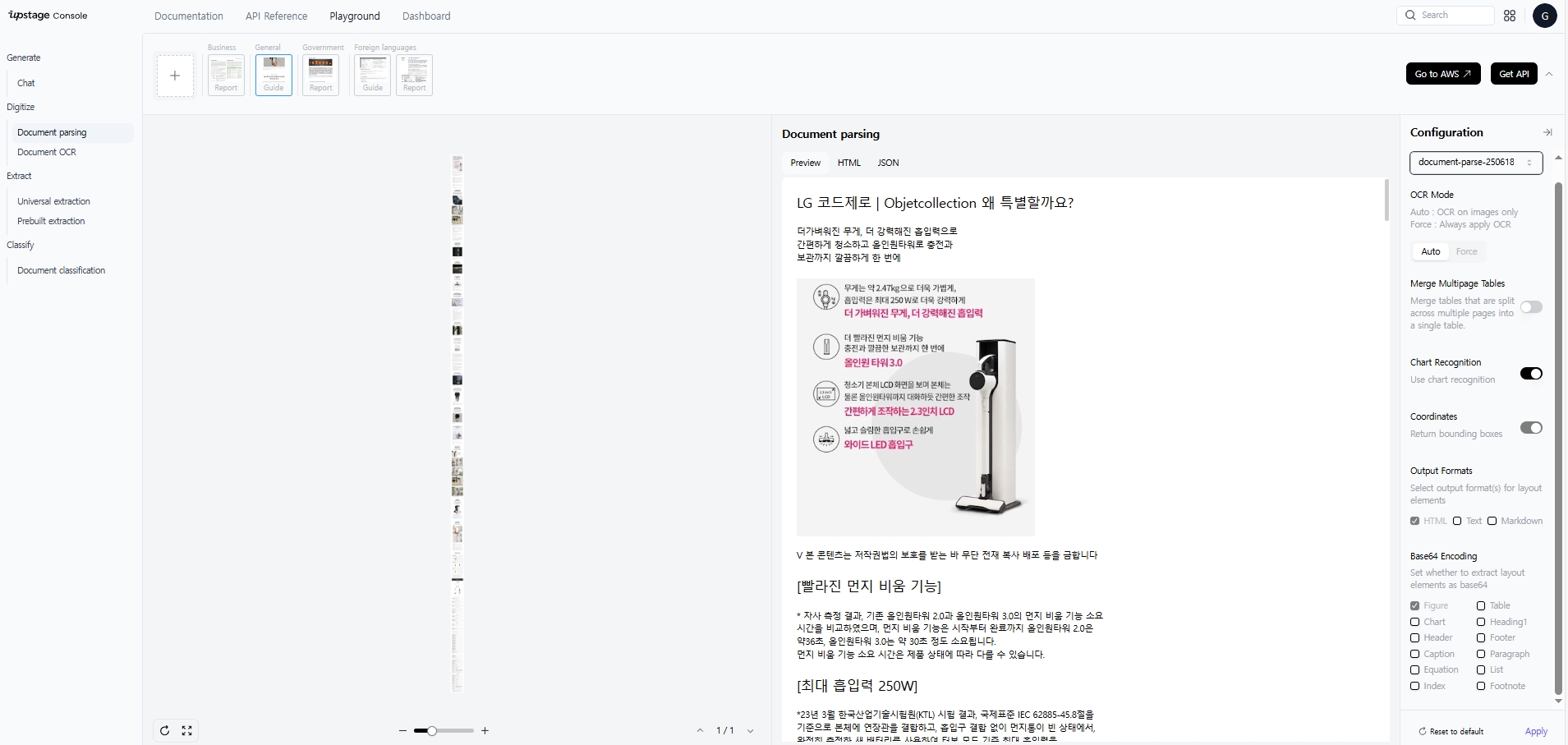
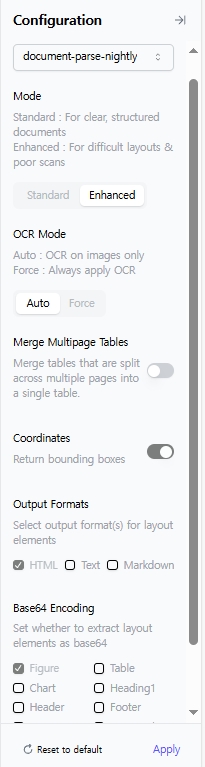
우측의 "Configuration" 설정 창에서 document-parse-250618, document-parse-nightly 모델 2가지 중에서 하나를 선택해서 사용하면 된다. Document parse의 경우 2가지 mode가 있는데, "Standard", "Enhanced" 둘 중 하나를 선택할 수 있다. 구조가 명확하고 정돈되어 있는 문서는 "Standard" 모드를 선택하면 되고, 만약 레이아웃이 복잡하거나 scan quality가 낮은 문서의 경우에는 "Enhanced" 모드를 선택하면 된다. 다만, 최근에 출시된 "Enhanced" mode 같은 경우에는 document-parse-nightly 모델을 선택해야지만 사용가능하다. 상세하게 옵션을 살펴보면, 위에서 언급했던, "Merge Multipage Tables" 기능도 활성화하여 사용할 수 있는 모습을 볼 수 있다.
Reference
https://console.upstage.ai/docs/capabilities/digitize
https://console.upstage.ai/docs/capabilities/digitize/document-parsing
https://console.upstage.ai/api/document-digitization/document-parsing
https://developers.llamaindex.ai/python/cloud/llamaparse/
https://console.upstage.ai/playground/document-parsing
https://www.upstage.ai/blog/en/let-llms-read-your-documents-with-speed-and-accuracy
https://www.upstage.ai/blog/en/difference-of-ie-and-dp
https://docs.reducto.ai/parsing/configs/enrich-configuration
