반정규화를 도입한 배경
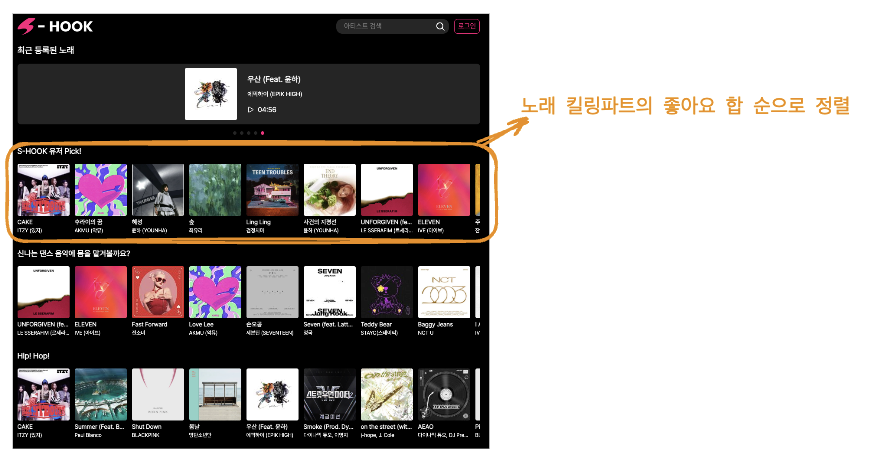
현재 S-Hook 서비스는 대부분의 조회(킬링파트, 노래)에서 좋아요 수를 기준으로 정렬이 이루어지고 있습니다. (좋아요의 내역을 나타내고 있지 않습니다) 더불어 좋아요의 경우 사람들이 손쉽게 사용하는 기능으로 데이터량이 다른 테이블에 비해 많이 쌓일 것이라 예측했고 불필요하게 모든 내역을 불러오는 것은 데이터 량이 증가했을 때 성능 저하 문제로 이어질 것이라 생각했습니다.

위는 현재 엔티티의 연관관계도 입니다. KillingPart에서 좋아요 개수를 가져오기 위해서는 KillingPartLike의 내역을 Set Collection으로 불러와 size()를 통해 개수를 가져오는 방식이었습니다. jpa에서는 size() 메소드를 호출하는 경우 proxy로 불러왔던 KillingPartLike proxy Collection을 실제로 채우기 위해 추가 쿼리가 발생하게 됩니다.(이는 fetch join이나 entityGraph로 해결이 가능 하지만 결국 해당데이터를 모두 불러와야 한다는 공통점이 있습니다.)
데이터의 내용을 불러오지 않고 좋아요 개수를 파악할 수 있게 KillingPart에 LikeCount 필드를 두는 반정규화를 적용했습니다.
반정규화 도입으로 발생한 문제
서비스 운영 과정에서 좋아요의 내역의 수와 반정규화를 한 필드의 값이 일치하지 않는 문제가 있다는 것을 발견했습니다. 해당 문제를 해결하기에 앞서 문제가 발생하는 부분을 간소화해 테스트를 진행해보았습니다. (지금부터 보여지는 객체와 메소드는 실제 운영코드를 간소화 한 것입니다.)
KillingPart
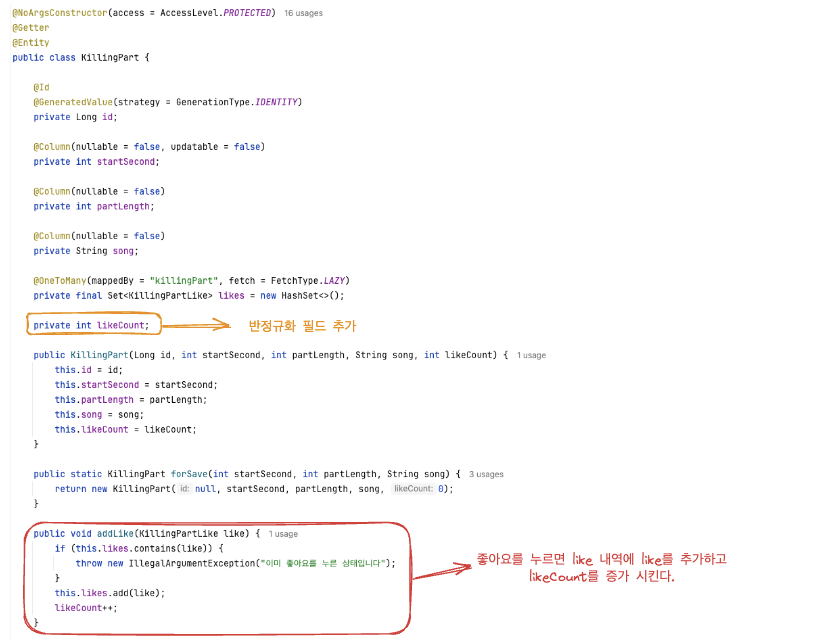
킬링파트 엔티티에 likeCount 필드를 추가했고 좋아요 요청이 발생하면 addLike() 메소드를 실행해 likeCount를 1증가 시킵니다.
KillingPartLike
KillingPartLikeService

테스트 코드 및 결과

테스트의 흐름은 10개의 thread가 킬링파트에 좋아요를 비동기적으로 동작하여 좋아요 내역과 좋아요 개수가 같은지 비교하는 테스트 입니다. 처음에 테스트 코드를 작성하고 나서는 like db의 개수와 킬링파트의 likeCount의 수가 같을 것이라고 기대했으나 결과는 의도한 대로 나타나지 않았습니다.
killingPart db

killingPartLike db
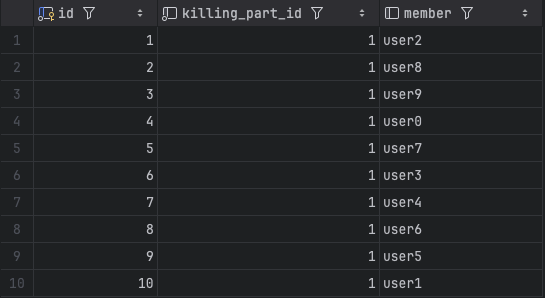
킬링파트 좋아요 db 내역을 보면 킬링파트 id가 1인 킬링파트에 10개의 좋아요 내역이 생긴 것을 확인할 수 있지만 킬링파트 db 내역 내 like_count를 보면 1로 이 둘이 서로 상이한 것을 볼 수 있습니다.
문제 원인 파악하기
앞서 발생한 문제는 동시성 문제였습니다. 동시성 문제는 하나의 공유자원에 대하여 2개 이상의 쓰레드가 동시에 제어할 때 나타나는 문제로 하나의 쓰레드가 데이터를 수정 중에 있을 때 다른 쓰레드가 수정 전 데이터를 읽어 로직을 처리하여 데이터의 정합성이 맞지 않는 문제를 말합니다.
위의 코드를 예시로 보면 우리는 KillingPartLike의 create() 메소드를 하나의 쓰레드가 모두 완료한 후에 다른 쓰레드가 접근해서 동작하는 동기 방식을 기대했었습니다. 하지만 실제로는 시분할로 컨텍스트 스위칭이 발생하면서 여러 쓰레드가 like_count를 같은 값으로 읽어오고 jpa의 더티 채킹을 통해 앞선 결과에 이어서 좋아요 수를 올리는 것이 아닌 덮어쓰는 형태로 동작했습니다. 그림으로 간단하게 다시 보겠습니다.
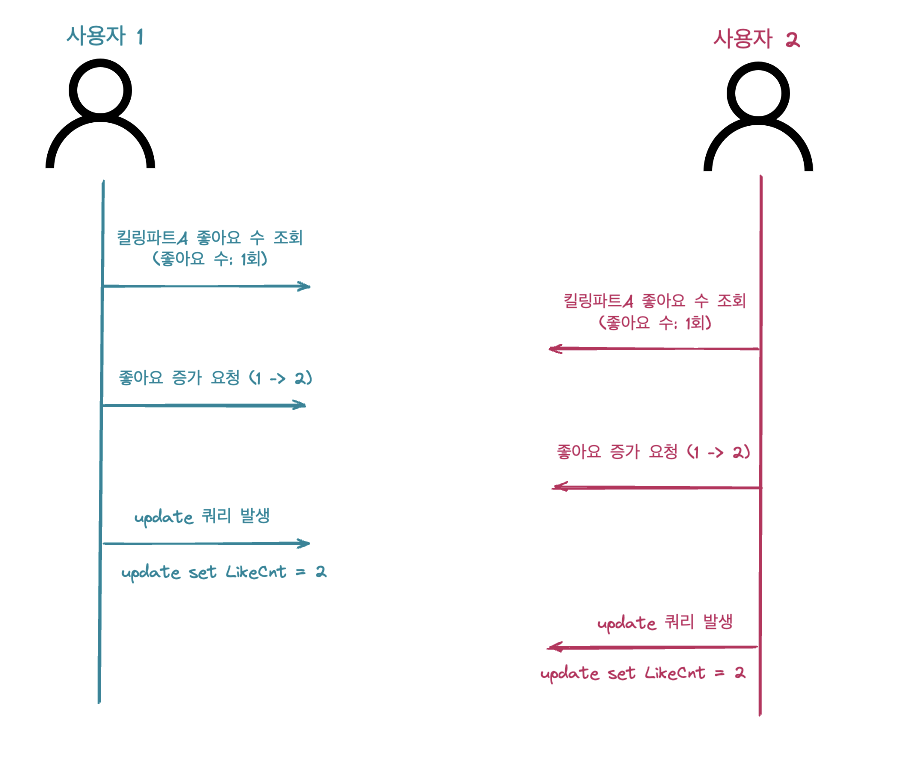
- 사용자 1이 킬링파트를 조회한다. (킬링파트의 좋아요 수는 현재 1이다.)
- 사용자 2가 킬링파트를 조회한다. (사용자 2도 킬링파트의 좋아요 수는 1로 읽어온다.)
- 사용자 1이 킬링파트의 좋아요 수를 증가시킨다. (jpa 1차 캐시에서 변경 감지를 통해 update 쿼리를 실행 좋아요 수 1 → 2)
- 사용자 2가 킬링파트의 좋아요 수를 증가시킨다. (해당 작업 역시 1차 캐시 변경 감지를 통해 동작하므로 2변 과정에서 읽어왔던 좋아요 수 1에 1이 더해진 2로 변경시킨다.)
결과적으로 jpa의 더티 채킹 과정에서 db의 저장된 like_count 필드 값을 활용하는 것이 아닌 영속성 컨텍스트에 속한 객체의 변화 감지로 update 쿼리를 발생하기에 데이터의 정합성이 보장되지 않는 문제가 발생했고 이를 해결하기 위해 여러 방법을 생각해보았습니다.
문제 해결 방안
DB level에서 해결할 수 있는 방안을 고려해보았습니다.
낙관적 락으로 해결하기
낙관적 락은 대부분의 트랜잭션에서 충돌이 발생하지 않을 것이라고 낙관적으로 가정하는 방법입니다. 해당 방법의 특징은 데이터베이스의 락을 이용하지 않고 엔티티의 Version을 관리하여 동시성을 제어하는 것입니다.
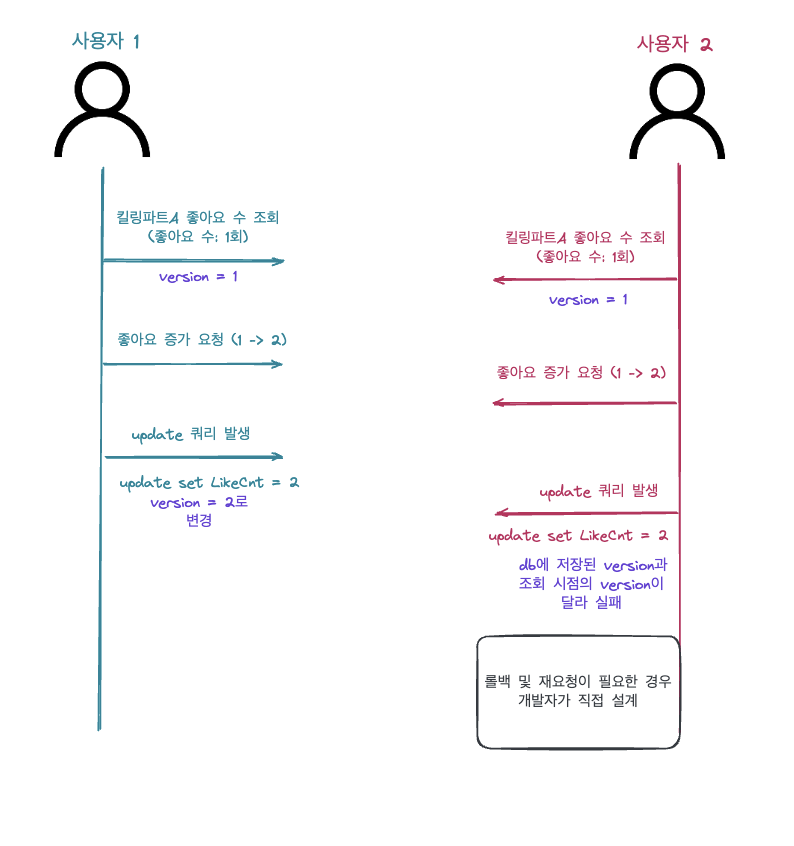
사용자 1이 킬링파트 A에 조회하고 “좋아요”를 실행한 후 update 쿼리가 실행되면 version이 자동으로 증가 합니다. (단 조회 시점에 version 현재 db의 버전일 일치하는 경우에만 동작합니다.) 사용자 2의 경우 조회 시점에는 version이 1이었지만 사용자 1이 먼저 좋아요 작업을 마무리해 킬링파트 A 레코드의 version을 2로 변경한 상태입니다. 이후 사용자 2가 좋아요를 작업하고 db에 반영하려고 하지만 사용자 2가 데이터를 조회하는 시점에 version과 현재 db에 저장된 version이 달라 실패하게 됩니다.
낙관적 락은 위의 그림과 같이 lock을 이용하지 않고 동시성 문제를 해결할 수 있는 방안입니다. 다만 사용자 2의 요청을 유효하게 하기 위해서는 추가적인 작업이 필요합니다.(즉, 사용자 2는 좋아요 요청을 한 번 보내지만 내부적으로는 여러 번 수행하는 상황이 발생할 수 있습니다.) 또한 “좋아요” 기능은 사람들이 쉽게 이용할 수 있는 기능이다보니 충돌이 자주 발생할 것이라 예상해 적절하지 않는 해결책이라 생각했습니다.
비관적 락으로 해결하기
비관적 락은 모든 트랜잭션에서 충돌이 발생한다고 가정하고 데이터에 우선으로 lock을 이용하는 방법입니다. 해당 방법의 특징은 데이터를 읽는 과정에서도 select … for update 을 이용해 s-lock이 아닌 x-lock으로 데이터를 잠금다는 것입니다.
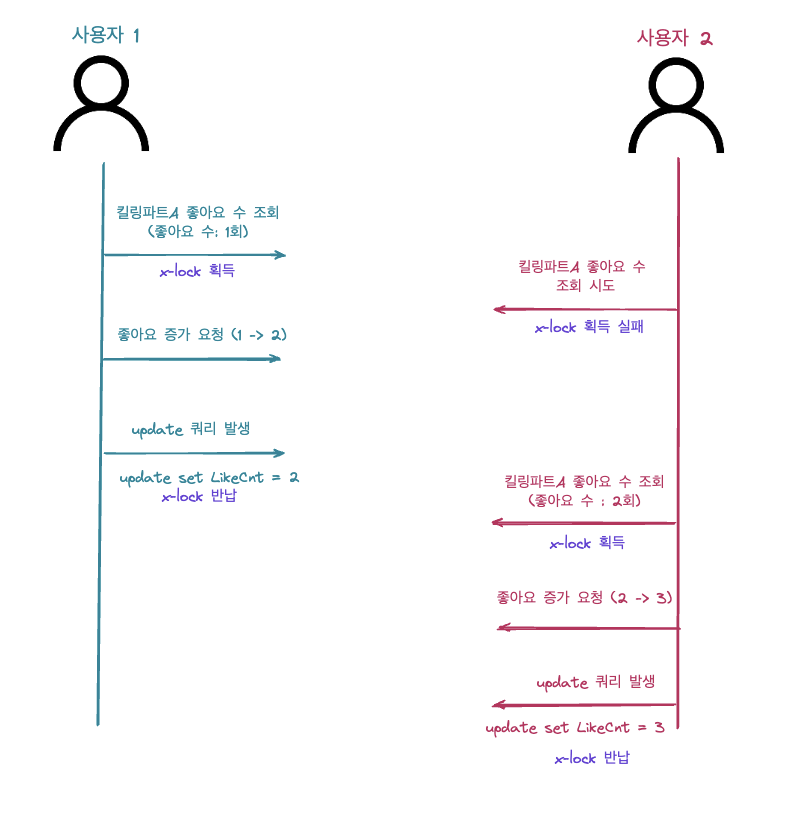
사용자 1이 킬링파트 A를 조회하는 시점에 킬링파트 A 레코드에 x-lock을 흭득합니다. 그 이후 사용자 2는 킬링파트 레코드에 접근하지 못하고 대기합니다. 사용자 1의 좋아요 작업이 마무리 된 이후에 비소로 사용자 2는 킬링파트 A 레코드에 접근해 좋아요 작업을 처리할 수 있습니다.
비관적 락을 이용하는 방안은 데이터 정합성을 유지시켜주지만 데이터(킬링파트 A)에 접근하는 시점부터 x-lock을 활용하고 있기 때문에 성능적으로 문제가 있을 것이라 판단했습니다. 예로 위의 그림을 보면 사용자 2의 경우 요청 시점과 x-lock을 흭득하는 시점이 상이해 대기를 해야합니다.
데이터 변경 감지가 아닌 JPQL으로 해결하기
“좋아요” 기능에서 정합성 문제가 발생한 이유는 더티 채킹으로 데이터의 변경이 데이터가 조회된 시점에 정보를 바탕으로 데이터를 수정하기 때문이었습니다. 그렇기에 데이터를 수정하는 시점에 db 데이터를 이용하면 문제가 발생하지 않을 것이라 생각했습니다.
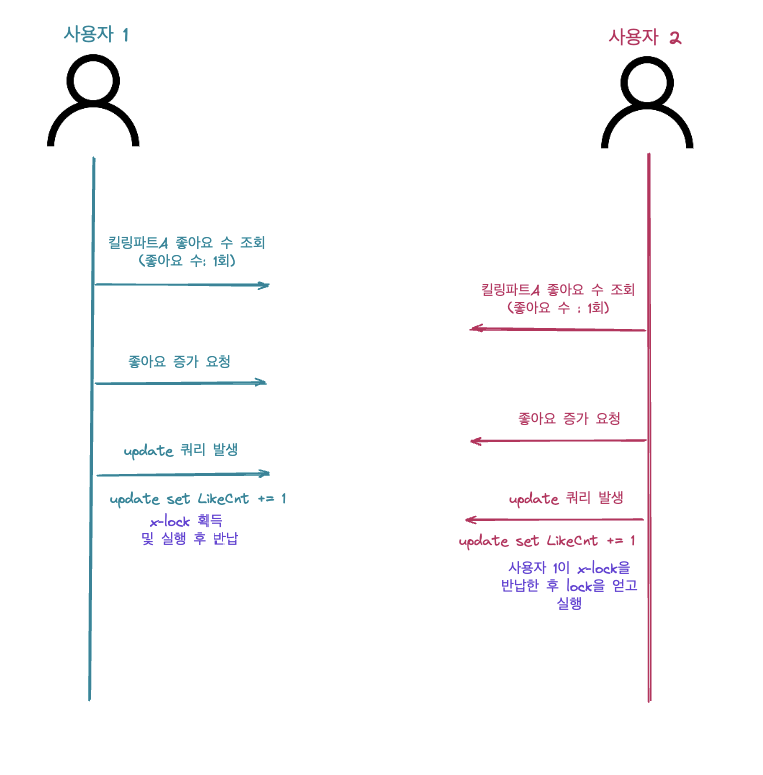
위의 방안은 jpa의 더티 채킹을 활용하는 것이 아닌 JPQL에 직접 update 쿼리를 이용한 방안입니다. 사용자 1이 킬링파트 A를 조회하고 “좋아요”을 실행하는 시점에 해당 레코드에 x-lock을 걸어 like_count 값을 증가 시킵니다.(이 때에는 변경감지를 통해 값을 증가시키는 것이 아닌 레코드 값을 기준으로 값을 증가시킵니다.) 이 사이에 사용자 2가 킬링파트 A에 접근하고 like_count 값을 증가 시키려고 하지만 lock이 걸려 있어 대기후 lock을 얻고 like_count의 값을 증가시킵니다.
해당 방식은 비관적락에 비해 레코드에 x-lock을 지속하는 시간이 짧고 낙관적 락에 비해 후속으로 처리해야 할 부분이 없다는 것이 가장 큰 장점을 느꼈습니다. 다만 jpql을 이용하게 되면 service 코드에 db와 관련된 코드가 노출되는 아쉽다는 팀원들의 의견이 있었지만 지금 단계에서는 가장 합리적인 방법이라고 느꼈습니다. 이외에도 애플리케이션 level에서의 락(뮤텍스, 세마포어 등)을 이용하는 방안을 고려해보았지만 서버가 확장 되어 이분화가 되는 순간 무용지물이 된다는 것을 의견을 주고 받으면서 확인했습니다.
최종 변화된 코드
KillingPartLikeService
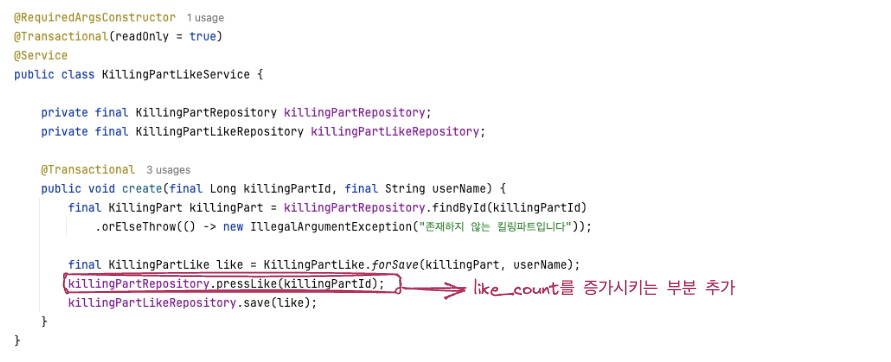
기존 코드에 like_count를 직접 증가시키는 메소드를 추가했습니다.
KillingPartRepository

KillingPart

기존에는 addLike 내부에 like_count 필드 값을 증가시키는 부분이 있었지만 이를 query를 통해 해결하기에 jpa의 변경감지를 유발하는 like_count++를 제거했습니다.
테스트 결과
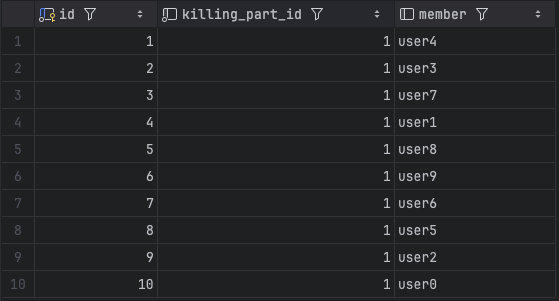
서로 10명이 한 킬링파트에 대해서 동시에 “좋아요” 요청을 한 경우입니다.
killingPart db

killingPartLike db
느낀점
현재 채택한 방법 역시 단일 DB로 서비스를 운영하고 있기에 유효한 방법이라는 생각이 듭니다. 다만 검색을 통해 찾아보면 메세지 큐 도입 혹은 분산 락 방법이 있다는 것을 알 수 있었지만 이 방법들은 현 상황에 새로운 인프라를 구축해야하기에 지금 단계에서는 비효율적이라고 느꼈습니다. 서비스가 확장되면 해당 방법들을 고려할 수 있을 것 같습니다.
