데이터마이닝
정말 재미있다! 아니 어떻게 이렇게 딱 맞는 주제가 등장하지? 안그래도 자연어 전처리(NLP)를 찾아보면서 도저히 갈피를 잡지 못하고 있었는데 수업시간에 두둥 등장. 바로바로 RNN, BERT 등등 자연어 처리를 위한 여러 모델이 등장한닷! 하지만 교수님이 수업하시지 않고 .. 조교님들이 완전 살짝만 빠르게 수업하셔서 많이 아쉬운 .... 아쉬워 ............
RNN
Multi-Layer Perceptron은 입력 데이터가 스칼라인 반면, RNN은 입력 데이터가 시퀀스 데이터다!
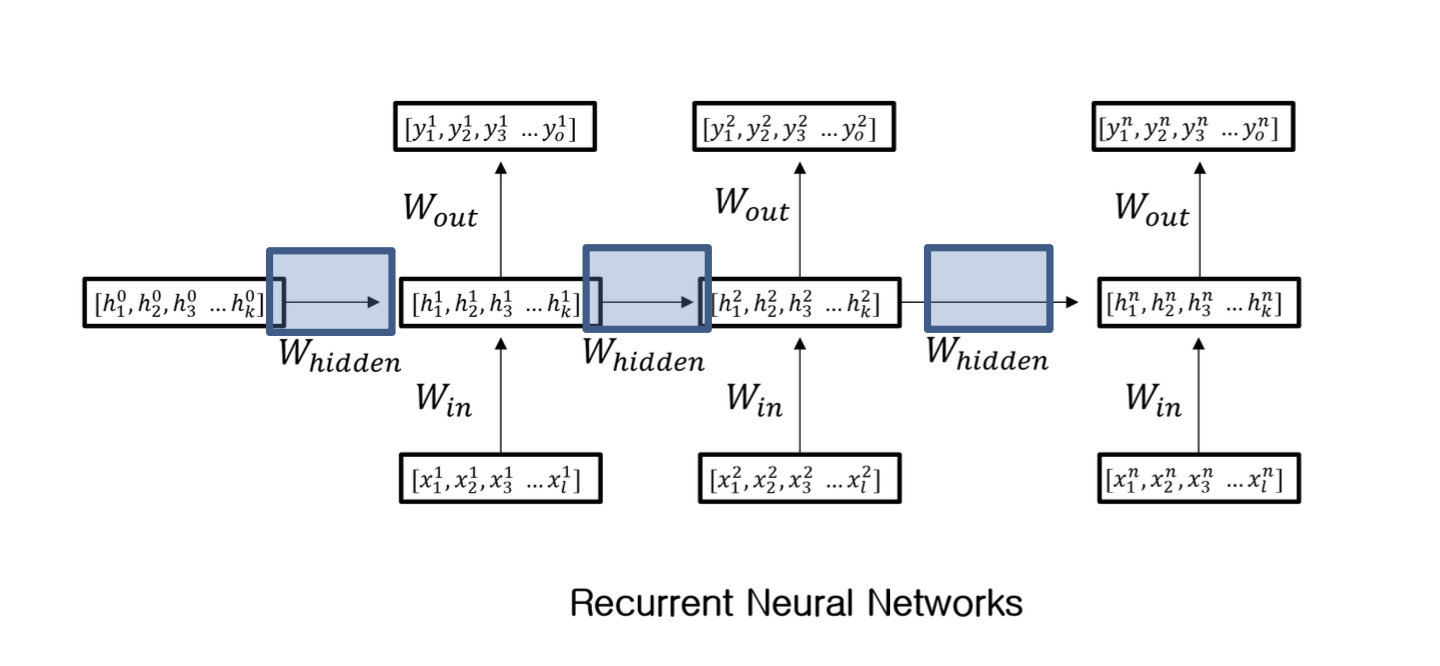
이렇게 순서에 따라 hidden layer의 가중치를 계산하고 다음 데이터에 전달해서 사용하는 ... Multi-Layer Perceptron에서는 hidden layer에서 각 노드끼리는 공유하지 않았는데, 여기서는 연결된다!
Feature Representation
내가 찾던 부분!! 시퀀스 데이터를 딥러닝을 위한 데이터로 만들기 위해 수치화하는 과정이다. 내가 생각한 부분들이 꽤 있었는데!
- Tokenization : 텍스트를 토큰 혹은 단어로 쪼개기
- Cleaning : 불필요한 데이터, 노이즈 등을 제거하기
- Stop Word Removal : 'the', 'is'와 같이 큰 의미를 가지지 않는 단어 제거하기
이후 수치화할 때 여러 기법이 있는데
- One-Hot Encoding : 완전 비효율적
- Bag of Words : 단어 등장 횟수를 count
- Word2vec
- CBOW : 다른 단어에 얼마나 영향을 주는지?를 표현 잘한다!
- Skip-gram : 다른 단어와 얼마나 연관성 있는지를 체크하는 느낌
그리고 등장하는 것이
Attention Mechanism
- 출력 시퀀스의 각 단계별로 입력 데이터의 다른 부분에 초점을 둘 수 있게 하는 메커니즘
- Seq2Seq의 단점인 병목현상과 long-term dependency 문제를 해결할 수 있다!
그리고 등장하는 것은 바로
Auto Encoder
효과적인 데이터 표현을 학습하기 위한 인공 신경망! 3가지로 구성된다
- Encoder
- Latent Space
- Decoder
인코더로 인코딩하면 Latent Space에 인코딩된 데이터가 나오고, 이 데이터를 디코더로 디코딩하여 원래의 input이 나오도록 중간 가중치를 학습하는 모델!
근데 여기서 또 등장하는게
Seq2Seq Architecture
정말 끝이 없다 .... 아무튼 인코더-디코더 구조인데 입력 시퀀스 데이터를 출력 시퀀스 데이터로 변환해준다. 여기서는
- Encoder
- Context Vector
- Decoder
3가지가 있다고! 그리고 디코더에서 문장의 시작과 끝을 알리는 토큰 BOS, EOS가 등장한다!
그럼 auto-encoder와 다른점이 뭘까
차이점
Auto-Encoder는
- 입력을 재구성하기 위한 데이터의 압축된 표현!을 학습한달까
- 인코더는 입력 데이터를 저차원으로 압축, 디코더는 압축된 데이터를 입력 데이터로 재구성하는 과정이다
- 따라서 입력과 출력이 같은 데이터이고
- 입출력 데이터의 길이도 모두 동일!
반면 Seq2Seq는
- 하나의 시퀀스를 다른 시퀀스로 변환하도록 설계되었다
- 인코더는 입력 데이터를 컨텍스트 벡터로 변환하고, 디코더는 컨텍스트 벡터로 새로운 시퀀스를 생성한다
- 입출력의 길이가 다를 수 있고, 동적으로 처리한다
- 이런 점에서, NLP에 더 적합하다고 !?
Seq2Seq의 한계
- 입력 데이터가 길고 복잡하면 컨텍스트 벡터로 압축하는 것이 어렵고, 필요한 정보를 다 유지하지 못할 수도 있다!
- information bottleneck, long-term dependency 문제 발생한다
- 그래서 Attention Mechanism을 이용하여 이를 해결!
사실 Attention Mechanism을 RNN의 Seq2Seq에 적용하는 과정에서 key, value, query가 등장하는데 이걸 잘 이해하지 못했다 ...
Transformer Architecture
시퀀스 데이터 처리를 위해 RNN 계층 없이 attention 메커니즘만 사용하는 신경망 아키텍쳐. 자연어 처리를 위한 아키텍쳐 중 지배적이라고 ..!
입력 시퀀스의 순서에 대한 개념이 없어서, positional encoding으로 모델에게 각 토큰의 위치 정보를 전달한다고 한다!
요런 식으로 !?!?
이때 인코딩 함수를 cos, sin을 번갈아가면서 써야 데이터가 겹칠 일이 없다고 한다 ..!!
Self Attention
앞서 말했듯이 트랜스포머 아키텍쳐는 RNN 계층이 없기 때문에 attention 메커니즘을 사용해서 시퀀스 내의 위치 정보를 학습한다!
여러 종류가 있는데
- Scaled Dot-Product Attention
- Multi-Head Attention
여기도 잘 이해를 못했다 ... NLP 너무 어려워 ....
그 외에도 Position-wised Feed-Forward Network가 등장하는데 이것도 잘 이해를 못해서 .... 교수님 ...수업 다시 해주세요 ....... 교수님의 설명이 필요합니다 .............
그리고 등장하는 핵심 개념
Transformer
attention 메커니즘을 이용해서 맥락과 이해?를 학습하는 신경망!
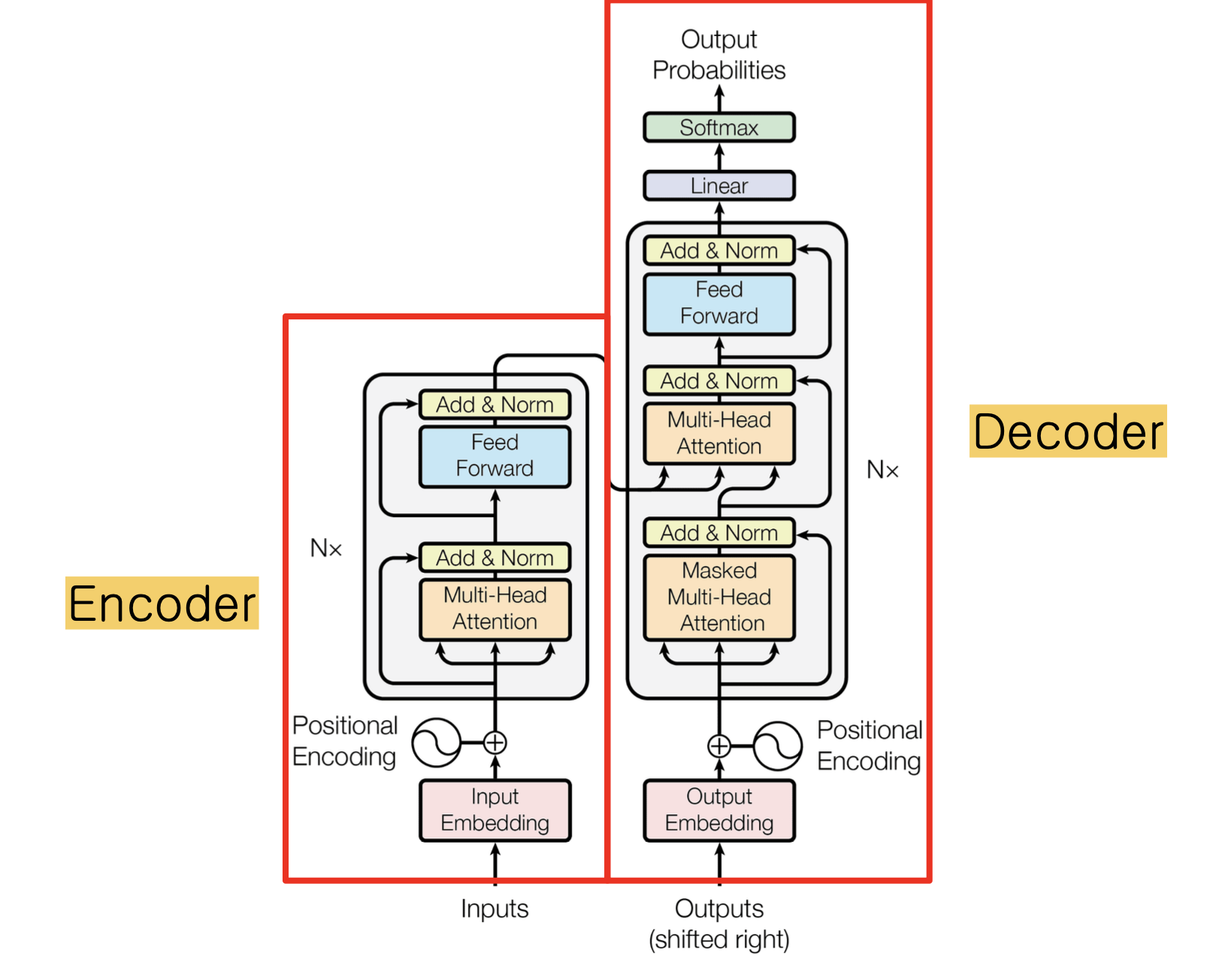
이렇게 인코더, 디코더로 나눌 수 있는데 같이 쓰기 보다는 인코더만, 디코더만 쓰는 경우가 많다고 한다.
Encoder
인코더는 positional encoding과 multi-head attention을 이용해서 입력 시퀀스 데이터를 컨텍스트 벡터로 인코딩한다.
약간 multi-head attention으로 컨텍스트 정보를 만들고 feed-forward network에서 생성된 컨텍스트 정보를 병합하는 느낌
Decoder
인코딩된 입력 데이터를 가지고 새로운 시퀀스를 생성한다.
디코더의 사진을 잘 보면
masked multi-head attention으로 인코딩된 입력 데이터 중에서 뽑아내고, 뽑아낸 인코딩 데이터와 전체 인코딩 데이터를 이용해서 multi-head attention을 다시 수행하고 똑같이 feed-forward network에서 병합하는 느낌이랄까
BERT, GPT-4
앞서 말했듯 트랜스포머는 인코더와 디코더를 따로 많이 쓴다고 했는데
Encoder
- pre-training & fine-tuning 모델에서 많이 쓰인다
- BERT
Decoder
- 다양한 분야에서 생성형 모델에 많이 쓰인다
- GPT-4
여기서 관심을 가져야할 부분은 BERT
BERT
- 언어 처리의 pre-training을 위한 트랜스포머-인코더 기반 모델
Input Representation
3가지 임베딩의 합으로 표현된다!
- Token
- Segment
- Position
Token Embedding
word-piece embedding을 이용해서 word를 sub-word로 분리한다. 예를 들어 playing = play + ing 이렇게!
Segment Embedding
문장 사이에 SEP 라는 토큰을 삽입해서 문장을 나눈다
Position Encoder
단어 위치 정보를 추가하는 인코더!
Task
이런 BERT는 2가지 일을 수행한다
- MLM : Masked Language Model
- NSP : Next Sentence Prediction
아무튼 이렇게 BERT에 대한 소개가 끝! 났다 ...... 조교님이 여기서 더 설명하시진 않았다 ..ㅜㅜ 간단한 예제만이라도 보여주셨으면 ... 써보는데 정말 도음 많이 될 것 같았지만 아쉽게도 없고 ...
그래서 이젠 BERT에 대해 찾아보고 이를 적용해서 딥러닝 모델 만드는 법을 찾아봐야겠다! 그리고 리뷰 데이터들 모아서 학습시켜볼 예정이다.
근데 ....시험 공부에 ... 인공지능 공부에 .... 할게 넘 많아 ........ 그 와중에 과제는 또 2개 이상 나올 예정.... 추가로 텀프 2개 ..... 나 죽어 진짜 .....
