HTML 파싱 속도를 높여야 합니다.
자바로는 도저히 서비스 불가능한 속도가 나오기 때문에... 이전 검색에서 찾은 자료에서 압도적으로 빠른 성능이 나온 c언어의 libxml2를 이용해 보기로 하였습니다. 보아하니 비교적 최근까지 업데이트가 있었습니다. 2022년 5월이 마지막 업데이트인걸 보면 말이죠!
사용해보자
저는 m2 맥에서 진행했습니다!
설치
우선 파일을 다운해줍니다. https://download.gnome.org/sources/libxml2/ 이 사이트에서 저는 최신 버전을 다운했습니다. 이후, 압축을 해제하고
./configure
make
sudo make install
을 차례로 입력하여 설치해줍니다. 이러면 기본 세팅 완료!
코드
간단하게 URL을 입력받고, 입력받은 URL에서 span 태그 내용들을 출력하는 코드를 작성해보았습니다.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <libxml/HTMLparser.h>
#include <libxml/xpath.h>
void crawlSpanContent(const char *url) {
xmlInitParser();
LIBXML_TEST_VERSION;
xmlDocPtr doc = htmlReadFile(url, NULL, HTML_PARSE_NOBLANKS | HTML_PARSE_NOERROR | HTML_PARSE_NOWARNING);
if (doc == NULL) {
fprintf(stderr, "문서를 읽을 수 없습니다.\n");
return;
}
xmlXPathContextPtr context = xmlXPathNewContext(doc);
if (context == NULL) {
fprintf(stderr, "XPath 컨텍스트를 생성할 수 없습니다.\n");
xmlFreeDoc(doc);
return;
}
xmlXPathObjectPtr result = xmlXPathEvalExpression(BAD_CAST("//span"), context);
if (result == NULL) {
fprintf(stderr, "XPath 표현식을 평가할 수 없습니다.\n");
xmlXPathFreeContext(context);
xmlFreeDoc(doc);
return;
}
if (xmlXPathNodeSetGetLength(result->nodesetval) > 0) {
for (int i = 0; i < xmlXPathNodeSetGetLength(result->nodesetval); i++) {
xmlNodePtr node = xmlXPathNodeSetItem(result->nodesetval, i);
if (node->children != NULL && node->children->type == XML_TEXT_NODE) {
printf("content: %s\n", xmlNodeGetContent(node));
}
}
} else {
printf("태그를 찾을 수 없습니다.\n");
}
xmlXPathFreeObject(result);
xmlXPathFreeContext(context);
xmlFreeDoc(doc);
xmlCleanupParser();
}
int main(int argc, char** argv) {
if (argc != 2) {
fprintf(stderr, "URL 입력이 없습니다.");
return 1;
}
const char* url = argv[1];
printf("url = %s\n", url);
crawlSpanContent(url);
return 0;
}
이 후 컴파일을 진행하면 끝 !!
clang -o parser parser.c -I/usr/local/include/libxml2 -lxml2
./parser http://localhost:8080/main
을 실행하면 !! 참고로 main 안에는
<div>
<div>
<span>asdfasdf</span>
</div>
</div>이런 아주 기본적인 태그를 넣어보았다! 결과는
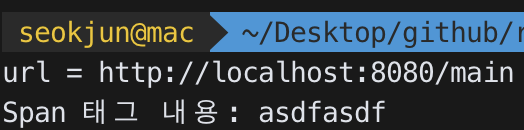
뚜둔 !! span 태그 안에 있는 내용이 잘 출력되었다. 하지만 치명적인 단점이 존재했으니 ... 바로 ...... https 주소는 파싱이 불가능하다 ...!! 이걸 모른채 ..... 기나긴 검색의 결과 아주 오래 전에 올라온 스택오버플로우 질문글을 보고 알았고 ..... 네이버 블로그는 전부 https를 사용하기 때문에 ... 이 라이브러리를 사용할 수 없다고 .....^^
대안은
다른 라이브러리를 찾아보고 있는데, htmlcxx도 있긴 한데 c언어 관련 자료들이 최소 10년은 지난 자료들이 태반이고 양도 적어서 쉽지 않다 ...
그래서 생각해본 대안은
- 파이썬
- Go언어
- 자바에서 쓰레드로 병렬처리
우선은 자바에서 병렬처리로 속도를 개선시켜봐야 겠다. 이전에 각각의 포스트별 파싱 속도를 스쳐 지나가며 측정해본 것 같은데 아마 개당 1초는 넘기지 않았던 것 같다. (그래도 여전히 긴 시간이지만) 하지만 병렬처리는 단일 처리를 자바에서 할지 다른 언어로 대체할지와는 상관없이 필요하다고 생각되는 부분이라 내일은 병렬처리에 집중해야겠다!
TODO List
오늘부턴 TODO List를 적어볼까 한다!
- 자바 병렬처리
- 파이썬 라이브러리 속도 측정
- Go 언어 HTML 파싱 라이브러리 탐색
- 필터링 로직 구현
- 필터링 전체 시간 테스트
- 프론트 디자인 구상
- 엔티티 설계 및 ERD 작성
