1. 배경
AWS 서비스를 이용하여 ETL 작업을 진행하는 시스템에서 모니터링이 구축되어있지 않아 운영하는데 어려움을 겪고 있습니다. 사용하는 AWS 서비스로는 Lambda(300여개) , API Gateway, Glue(200여개 ),S3 입니다. 초기에는 당연히 AWS 서비스를 모니터링 하기 위한 목적인 Cloudwatch가 가장 적합하다고 생각하였지만 Dashboard 를 구성하면서 사용이 어렵고 속도가 느려 불편함을 겪었습니다. 이를 위해 다양한 모니터링 툴에 대한 POC의 필요성을 느꼈고 진행하며 공부한 내용에 대해 기록합니다. AWS 환경은 테스트용으로 샘플 API Gateway, Lambda, s3를 생성하여 대쉬보드를 구성하였습니다.
2. Cloudwatch Dashboard 구성
Cloudwatch의 가장 큰 장점을 별다른 작업 없이 바로 모니터링을 수행 할 수 있습니다. 아래와 같이 기본적으로 제공하는 Lambda 대쉬보드를 이용하였을 때 발생 횟수, 수행 시간, 에러 횟수 등을 모니터링 할 수 있는 화면을 제공합니다.
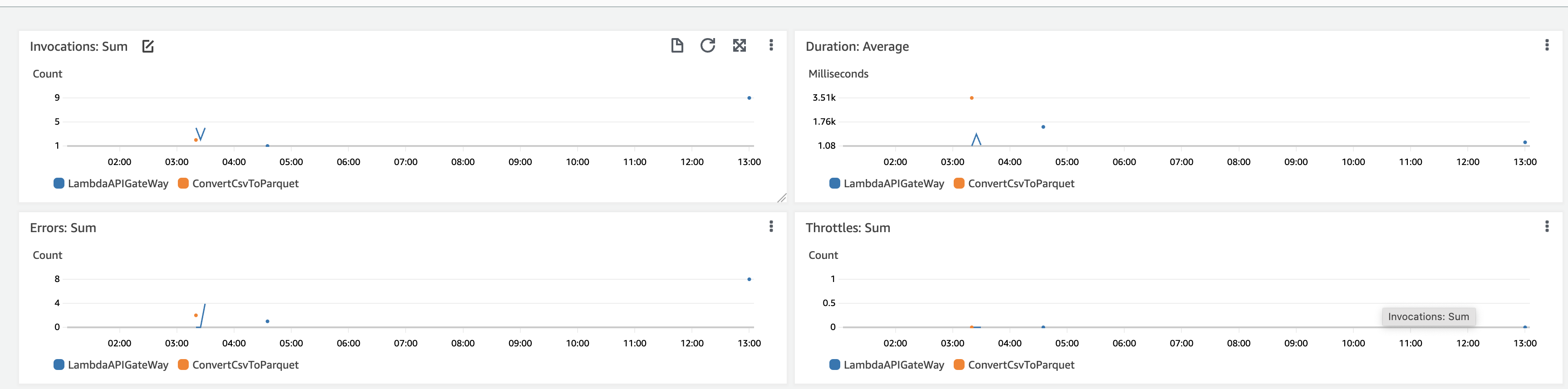
Cloudwatch에서 Metric과 로그두 종류의 데이터를 관리하는데 위젯을 생성할 때 이를 바탕으로 그래프를 생성할 수 있습니다. 그렇기 때문에 Log 데이터를 쿼리하는 방법이나 Metric 사용 방법을 숙달해야합니다. 아래 예시와 같이 지표를 통해 위젯을 추가하는 경우 Metric을 구분하는 네임스페이스(AWS/Labmda)를 선택한 후 Schema(함수이름별) 를 지정하면 해당 범위내에서 발생하는 Metric을 조회 할 수 있습니다.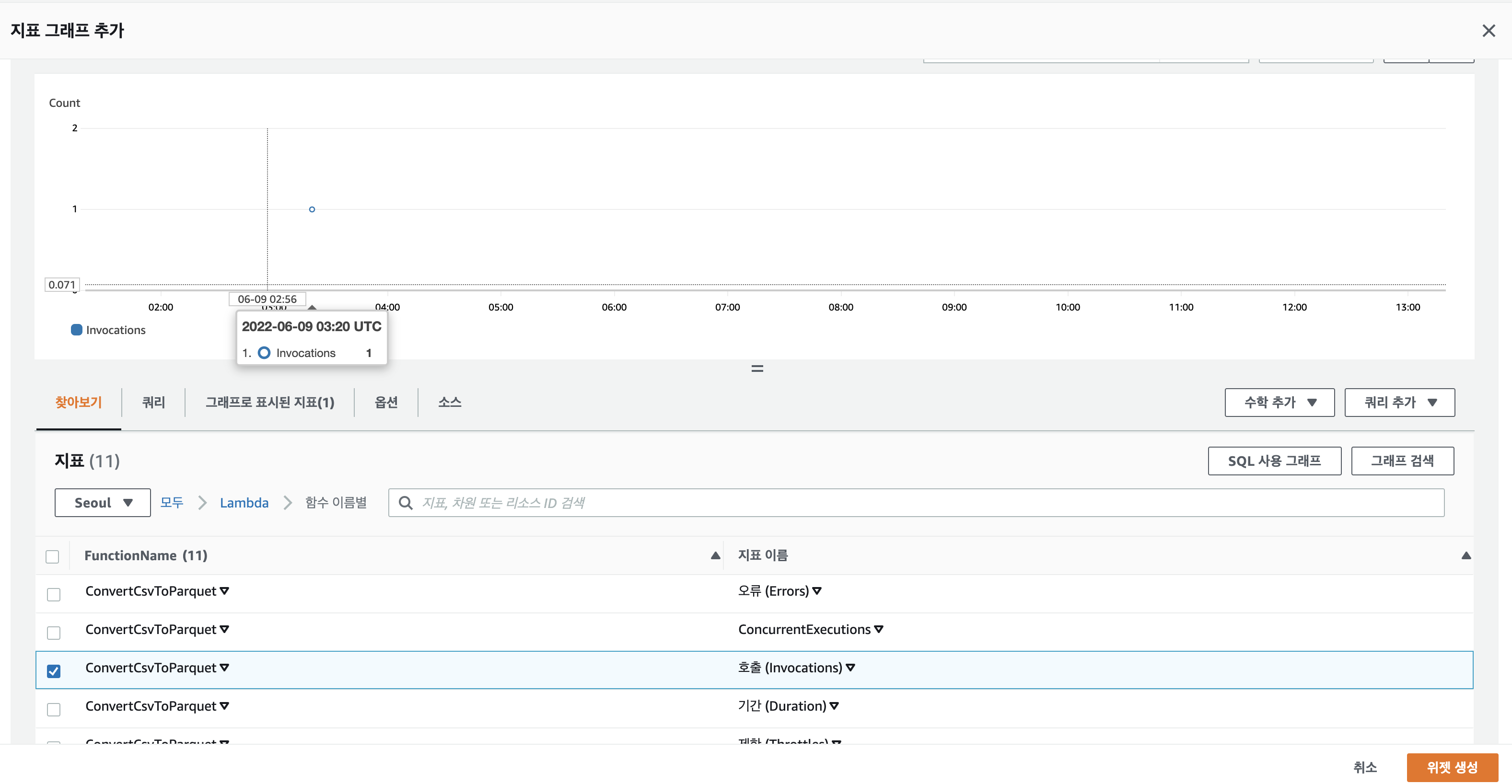
또한 동일한 내용을 Metric Insight를 통해 쿼리를 통해 표현 할 수 있습니다. Metric Insight의 경우 쿼리를 사용자 입장에서 편하게 하기 위해서 제공하는 방법으로 편집기를 통해 일반 쿼리를 수행 할 수 있습니다. 쿼리와 지표 두가지 방식을 병행하며 사용해야 원하는 그래프를 그릴 수 있습니다.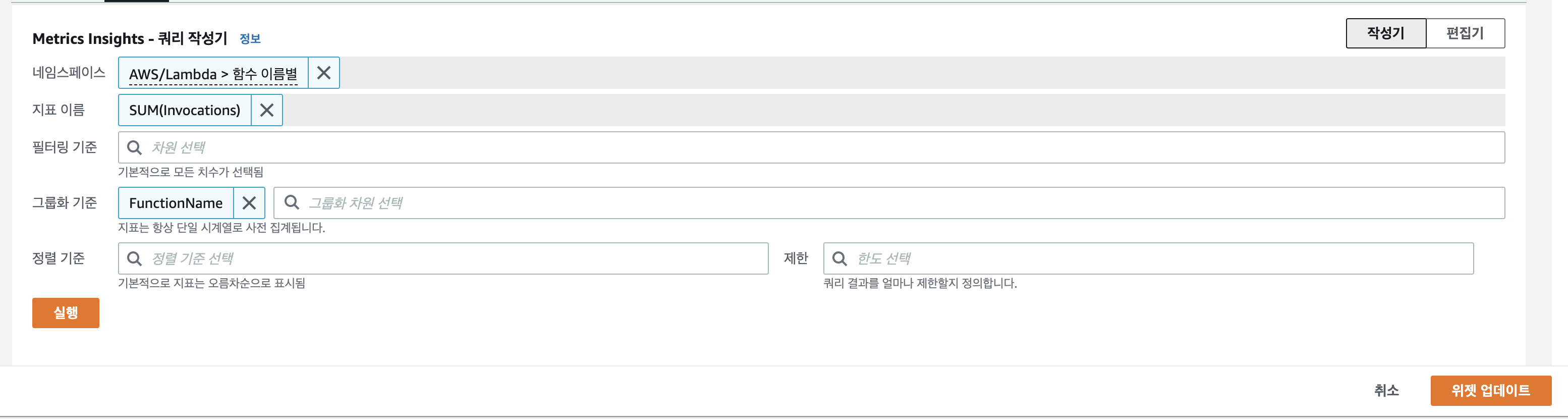
로그의 경우 다음과 같이 Log insight에서 Log group(대상 그룹)을 지정하고 쿼리를 작성해 원하는 데이터를 추출해 위젯을 생성합니다. 로그 쿼리는 일반적으로 추출을 원하는 fileds를 지정한 후 조건(filter)와 sort조건을 설정해 쿼리합니다. 아래 이미지는 Log 중 Error 를 포함한 로그만 추출한 결과입니다.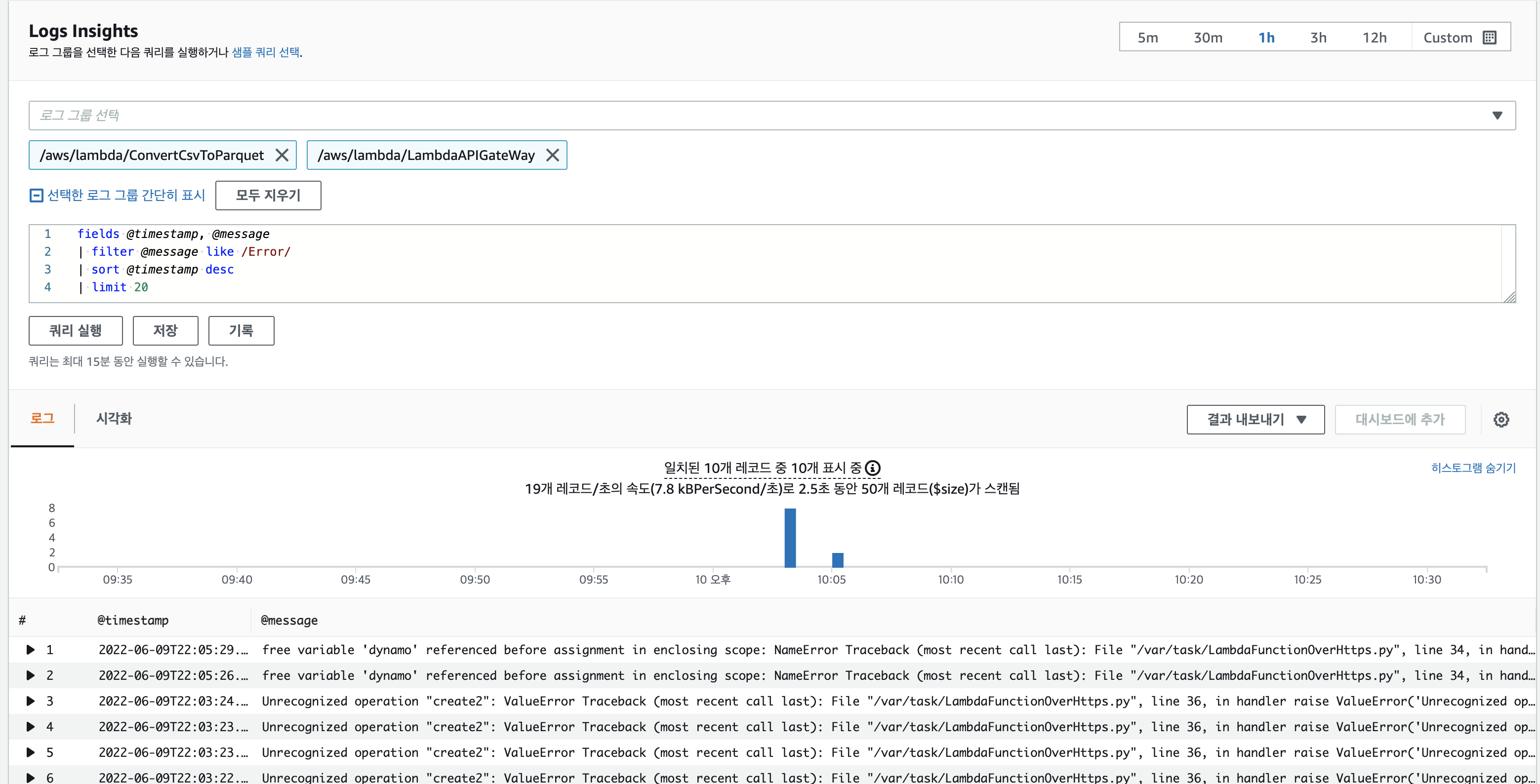
로그 결과의 위젯을 추가해 아래와 같이 샘플 Lambda dashboard를 만들 수 있습니다. 하지만 Metric 과 Log 를 사용하는데 익숙하지 않아 어려움을 많이 겪었습니다. 원하는 메트릭을 쿼리를 통해 추출한 후 결과를 이용해 정제하는 과정(백분율, Empty 제거 등) 을 이해해야하기 때문에 어려웠습니다. 현재 게시물 작성을 위한 환경에서는 Lambda 2개를 기반으로 하기때문에 큰 어려움은 없지만 갯수가 많아지면 SQL 쿼리 시간을 고려해야 하며,쿼리 작성이 더욱 어려워지고 대쉬보드를 로드하는 시간도 늘어나기 때문에 이에 대한 고려도 필요합니다.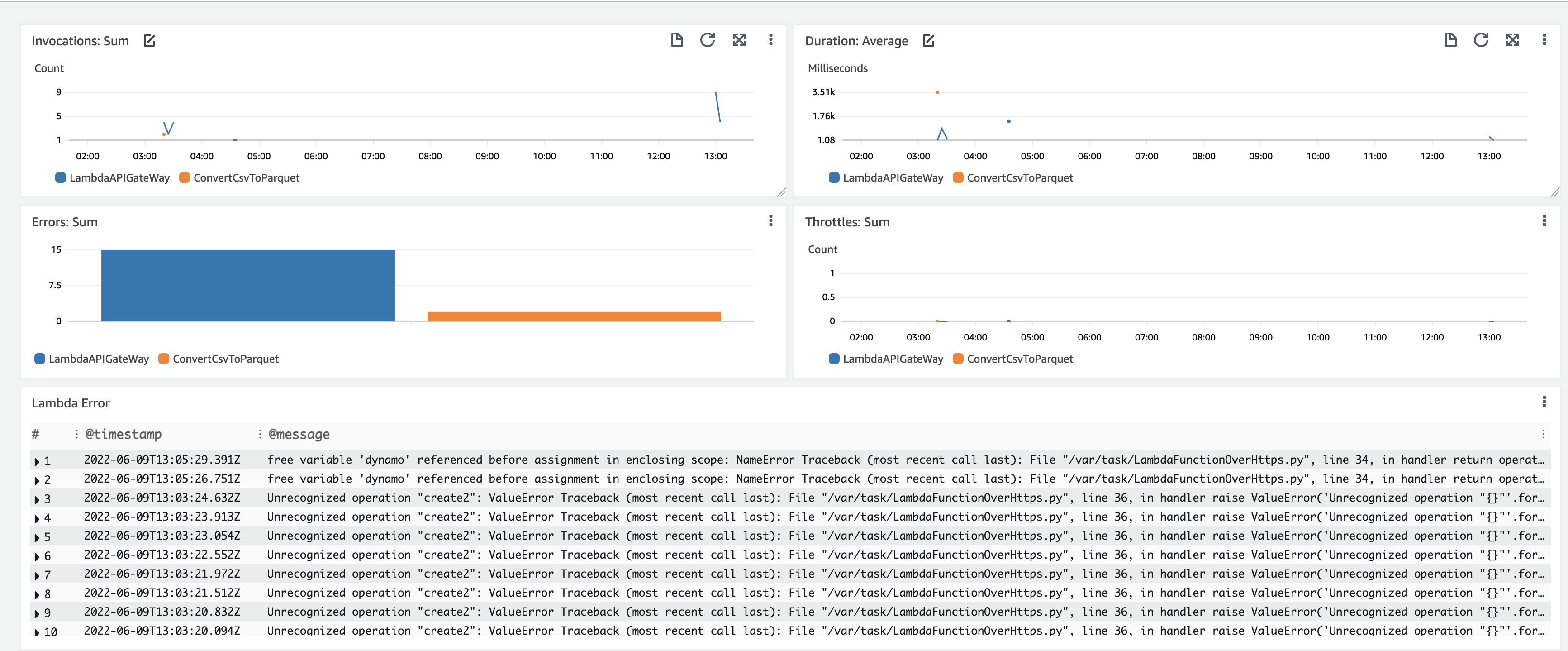
또한 메트릭 기반으로 위젯을 생성할 때 AWS 기본적으로 제공되는 메트릭은 제한적(Lambda 기본 제공 메트릭 : Invoke,error, throttle,duration,ConcurrentExcution)이기 때문에 대부분의 경우 Custom Metric 개발이 필요합니다.
3. CloudWatch Custom Metric 개발
예를 들어 Lambda에서 실행시 사용되는 Memory를 모니터링 하기 위해 이를 그리기 위한 위한 메트릭이 필요합니다. 기본으로 제공하는 메트릭에서 해당 내용이 없기 때문에 따로 개발해야합니다. 사실 메모리 사용량은 별도 개발없이 Lambda Insight를 활성화 하여 모니터링을 할 수 있습니다. 아래 그림과 같이 Lambda 속성에서 계층 추가를 통해 lambda Insight를 추가하면 확장 모니터링이 가능한게 되는데 이를 통해 Memory나 Cpu 등의 추가 모니터링을 할 수 있습니다.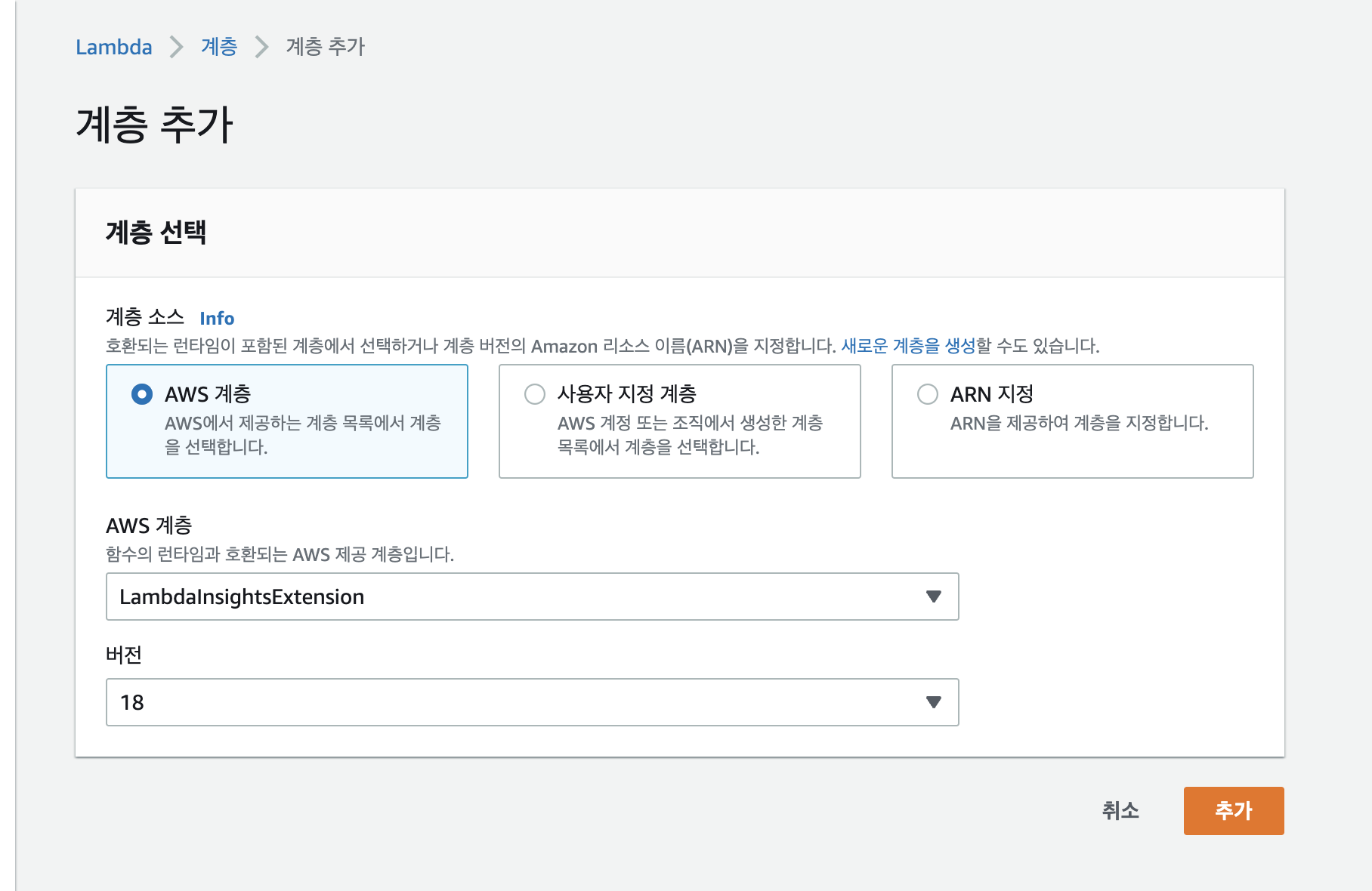
실제 Cloudwatch에서 다음과 같이 Lambda Insight를 통한 Dashboard 만들 수 있습니다. 이를 Dashboard에 추가해 모니터링을 할 수 있지만 이는 추가 비용이 발생하는 부분입니다. 개수가 적을 때는 큰 비용이 부담되지 않지만 람다의 수가 많을 경우 되면 로그 수를 합산해 비용을 부과하기 때문에 모니터링 설정에 대한 고려가 필요합니다.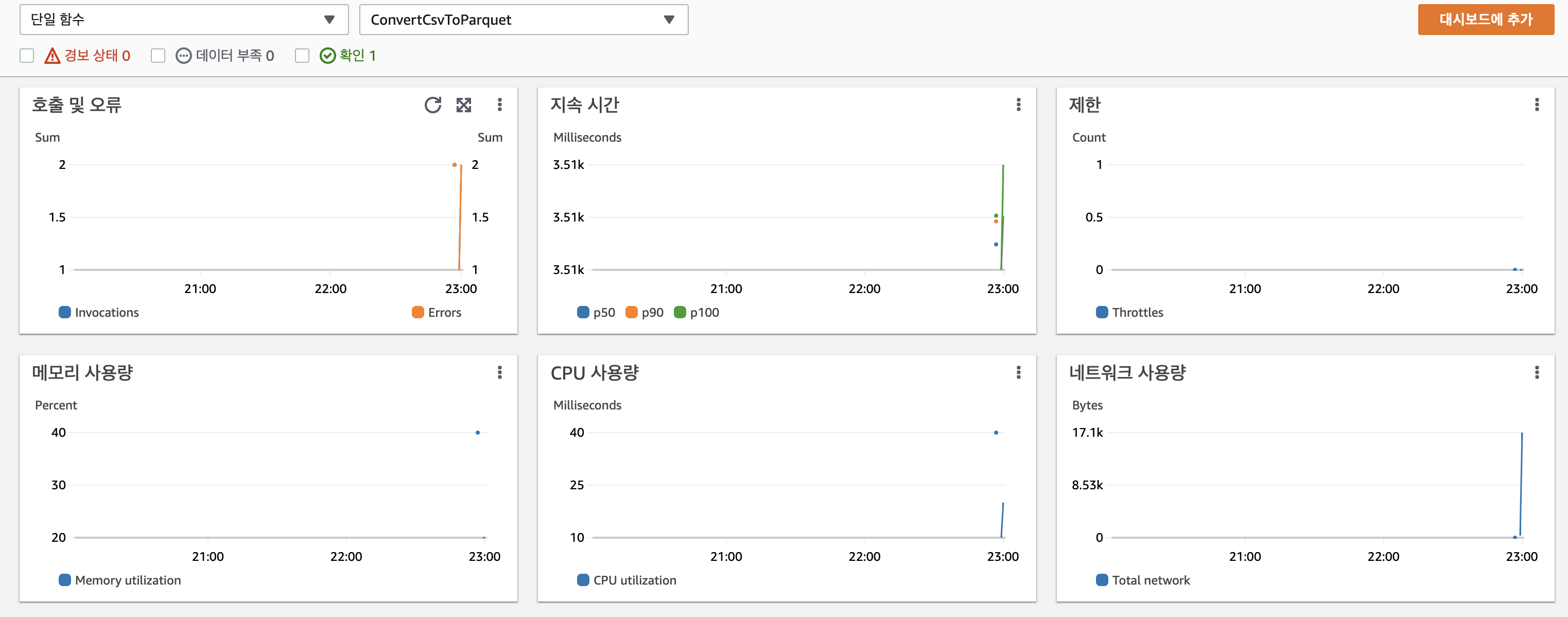
이러한 이유로 추가로 모니터링인 필요한 지표를 생성하기 위해 Boto3나 AWS CLI 를 통해서 Custom Metric을 생성 할 수 있습니다. Boto3를 이용하여 생성 한 후 Cloudwatch 에 Metric 데이터를 주입합니다. 예를 들어 아래 Log Insight를 통해 얻을 수 있는 Memory를 파싱해 메트릭화 하는 코드입니다.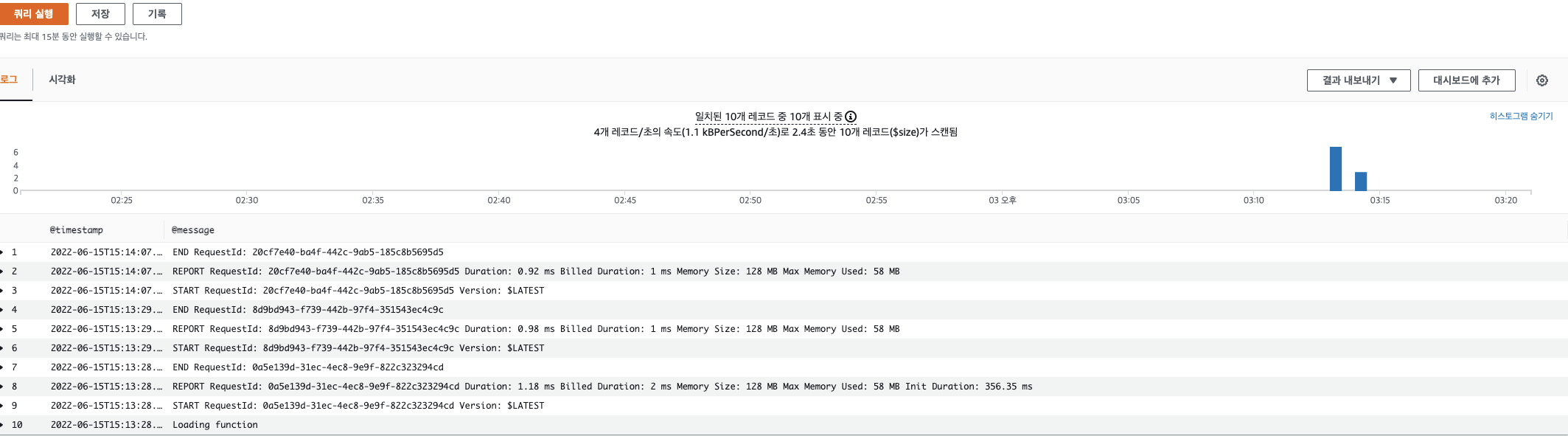
import subprocess
import time
import boto3
from datetime import datetime,timedelta
if __name__=="__main__":
#Log insight Query 생성
cloudwatch_logs = boto3.client('logs')
cloudwatch = boto3.client('cloudwatch')
resp = cloudwatch_logs.start_query(
logGroupName='/aws/lambda/LambdaAPIGateWay',
startTime = int((datetime.today() - timedelta(days=1)).timestamp()),
endTime = int(datetime.now().timestamp()),
queryString = "fields @timestamp, @message " +
"| filter @message like /Memory/ | sort @timestamp desc| limit 5"
)
query_id = resp['queryId']
response = None
#Query 실행
while response ==None or response['status'] == 'Running':
time.sleep(1)
response = cloudwatch_logs.get_query_results(
queryId=query_id)
#결과 추출 후 파싱
if response['results']:
for result in response['results']:
memory_size = result[1]['value'].split('\t')[4]
memory_size= memory_size.split()[3]
# Metric 주입
cloudwatch.put_metric_data(
Namespace='CUSTOM-METRIC',
MetricData=[
{
'MetricName': 'LambdaMemoryUsage',
'Dimensions':[
{'Name' : 'LambdaName',
'Value': 'LambdaAPIGateWay',
},
],
'Timestamp': result[0]['value'],
'Value': int(memory_size),
'Unit': 'Megabytes',
},
]
) 원하는 메트릭를 추출하는 방법에 대한 차이만 있고 Custom Metric을 구성하는 전체적인 로직은 비슷 할 거라 생각합니다. put_metirc_data 에 대한 이해가 필요한데, 현재는 Value 를 통해 값을 설정하였지만. StatisticValues 값을 통해 일정 기간동안의 Sum,Min,Max 등의 값을 지정할 수 있습니다.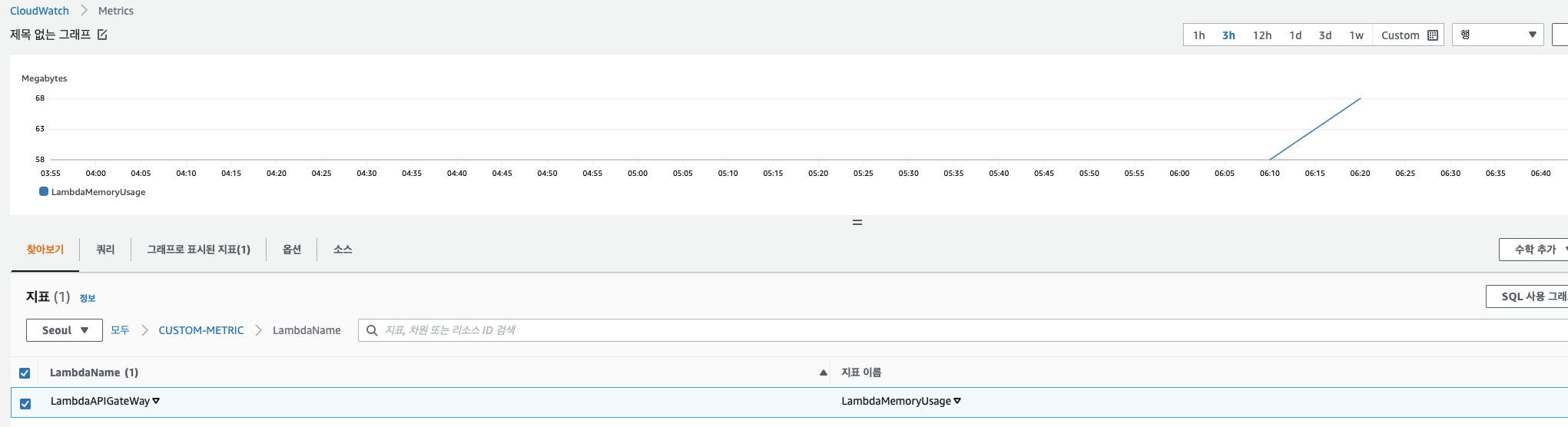
다음과 같이 구성한 코드를 주기적으로 업데이트하기 위해 배포를 해야합니다. Lambda를 통해 위의 코드를 실행할 경우 Event를 설정해 Batch형태(5분마다) 등 실행 하거나 다양한 메트릭을 발생 해 코드의 양이 커질 경우 데몬 형태로 실행시켜 주기적으로 데이터를 주입해야합니다.
4. S3 Log 설정
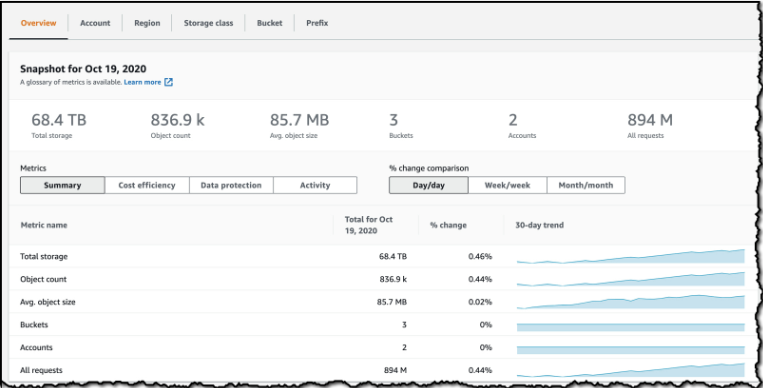
S3 역시 AWS에서 기본적으로 제공(NS: AWS/S3)하는 Metric이 존재합니다. 하지만 모니터링 하기에는 현저히 부족한 수준이고 이를 위해 Lens를 통해 모니터링을 확장할 수 있습니다. 현재 테스트 IAM에서는 Lens에 접근 할 수 있는 권한이 없기 때문에 진행하지 못했습니다. 다만 실제 구현환경에서는 Storage Class 별 용량, 상위 버킷 리스트 등 의미 있는 위젯이 다양하게 존재하였습니다.
위와 같이 대쉬보드를 통한 모니터링 뿐 아니라 Access Log 를 남기도록 설정을 해야 할 수 있습니다. Log를 남기기 위한 bucket의 속성에서 서버 액세스 로깅을 활성화 한 후 로그 파일을 남기기 위한 타겟 버킷을 입력합니다.권장 사항으로는 region 별로 log용 버킷을 생성한 후 폴더를 통해 bucket을 구분합니다.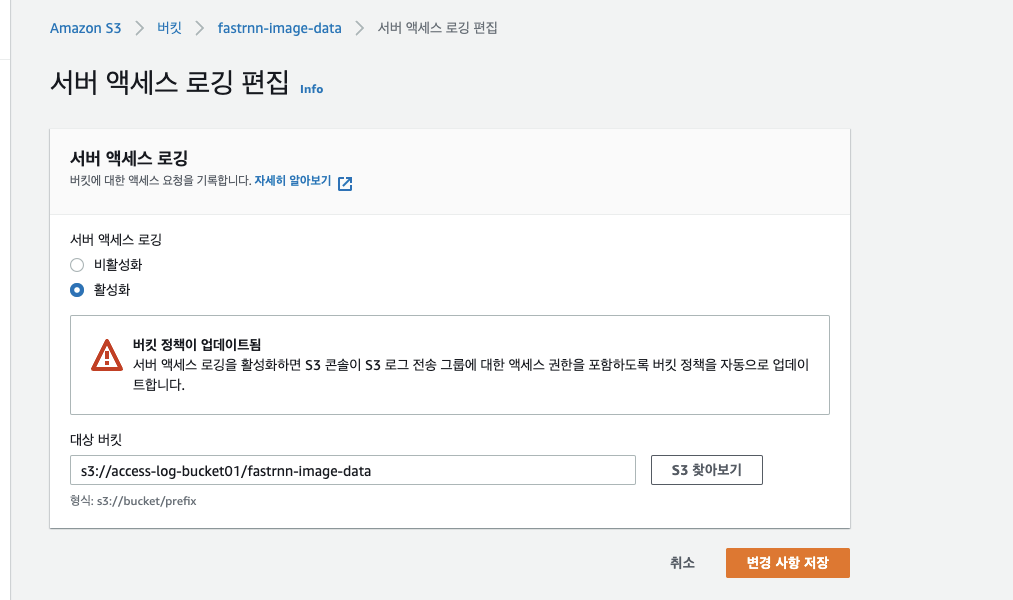
설정시 다음과 같이 log 파일이 남게 됩니다. 실제 내용을 조회하면 시간,접근한 파일, Client 정보, 경로 등 의미있는 로그를 확인 할 수 있습니다만 현재 로깅레벨에 대한 지정이 없기 때문에 로그 파일이 너무 많이 생겨 이에 대한 정책이 필요할 거 같습니다.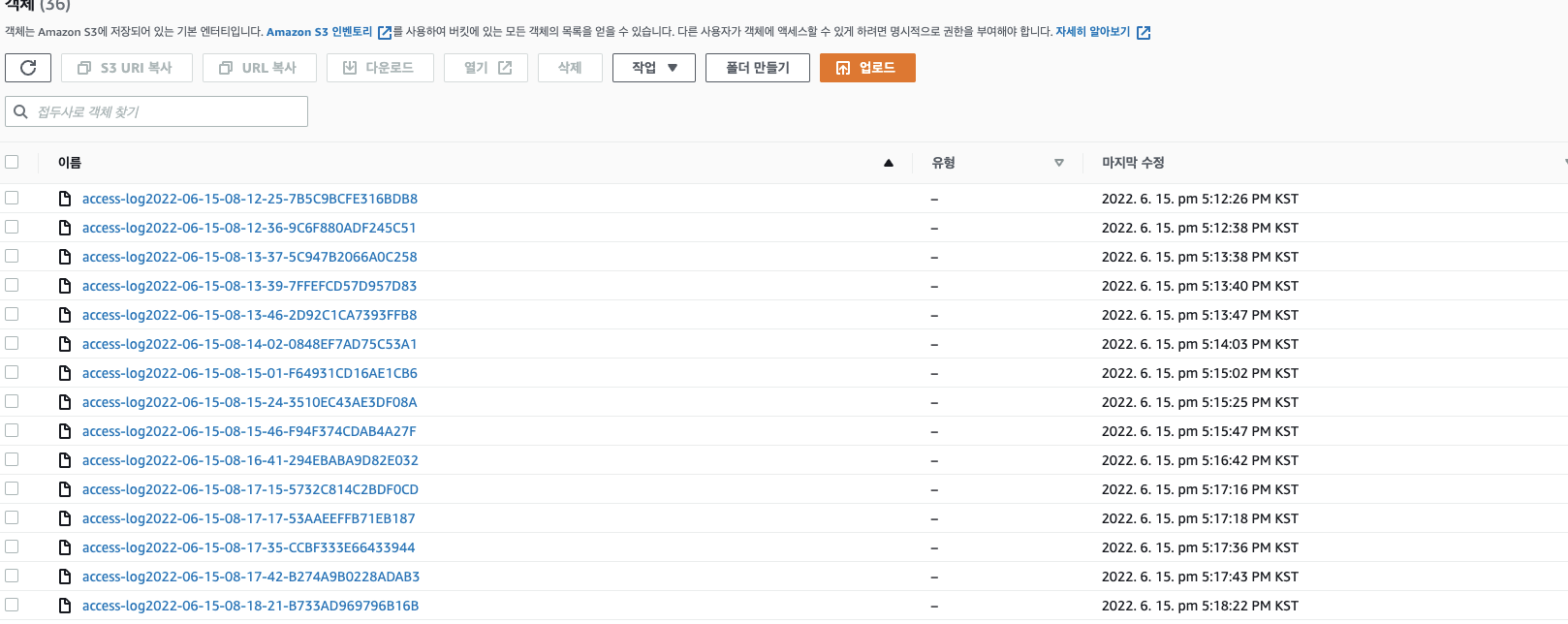
S3 뿐 아니라 Glue나 다른 AWS 서비스도 대부분 모니터링을 위한 설정이 존재합니다. 다만 기본으로 설정되어 있지 않아 추가 설정 시 모니터링을 진행 할 수 있습니다.
