EXISTS 연산자
EXISTS: 특정 컬럼값이 존재하는지 여부를 확인한다.
- 한 테이블이 다른 테이블과 관계가 있을 때 유
- 조건에 해당하는 데이터의 존재 여부를 판단 후 더 수행하지 않는다
→ SELECT절까지 가지 않는다- (SELECT에서 * 대신 아무 문자나 입력해도 무관)
- 쿼리 순서 :
메인 쿼리 → EXISTS 쿼리
ex. 한번이라도 주문한 적이 있는 고객을 알고싶은 경우
SELECT * FROM 고객 WHERE exists(SELECT 1 FROM 주문 WHERE 주문.고객ID = 고객.고객ID)
IN 연산자
IN: 괄호 안의 값 혹은 서브쿼리의 결과가 포함되는지 여부를 확인
- 조건에 해당하는 컬럼 값을 직접 비교하여 체크
- SELECT절에서 조회한 컬럼 값을 바탕으로 비교
- 쿼리 순서 :
IN 쿼리 → 메인 쿼리
ex. 한번이라도 주문한 적이 있는 고객을 알고싶은 경우
SELECT * FROM 고객 WHERE 고객ID in(SELECT 고객ID FROM 주문)
EXISTS과 IN 비교
- SELECT절 까지 가 컬럼 값을 직접 비교하는 IN과 다르게
- 컬럼 값의 존재여부(TRUE/FALSE)만 판단하는 EXISTS가 일반적으로 성능이 좋다.
- 그러나 대용량 데이터를 조회할 것이 아니라면 성능은 보통 비슷하다
EXISTS와 JOIN 비교
EXISTS와 JOIN을 비교 하려면 INNER JOIN과 EXISTS가 어떻게 동작하는지 더 상세하게 알아봐야 할 것 같다.
예)
고객테이블에서 한번이라도 주문을 한 고객을 조회해보자
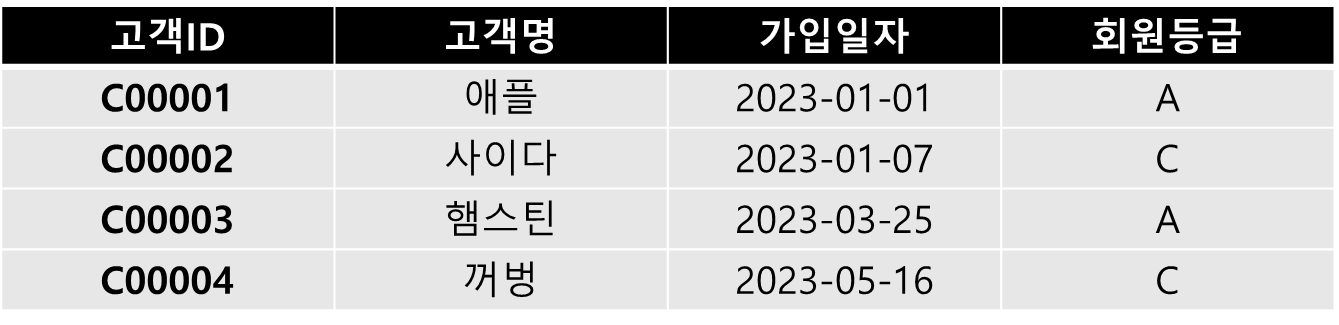
- 고객테이블
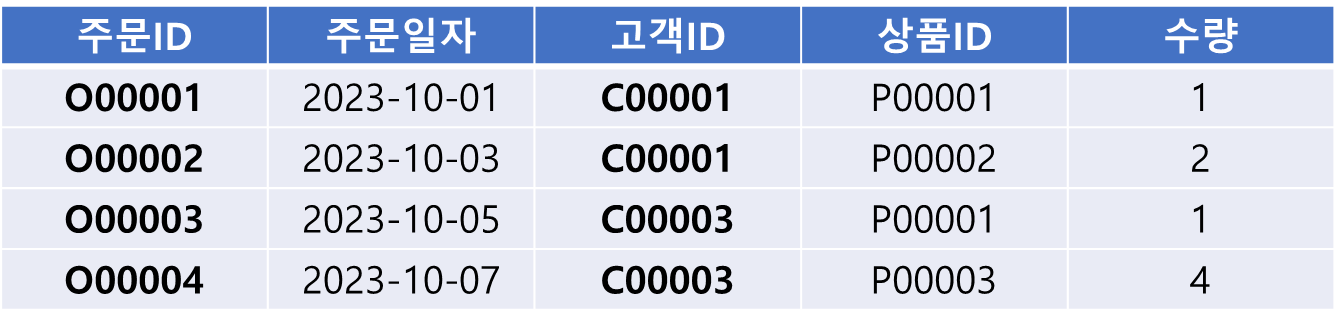
- 주문테이블
EXISTS의 경우는 Inner Query를 만족하는 데이터를 처음 만나면 true를 반환하며,
그 이후 중복된 데이터에 대해서는 확인하지 않는다.SELECT * FROM 고객 WHERE EXISTS(SELECT 1 FROM 주문 WHERE 주문.고객ID = 고객.고객ID)
- EXISTS 동작방식
- 결과
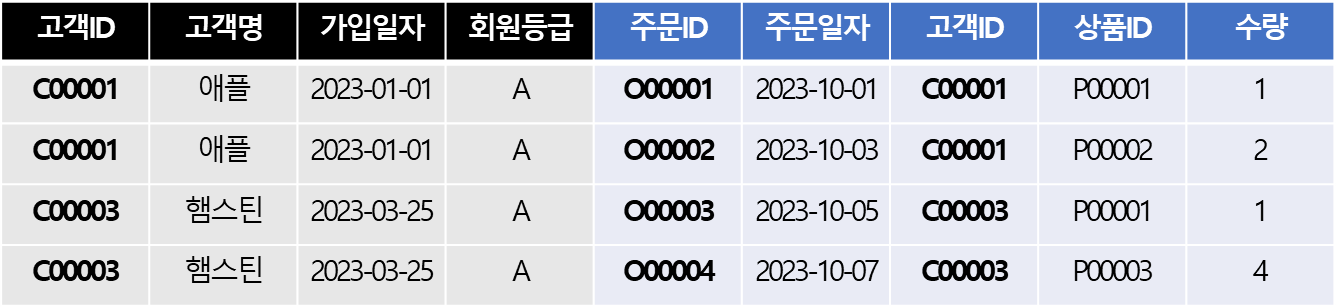
JOIN은 모든 레코드에 JOIN을 하고,
출력결과보다 많은 임시데이터가 생성되며 DISTINCT도 해줘야 하므로
1:N 관계에서 1에 해당하는 테이블을 조회할 때에는 비효율적이다SELECT DISTINCT 고객.* # 고객테이블의 정보만 필요하므로 중복 제거 필요 FROM 고객 INNER JOIN 주문 ON(고객.고객ID = 주문.고객ID)
- INNER JOIN
- 고객테이블 데이터만 조회 + 중복 항목 제거



EXISTS와 JOIN 비교
- 보통의 경우에는 INNER JOIN이 유리하겠지만,
Inner Query에 중복된 데이터가 많을 경우에는 EXISTS가 유리하다.
정리
IN:
조회하는 데이터가 많지 않을 경우는 성능이 비슷함(몇백 ~ 몇천), IN절 내부의 리스트가 100건이 넘어갈 경우는 비추.
EXISTS:
대용량 데이터 조회, 두 테이블 간의 관계가 1:N 일 때 1에 해당하는 테이블 조회 시 유리
INNER JOIN:
일반적인 경우 성능이 제일 우수하나, 가독성이 떨어지고 작성 시간 소요

시리즈나 태그목록으로 보시는게 좋습니다