문제 사항
현재 S-HOOK 서비스는 유튜브 쇼츠와 인스타 릴스와 같이 스와이프를 통해 노래 듣기 기능의 편의성을 높였습니다. 스와이프를 구현하기 위해 사용자가 하나의 노래를 클릭하면 좋아요 개수를 기준으로 사용자가 선택한 노래 앞뒤 10개를 미리 가져와야 했습니다.
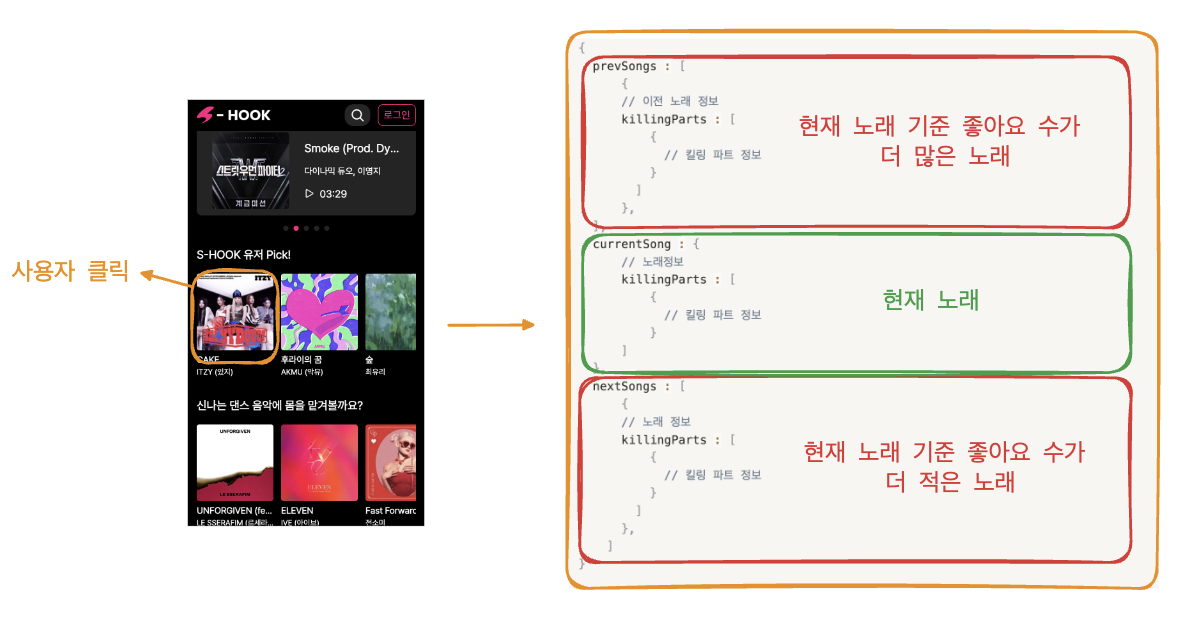
사용자가 특정 노래를 선택하여 요청을 보내면 현재 노래 기준 좋아요 수가 더 많은 노래, 현재 노래, 현재 노래 기준 좋아요 수가 더 적은 노래 로 분리했고 이를 각각 DB에서 연산하여 조회하는 방식을 택했습니다.
<기존 노래보다 좋아요 수가 많은 노래 조회하기>

<기준 노래보다 좋아요 수가 적은 노래 조회하기>

위의 두 쿼리에 대한 설명은 다음과 같습니다.
- 노래와 킬링파트를 join합니다.
- 조인된 킬링파트를 노래별로 묶기 위해서 노래 id로 group by 합니다.
- 킬링파트들(3개의 킬링파트)의 좋아요 수의 총합을 비교 후 좋아요 수가 같으면 노래의 id를 비교하여 최신 노래가 우선으로 나오도록 비교합니다.
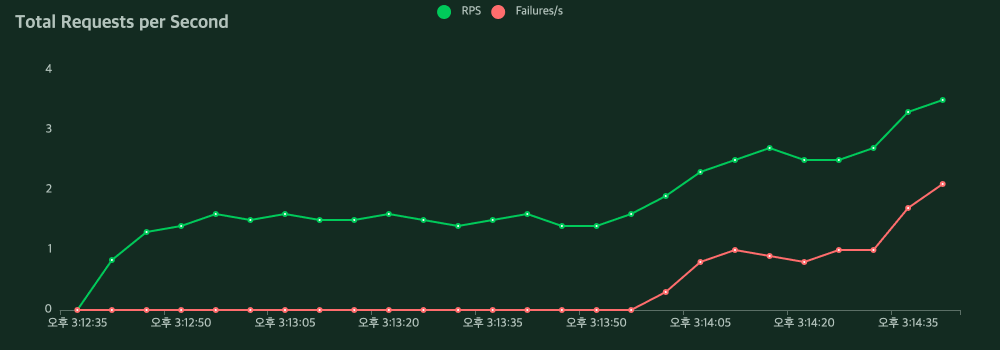
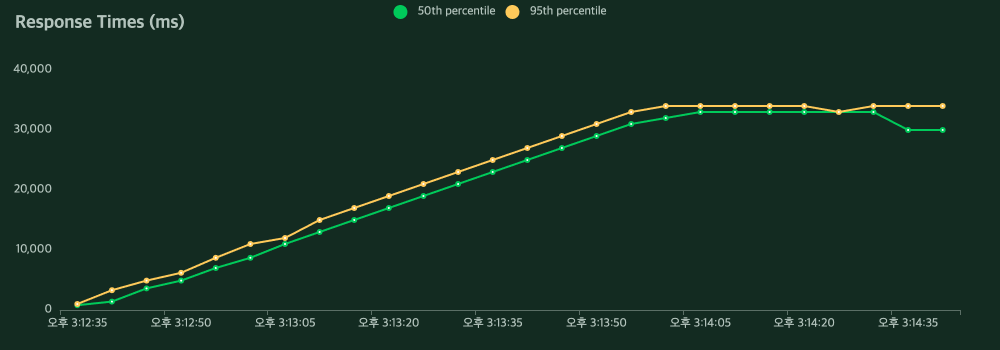
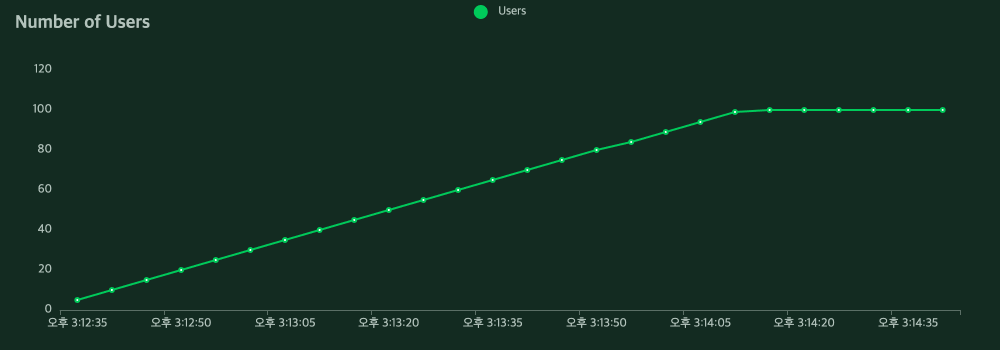
노래 듣기를 위한 스와이프 기능은 S-HOOK 서비스의 핵심기능이기에 많은 사용자가 이용할 것이라 생각해 성능 체크가 필요하다고 느꼈습니다. 성능 측정을 Locust로 한 결과는 처참했습니다. Locust를 이용해서 사용자를 점차 늘려가며 동시 요청을 처리했을 때 다음과 같은 결과가 나타났습니다.

문제 상황 분석하기
위의 문제 사항은 DB에 연결되고 응답결과까지 30초를 넘어가서 Connection이 끊어지는 문제였습니다. 이를 해결하는 방식으로는 connection 유지 시간을 늘리는 것을 고려할 수 있으나, Locust의 결과를 보면 요청에 대한 응답 속도가 대략 30,000ms 대로 응답시간이 긴 것을 확인할 수 있었습니다. 그래서 Connection 유지 시간을 늘리는 방식보다는 응답시간을 단축시켜 문제를 해결하고자 했습니다.
먼저 Query의 실행계획을 먼저 확인했습니다.
| id | select_type | table | type | possible_keys | key | ref | Extra |
|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | Song s1 | index | PRIMARY | PRIMARY | null | Using temporary; Using filesort |
| 1 | PRIMARY | Killing_part k1 | ref | idx_song_id | idx_song_id | shook.s1_0.id | null |
| 3 | SUBQUERY | Killing_part k3 | ref | idx_song_id | idx_song_id | const | null |
| 2 | SUBQUERY | Killing_part k2 | ref | idx_song_id | idx_song_id | const | null |
위의 실행 계획을 보았을 땐 join 과정에서 인덱스도 잘 이용되었지만 Song Table Extra에 Using temporary:Using filesort 가 문제였습니다.
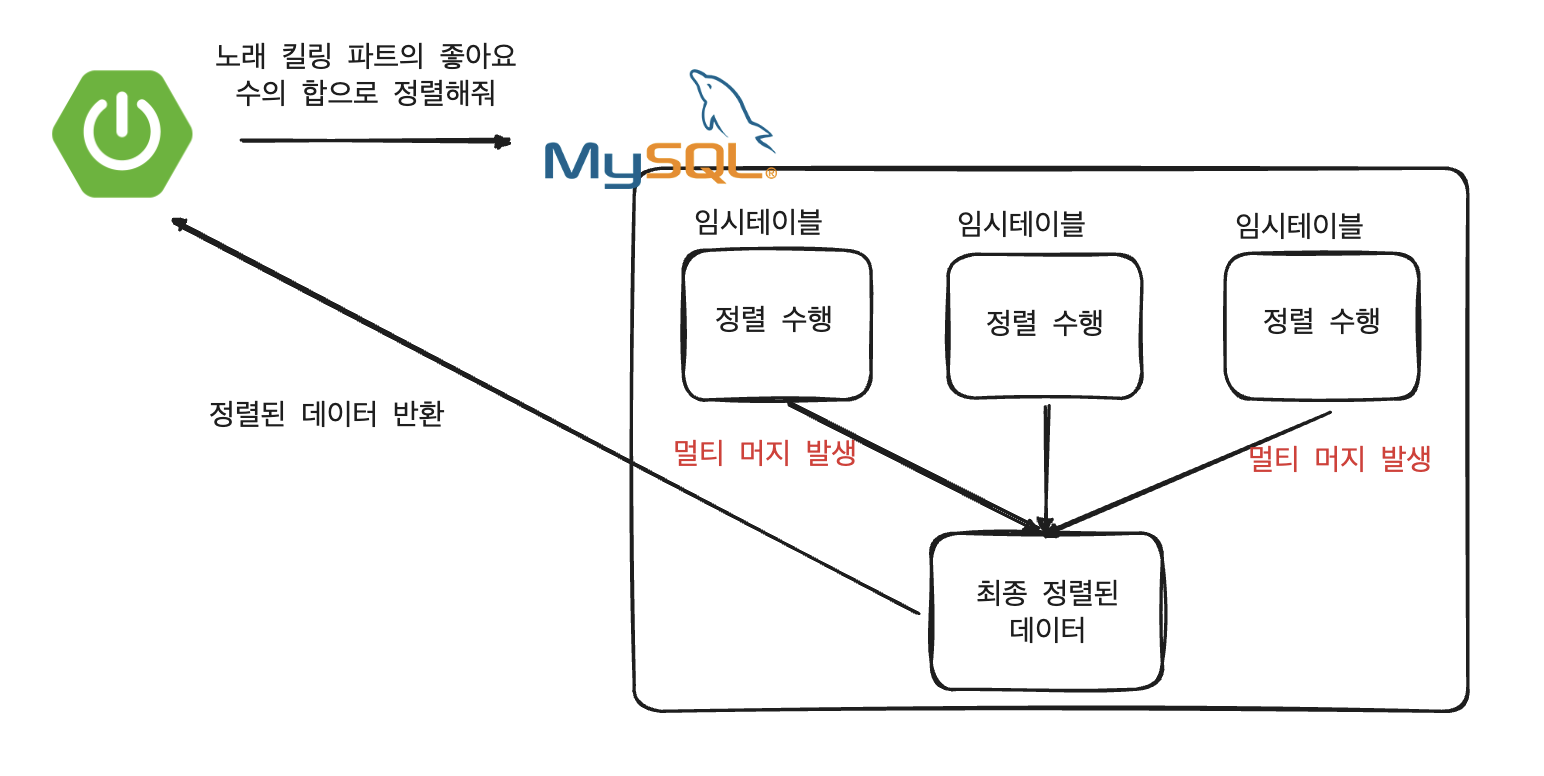
Using Temporary:Using filesort에 대해서 찾아보니 MySQL 내부에서 정렬을 하는 과정에서 임시테이블을 이용하는 것으로 이 부분이 성능상 문제가 되는 것이었습니다. 그 이유는 다음과 같습니다.
-
데이터가 많아지게 되면 정렬과정에서 메모리가 아닌 하드 디스크로 데이터들을 임시로 이용해 저장해둡니다.
- 즉, 디스크 I/O 횟수가 늘어나게 됩니다.
-
임시테이블 마다 정렬과정이 발생하며 최종으로 데이터를 취합하는 과정에서도 정렬과정(멀티 머지)이 발생하여 예상한 정렬횟수보다 많은 정렬과정이 발생합니다.
이 부분을 해결하기 위해서 우리는 임시 테이블을 이용하지 않는 방법으로 정렬 과정이 이루어지도록 처리를 해야했습니다. 임시테이블을 이용하지 않기 위해서는 모든 데이터를 불러와서 정렬을 하는 것이 아닌 정렬 후 데이터를 불러오게 해야했습니다. 그러기 위해서는 ORDER BY 조건으로 인덱스로 활용이 될 수 있는 컬럼이어야 했습니다. 하지만 좋아요 수의 총합 (집계 함수 SUM)으로 정렬해야했기에 DB만으로 성능을 개선하는 것은 어려움이 있었습니다.
문제 해결하기
DB 만으로 성능을 개선해 나가는 것은 어려웠고 노래 데이터를 정렬하는 책임을 Application애서 처리하는 방식으로 문제를 해결했습니다.
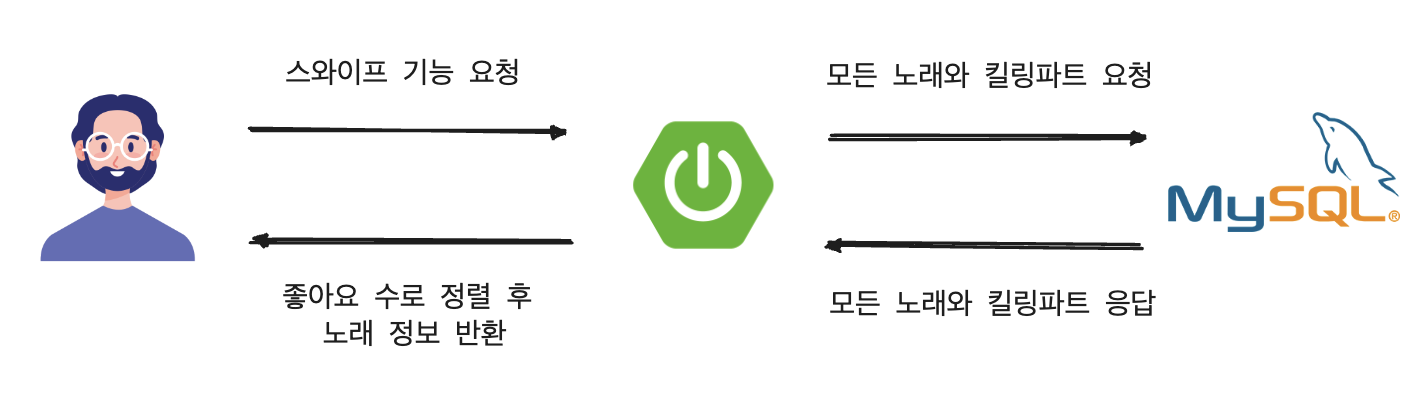
이 부분에서도 저희 팀원들 모두가 의문을 가진 것이 있었습니다. 그것은 정렬을 하는 과정에서 결국 모든 노래와 킬링파트 정보가 필요하다는 것이었습니다. 즉, 노래, 킬링파트의 데이터가 많아지게 되면 사용자의 요청마다 모든 데이터를 불러오는 것이 좋지 않을 것이라고 생각했습니다.
이 부분을 최적화하기 위해서 저희 팀은 메모리 캐싱을 고려했고 적용했습니다. 메모리 캐싱을 적용할 수 있었던 이유는 다음과 같습니다.
-
현재 운영 서버는 1대로 운영하고 있어서 서버간의 정합성을 고려할 필요가 없다.
-
엄격한 제약사항으로 인해 노래와 킬링파트의 경우 현재 사용자가 직접 데이터를 넣는 것이 아니고 개발자가 직접 넣고 있는 상황으로 데이터가 추가되는 것에 대한 실시간성이 중요한 편이 아니다.
그래서 저희는 메모리에 노래 정보를 모두 담아두고 사용자가 스와이프 기능을 요청할 시에 DB를 이용하는 것이 아닌 메모리에서 데이터를 불러와 정렬하는 방식으로 택했습니다.
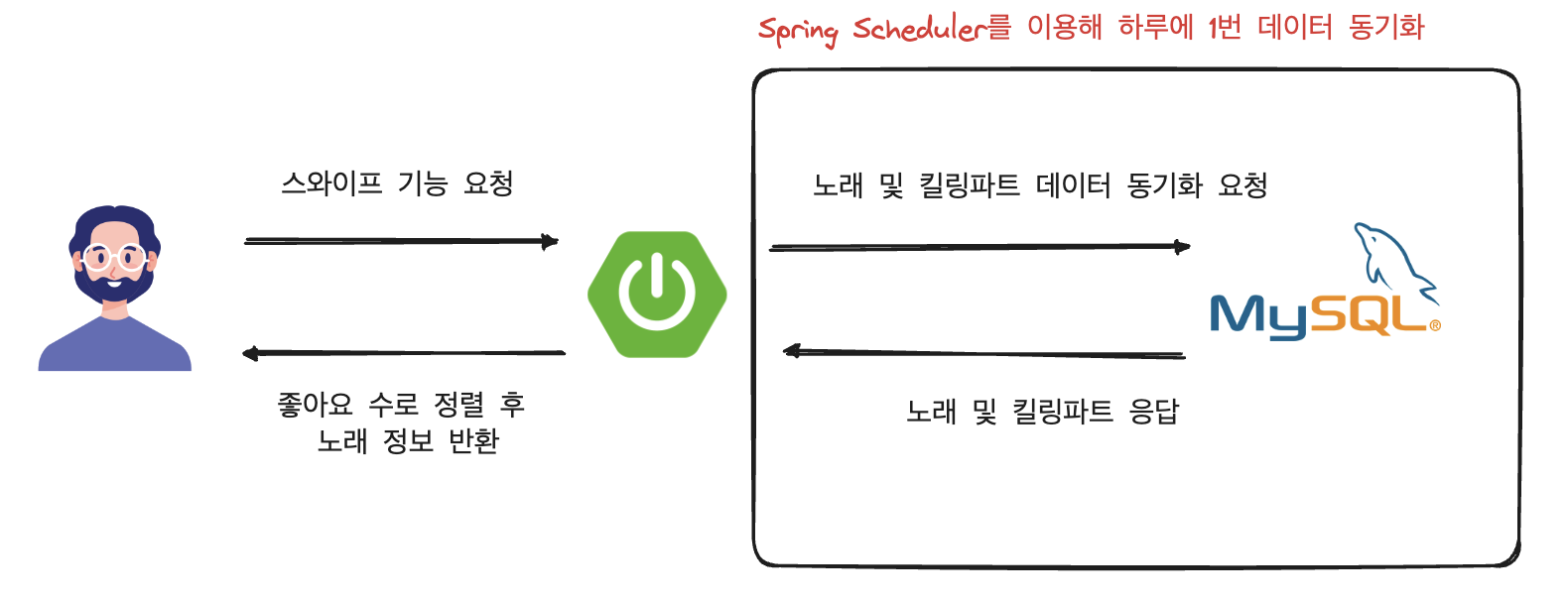
메모리 데이터 갱신의 경우 위의 그림과 같이 Spring Schedule를 이용해 하루의 1번 DB에 요청을 보내 데이터를 최신화하도록 구성했습니다.
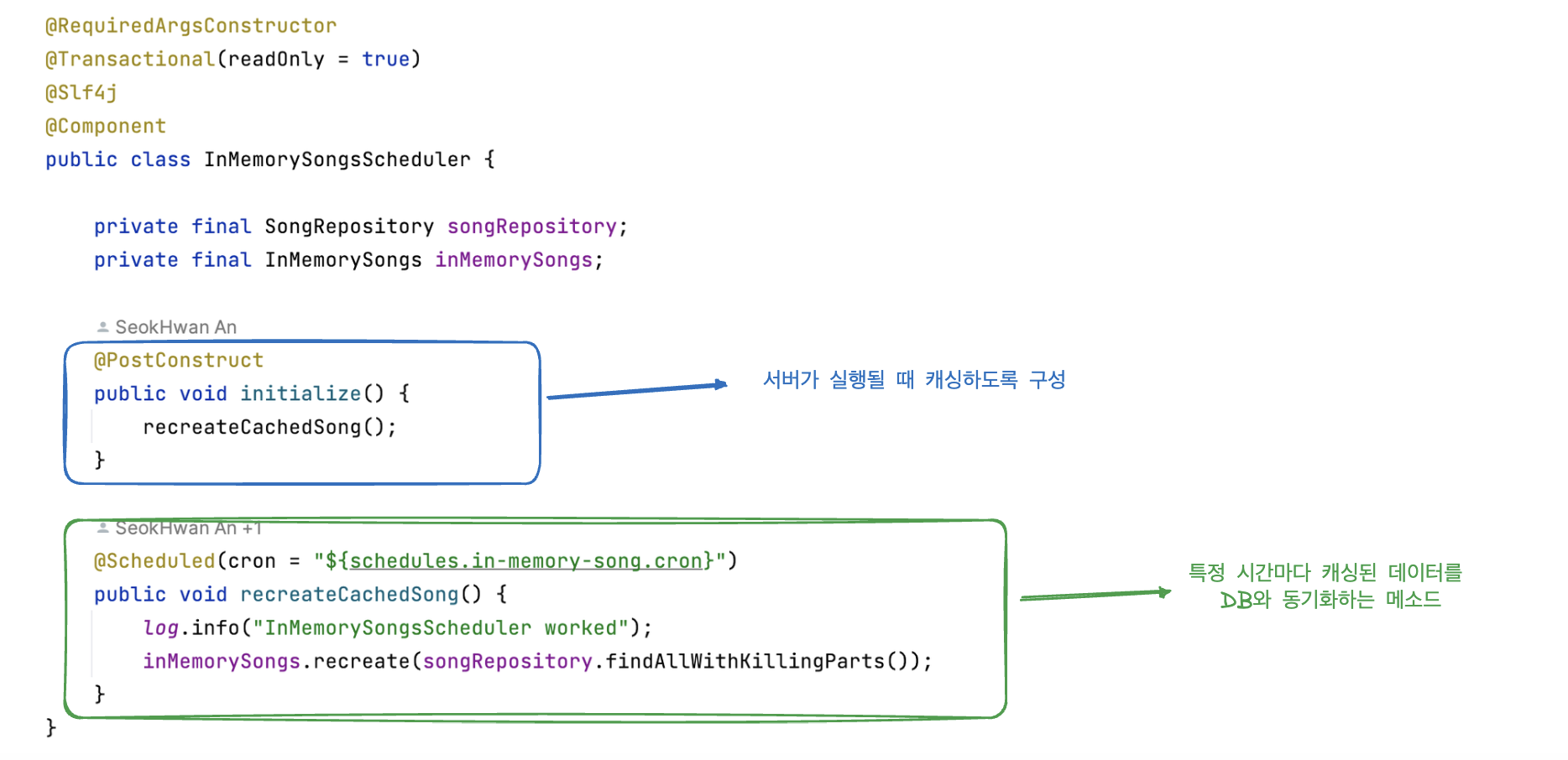
InMemorySongs.java

메모리는 LinkedHashMap 자료구조를 이용하며 처음 데이터를 캐싱할 때 미리 정렬해 이후 사용자 요청에서는 정렬 과정이 중복으로 이루어지지 않도록 구성했습니다.
InMemorySongsScheduler.java
위와 같이 DB에서 정렬하던 로직을 Application으로 옮긴 후 같은 조건에서 부하테스트 했을 때 결과입니다.
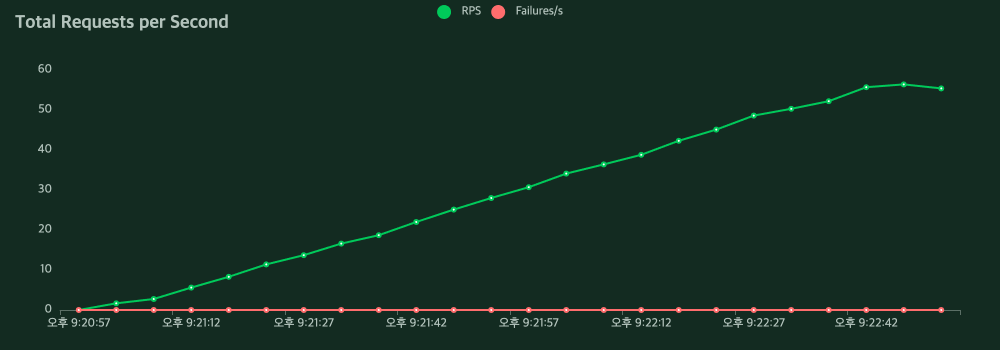
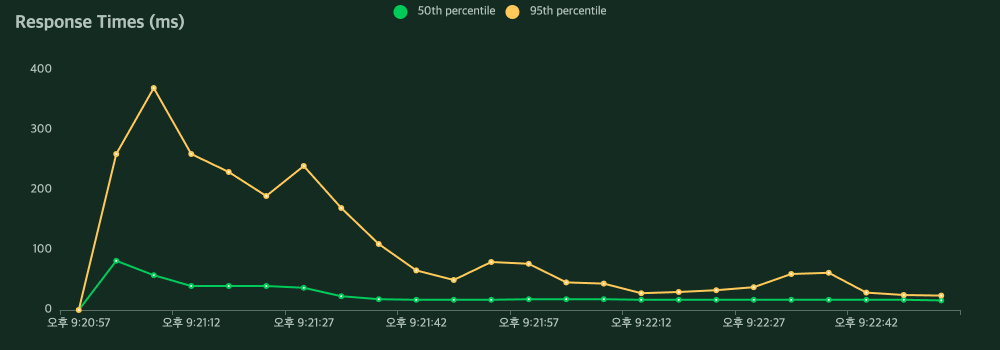
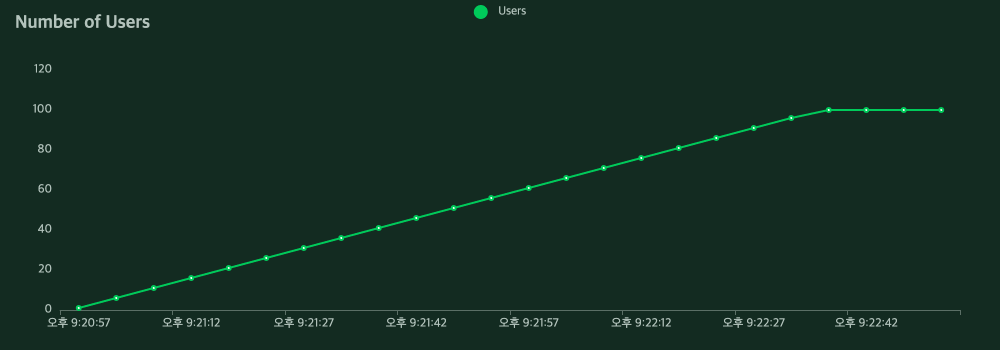
평균 응답시간이 24,642ms에서 21ms로 약 1000% 개선되었고 실패하던 요청도 없어졌습니다.
